
تحليل البيانات الاستكشافية في بايثون: ما الذي تحتاج إلى معرفته؟
نشرت: 2021-03-12يعد تحليل البيانات الاستكشافية (EDA) ممارسة شائعة ومهمة جدًا يتبعها جميع علماء البيانات. إنها عملية النظر إلى جداول وجداول البيانات من زوايا مختلفة لفهمها بشكل كامل. يساعدنا اكتساب فهم جيد للبيانات على تنظيفها وتلخيصها ، مما يبرز الرؤى والاتجاهات التي كانت غير واضحة لولا ذلك.
ليس لدى أكاديمية الإمارات الدبلوماسية مجموعة من القواعد الصارمة التي يجب اتباعها كما هو الحال في "تحليل البيانات" ، على سبيل المثال. يميل الأشخاص الجدد في هذا المجال دائمًا إلى الخلط بين المصطلحين ، اللذين يتشابهان في الغالب ولكنهما مختلفان في غرضهما. على عكس EDA ، فإن تحليل البيانات يميل أكثر نحو تنفيذ الاحتمالات والأساليب الإحصائية للكشف عن الحقائق والعلاقات بين المتغيرات المختلفة.
بالعودة ، لا توجد طريقة صحيحة أو خاطئة لأداء EDA. يختلف من شخص لآخر ، ومع ذلك ، هناك بعض الإرشادات الرئيسية التي يتم اتباعها بشكل شائع والتي يتم سردها أدناه.
- معالجة القيم المفقودة: يمكن رؤية القيم الخالية عندما لا تكون جميع البيانات متاحة أو مسجلة أثناء التجميع.
- إزالة البيانات المكررة: من المهم منع أي تحيز أو تحيز ناتج أثناء تدريب خوارزمية التعلم الآلي باستخدام سجلات البيانات المتكررة
- معالجة القيم المتطرفة: القيم المتطرفة هي سجلات تختلف اختلافًا جذريًا عن بقية البيانات ولا تتبع الاتجاه. يمكن أن تنشأ بسبب بعض الاستثناءات أو عدم الدقة أثناء جمع البيانات
- التحجيم والتسوية: يتم ذلك فقط لمتغيرات البيانات الرقمية. في معظم الأحيان ، تختلف المتغيرات اختلافًا كبيرًا في مداها ومقياسها مما يجعل من الصعب مقارنتها وإيجاد الارتباطات.
- التحليل أحادي المتغير وثنائي المتغير: عادة ما يتم إجراء التحليل أحادي المتغير من خلال رؤية كيفية تأثير متغير واحد على المتغير المستهدف. يتم إجراء التحليل ثنائي المتغير بين أي متغيرين ، يمكن أن يكون إما عدديًا أو فئويًا أو كليهما.
سننظر في كيفية تنفيذ بعضها باستخدام مجموعة بيانات مشهورة جدًا "مخاطر الائتمان الافتراضية" المتاحة على Kaggle هنا . تحتوي البيانات على معلومات حول طالب القرض وقت تقديم طلب القرض. يحتوي على نوعين من السيناريوهات:
- العميل الذي يواجه صعوبات في السداد : تأخر في السداد أكثر من X يوم
على دفعة واحدة على الأقل من أقساط القرض الأولى على أساس "ص" في عينتنا ،
- جميع الحالات الأخرى : جميع الحالات الأخرى التي يتم فيها سداد الدفعة في موعدها.
سنعمل فقط على ملفات بيانات التطبيق من أجل هذه المقالة.
