
ما هو تحليل البيانات الاستكشافية في بايثون؟ تعلم من سكراتش
نشرت: 2021-03-04باختصار ، يشتمل تحليل البيانات الاستكشافية أو EDA ، على ما يقرب من 70 ٪ من مشروع علوم البيانات. EDA هي عملية استكشاف البيانات باستخدام أدوات التحليل المختلفة للحصول على الإحصائيات الاستنتاجية من البيانات. تتم هذه الاستكشافات إما من خلال رؤية أرقام بسيطة أو عن طريق رسم الرسوم البيانية والمخططات من أنواع مختلفة.
كل رسم بياني أو مخطط يصور قصة مختلفة وزاوية لنفس البيانات. بالنسبة لمعظم تحليل البيانات وجزء التنظيف ، فإن Pandas هي الأداة الأكثر استخدامًا. بالنسبة إلى التصورات والرسوم البيانية / الرسوم البيانية ، يتم استخدام مكتبات التخطيط مثل Matplotlib و Seaborn و Plotly.
EDA ضروري للغاية ليتم تنفيذه لأنه يجعل البيانات تعترف لك. يعرف عالم البيانات الذي يقوم بعمل جيد جدًا في EDA الكثير عن البيانات ، وبالتالي فإن النموذج الذي سيقومون ببنائه سيكون تلقائيًا أفضل من عالم البيانات الذي لا يقوم بعمل EDA جيدًا.
بنهاية هذا البرنامج التعليمي ، ستعرف ما يلي:
- التحقق من النظرة العامة الأساسية للبيانات
- التحقق من الإحصائيات الوصفية للبيانات
- معالجة أسماء الأعمدة وأنواع البيانات
- معالجة القيم المفقودة والصفوف المكررة
- تحليل ثنائي المتغير
جدول المحتويات
نظرة عامة أساسية على البيانات
سنستخدم مجموعة بيانات السيارات لهذا البرنامج التعليمي الذي يمكن تنزيله من Kaggle. تتمثل الخطوة الأولى لأي مجموعة بيانات تقريبًا في استيرادها والتحقق من النظرة العامة الأساسية الخاصة بها - شكلها وأعمدتها وأنواع أعمدةها وأعلى 5 صفوف وما إلى ذلك. تمنحك هذه الخطوة فكرة سريعة عن البيانات التي ستتعامل معها. دعونا نرى كيفية القيام بذلك في بايثون.
| # استيراد المكتبات المطلوبة استيراد الباندا كما pd استيراد numpy كـ np استيراد seaborn as sns #visualisation استيراد matplotlib.pyplot كـ plt #visualisation ٪ matplotlib مضمنة sns.set (color_codes = True ) |
رأس البيانات والذيل
| data = pd.read_csv ( “path / dataset.csv” ) # تحقق من أعلى 5 صفوف من إطار البيانات data.head () |
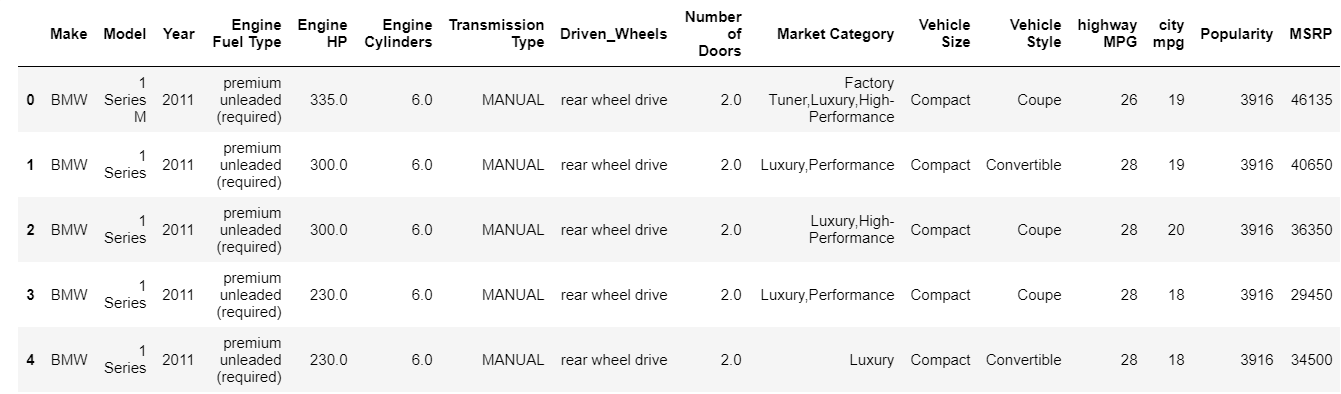
تقوم وظيفة الرأس بطباعة أعلى 5 فهارس لإطار البيانات افتراضيًا. يمكنك أيضًا تحديد عدد الفهارس العليا التي تحتاج إلى رؤيتها لتجاوز هذه القيمة إلى الرأس. تمنحنا طباعة الرأس على الفور نظرة سريعة على نوع البيانات التي لدينا ونوع الميزات الموجودة والقيم التي تحتوي عليها. بالطبع ، هذا لا يخبر القصة الكاملة عن البيانات ، لكنه يمنحك نظرة سريعة على البيانات. يمكنك بالمثل طباعة الجزء السفلي من إطار البيانات باستخدام وظيفة الذيل.