الموضوعات ذات الصلة: أفكار مشروع Python وموضوعات للمبتدئين
جدول المحتويات
النظر في البيانات
app_data = pd.read_csv ("application_data.csv")
app_data.info ()
بعد قراءة بيانات التطبيق ، نستخدم وظيفة info () للحصول على لمحة موجزة عن البيانات التي سنتعامل معها. يخبرنا الناتج أدناه أن لدينا حوالي 300000 سجل قرض مع 122 متغيرًا. من بين هؤلاء ، هناك 16 متغيرًا فئويًا والباقي رقمي.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 إدخالات ، من 0 إلى 307510
الأعمدة: 122 إدخالاً ، SK_ID_CURR إلى AMT_REQ_CREDIT_BUREAU_YEAR
dtypes: float64 (65) ، int64 (41) ، object (16)
استخدام الذاكرة: 286.2 ميجابايت
من الممارسات الجيدة دائمًا التعامل مع البيانات الرقمية والفئوية وتحليلها بشكل منفصل.
categorical = app_data.select_dtypes (include = object) .columns
app_data [الفئوية]. تنطبق (pd.Series.nunique ، المحور = 0)
بالنظر فقط إلى الميزات الفئوية أدناه ، نرى أن معظمها يحتوي على فئات قليلة فقط مما يسهل تحليلها باستخدام مخططات بسيطة.
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
نوع dtype: int64
الآن بالنسبة إلى الميزات العددية ، تعطينا طريقة description () إحصاءات بياناتنا:
numer = app_data.describe ()
عددي = عدد أعمدة
عدد
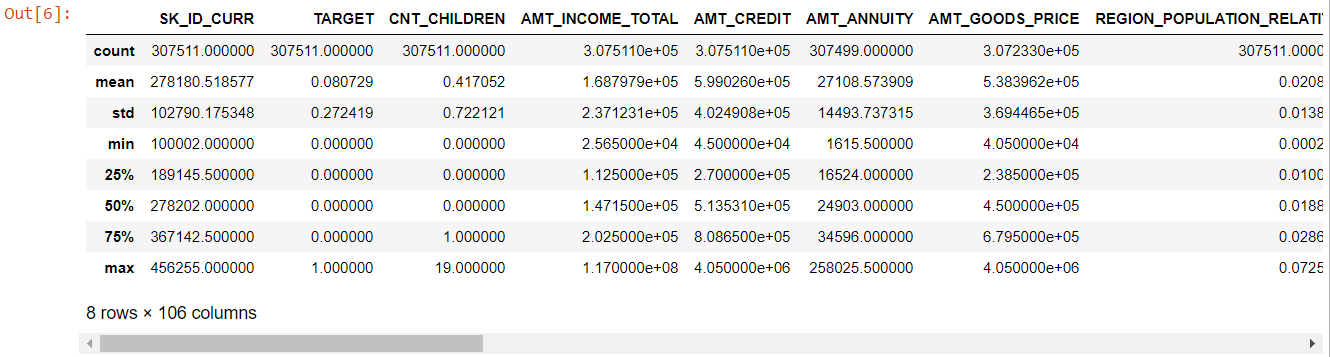
بالنظر إلى الجدول بأكمله ، يتضح أن:
- أيام_الولادة سلبية: عمر مقدم الطلب (بالأيام) بالنسبة ليوم تقديم الطلب
- days_employed لديها قيم متطرفة (الحد الأقصى للقيمة حوالي 100 سنة) (635243)
- amt_annuity- يعني أصغر بكثير من الحد الأقصى للقيمة
حتى الآن نحن نعرف الميزات التي يجب تحليلها بشكل أكبر.

بيانات مفقودة
يمكننا عمل مخطط نقطي لجميع الميزات التي تحتوي على قيم مفقودة من خلال رسم النسبة المئوية للبيانات المفقودة على طول المحور ص.
مفقود = pd.DataFrame ((app_data.isnull (). sum ()) * 100 / app_data.shape [0]). reset_index ()
شكل plt (حجم التين = (16،5))
ax = sns.pointplot ('index' ، 0 ، البيانات = مفقود)
plt.xticks (تناوب = 90 ، حجم الخط = 7)
plt.title ("النسبة المئوية للقيم المفقودة")
plt.ylabel ("PERCENTAGE")
plt.show ()
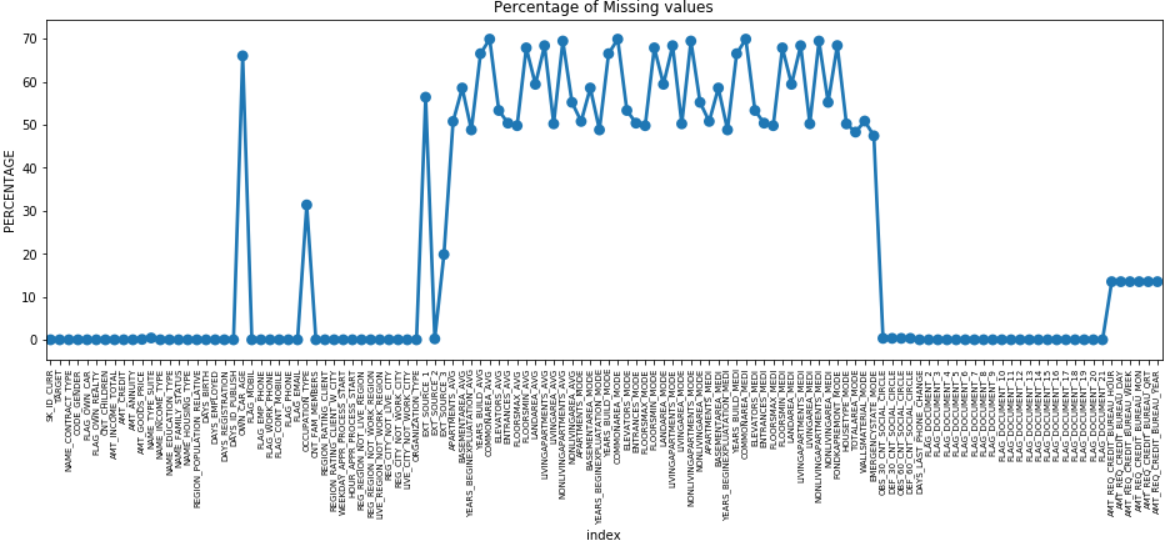
تحتوي العديد من الأعمدة على الكثير من البيانات المفقودة (30-70٪) ، وبعضها يحتوي على القليل من البيانات المفقودة (13-19٪) والعديد من الأعمدة أيضًا لا تحتوي على بيانات مفقودة على الإطلاق. ليس من الضروري حقًا تعديل مجموعة البيانات عندما يكون عليك فقط أداء EDA. ومع ذلك ، للمضي قدمًا في المعالجة المسبقة للبيانات ، يجب أن نعرف كيفية التعامل مع القيم المفقودة.
بالنسبة للمعالم ذات القيم المفقودة أقل ، يمكننا استخدام الانحدار للتنبؤ بالقيم المفقودة أو التعبئة بمتوسط القيم الموجودة ، اعتمادًا على الميزة. وبالنسبة إلى الميزات التي تحتوي على عدد كبير جدًا من القيم المفقودة ، فمن الأفضل إسقاط هذه الأعمدة لأنها تعطي رؤية أقل عن التحليل.
عدم توازن البيانات
في مجموعة البيانات هذه ، يتم تحديد المتعثرين عن سداد القروض باستخدام المتغير الثنائي "الهدف".
100 * بيانات التطبيق ['TARGET']. value_counts () / len (app_data ['TARGET'])
0 91.927118
1 8.072882
الاسم: TARGET ، النوع dtype: float64
نرى أن البيانات غير متوازنة بدرجة كبيرة بنسبة 92: 8. تم سداد معظم القروض في الوقت المحدد (الهدف = 0). لذلك كلما كان هناك مثل هذا الخلل الهائل في التوازن ، فمن الأفضل أخذ الميزات ومقارنتها بالمتغير المستهدف (التحليل المستهدف) لتحديد الفئات في تلك الميزات التي تميل إلى التخلف عن سداد القروض أكثر من غيرها.
فيما يلي بعض الأمثلة على الرسوم البيانية التي يمكن إجراؤها باستخدام مكتبة seaborn للبيثون والوظائف البسيطة التي يحددها المستخدم.