| # طباعة آخر 10 صفوف من إطار البيانات data.tail ( 10 ) |
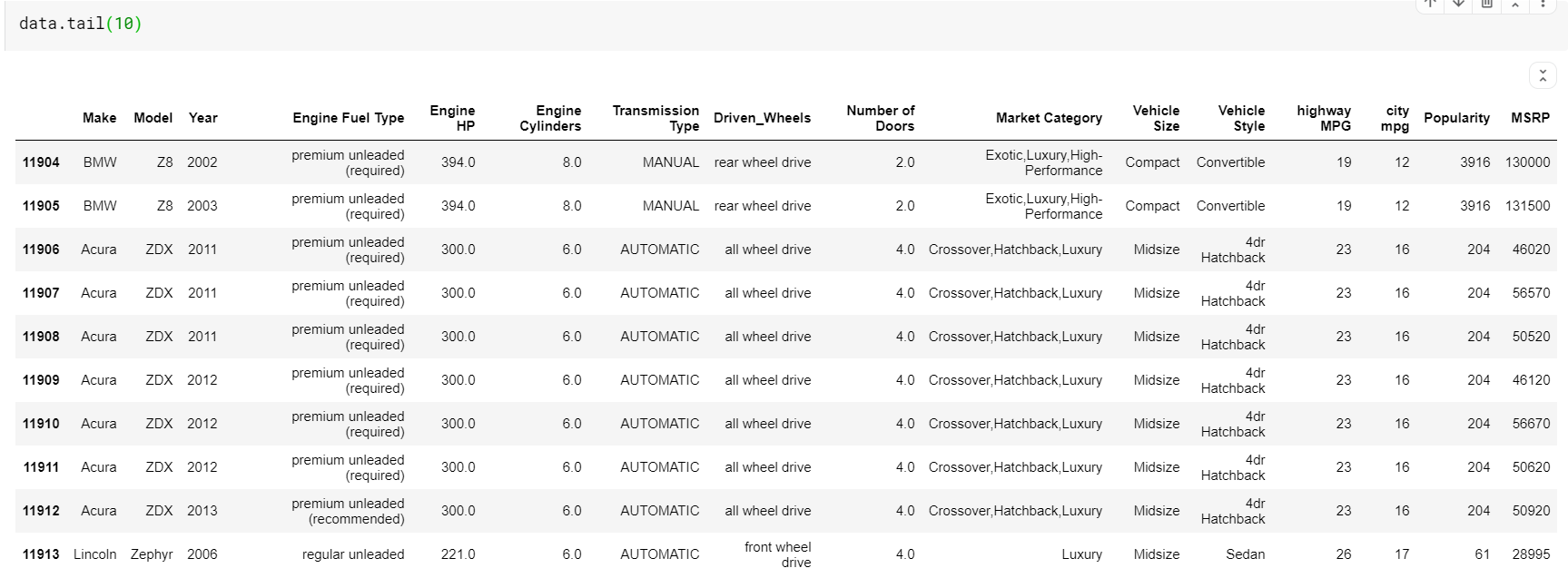
شيء واحد يجب ملاحظته هنا هو أن كلا من الدوال - الرأس والذيل يعطينا الفهارس العلوية أو السفلية. لكن الصفوف العلوية أو السفلية ليست دائمًا معاينة جيدة للبيانات. لذلك يمكنك أيضًا طباعة أي عدد من الصفوف التي تم أخذ عينات منها عشوائيًا من مجموعة البيانات باستخدام دالة sample ().
| # طباعة 5 صفوف عشوائية data.sample ( 5 ) |
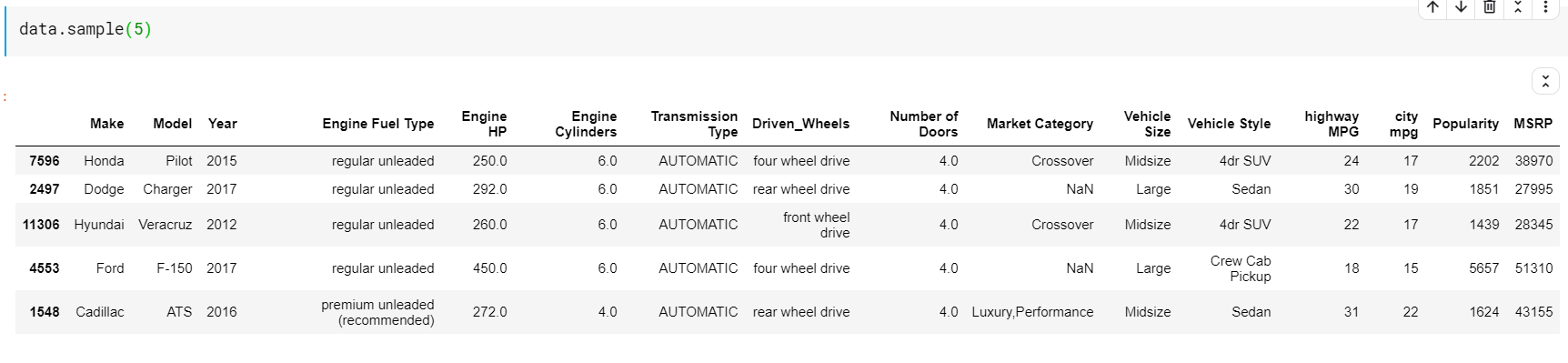
الإحصاء الوصفي
بعد ذلك ، دعنا نتحقق من الإحصائيات الوصفية لمجموعة البيانات. تتكون الإحصائيات الوصفية من كل ما "يصف" مجموعة البيانات. نتحقق من شكل إطار البيانات ، وما هي جميع الأعمدة الموجودة ، وما هي جميع الميزات الرقمية والفئوية الموجودة. سنرى أيضًا كيفية القيام بكل هذا في وظائف بسيطة.