جنس
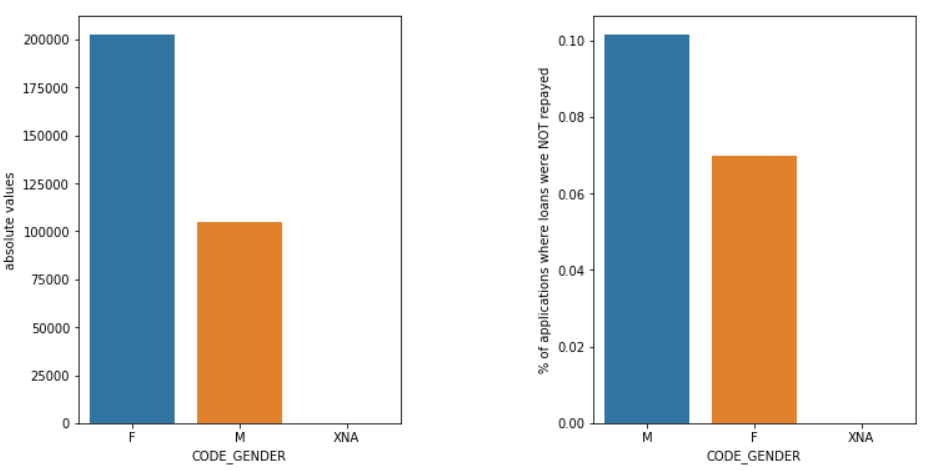
الذكور (M) لديهم فرصة أكبر للتخلف عن السداد مقارنة بالإناث (F) ، على الرغم من أن عدد المتقدمات من الإناث يزيد بمقدار الضعف تقريبًا. لذا فإن النساء أكثر موثوقية من الرجال في سداد قروضهن.
نوع التعليم
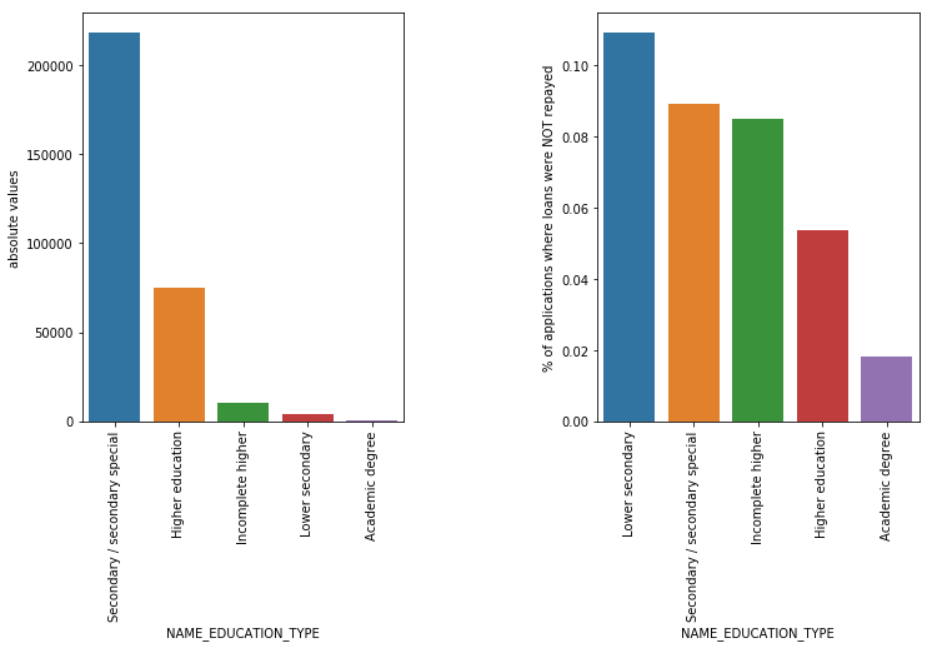
على الرغم من أن معظم قروض الطلاب مخصصة لتعليمهم الثانوي أو التعليم العالي ، إلا أن قروض التعليم الثانوي هي الأكثر خطورة بالنسبة للشركة تليها قروض التعليم الثانوي.
اقرأ أيضًا: مهنة في علوم البيانات
خاتمة
يتم إجراء مثل هذا النوع من التحليل الموضح أعلاه بشكل كبير في تحليلات المخاطر في الخدمات المصرفية والمالية. بهذه الطريقة يمكن استخدام أرشيفات البيانات لتقليل مخاطر خسارة الأموال أثناء إقراض العملاء. نطاق أكاديمية الإمارات الدبلوماسية في جميع القطاعات الأخرى لا حصر له ويجب استخدامه على نطاق واسع.
إذا كنت مهتمًا بالتعرف على علوم البيانات ، فراجع IIIT-B & upGrad's Executive PG في علوم البيانات الذي تم إنشاؤه للمهنيين العاملين ويقدم أكثر من 10 دراسات حالة ومشاريع ، وورش عمل عملية عملية ، وإرشاد مع خبراء الصناعة ، 1- على - 1 مع موجهين في الصناعة ، وأكثر من 400 ساعة من التعلم والمساعدة في العمل مع الشركات الكبرى.
يعتبر تحليل البيانات الاستكشافية هو المستوى الأولي عند بدء نمذجة بياناتك. يعد هذا أسلوبًا ثاقبًا تمامًا لتحليل أفضل الممارسات لنمذجة بياناتك. ستكون قادرًا على استخراج المؤامرات المرئية والرسوم البيانية والتقارير من البيانات للحصول على فهم كامل لها. تتم إحالة القيم المتطرفة إلى الحالات الشاذة أو الاختلافات الطفيفة في بياناتك. يمكن أن يحدث أثناء جمع البيانات. هناك 4 طرق يمكننا من خلالها اكتشاف حالة خارجية في مجموعة البيانات. هذه الطرق هي كما يلي: على عكس تحليل البيانات ، لا توجد قواعد وأنظمة صارمة وسريعة يجب اتباعها من أجل جمعية الإمارات للغوص. لا يمكن للمرء أن يقول أن هذه هي الطريقة الصحيحة أو أن هذه هي الطريقة الخاطئة لأداء EDA. غالبًا ما يُساء فهم المبتدئين ويختلط عليهم الأمر بين تحليل البيانات وتحليل البيانات.لماذا يلزم تحليل البيانات الاستكشافية (EDA)؟
يتضمن EDA خطوات معينة لتحليل البيانات بالكامل بما في ذلك استخلاص النتائج الإحصائية ، والعثور على قيم البيانات المفقودة ، ومعالجة إدخالات البيانات الخاطئة ، وأخيراً استنتاج المؤامرات والرسوم البيانية المختلفة.
الهدف الأساسي من هذا التحليل هو التأكد من أن مجموعة البيانات التي تستخدمها مناسبة لبدء تطبيق خوارزميات النمذجة. هذا هو السبب في أن هذه هي الخطوة الأولى التي يجب أن تقوم بها على بياناتك قبل الانتقال إلى مرحلة النمذجة. ما هي القيم المتطرفة وكيفية التعامل معها؟
1. Boxplot - Boxplot هي طريقة لاكتشاف الظواهر الخارجية حيث نقوم بفصل البيانات من خلال أرباعها.
2. مخطط مبعثر - يعرض مخطط مبعثر بيانات متغيرين في شكل مجموعة من النقاط المميزة على المستوى الديكارتي. تمثل قيمة أحد المتغيرات المحور الأفقي (x-ais) وتمثل قيمة المتغير الآخر المحور الرأسي (المحور y).
3. Z-Score - أثناء حساب Z-Score ، نبحث عن النقاط البعيدة عن المركز ونعتبرها قيمًا متطرفة.
4. النطاق الرباعي (IQR) - النطاق الرباعي أو IQR هو الفرق بين الربعين العلوي والسفلي أو الربعين الخامس والسبعين والخامس والعشرين ، وغالبًا ما يشار إليه بالتشتت الإحصائي. ما هي المبادئ التوجيهية لأداء EDA؟
ومع ذلك ، هناك بعض الإرشادات التي يتم ممارستها بشكل شائع:
1. معالجة القيم المفقودة
2. إزالة البيانات المكررة
3. التعامل مع القيم المتطرفة
4. التحجيم والتطبيع
5. التحليل أحادي المتغير وثنائي المتغير