شكل
| # التحقق من شكل إطار البيانات (مكسن) # م = عدد الصفوف # n = عدد الأعمدة البيانات |

كما نرى ، يحتوي إطار البيانات هذا على 11914 صفاً و 16 عموداً.
الأعمدة
| # طباعة أسماء الأعمدة البيانات |
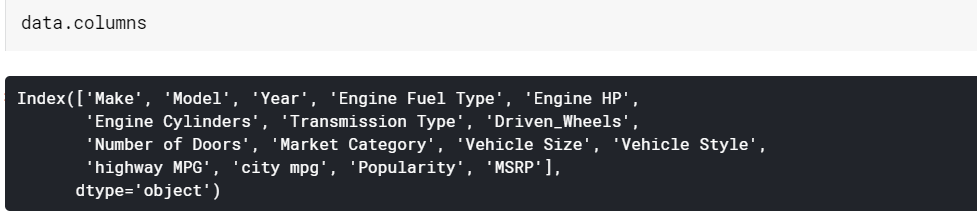
معلومات إطار البيانات
| # طباعة أنواع بيانات العمود وعدد القيم غير المفقودة data.info () |
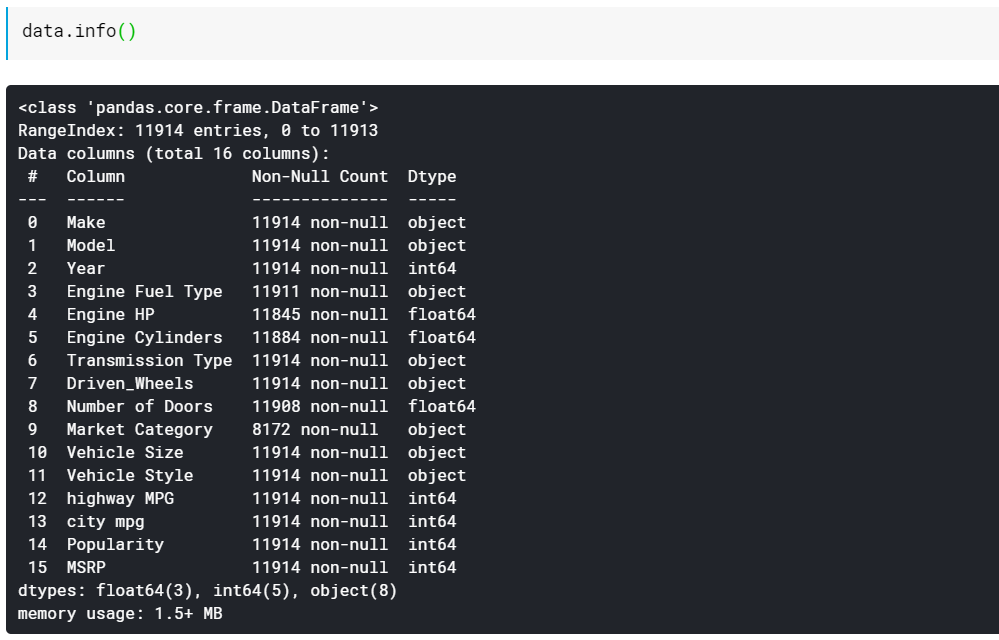
كما ترى ، تعطينا الدالة info () جميع الأعمدة وعدد القيم غير الفارغة أو غير المفقودة الموجودة في تلك الأعمدة وأخيراً نوع البيانات لهذه الأعمدة. هذه طريقة لطيفة وسريعة لمعرفة ما هي جميع الميزات الرقمية وما هي جميعها فئوية / تستند إلى النص. أيضًا ، لدينا الآن معلومات حول القيم المفقودة في جميع الأعمدة. سننظر في كيفية التعامل مع القيم المفقودة لاحقًا.
معالجة أسماء الأعمدة وأنواع البيانات
يعد فحص كل عمود ومعالجته بعناية أمرًا بالغ الأهمية في EDA. نحتاج إلى معرفة نوع المحتوى الذي يحتويه العمود / الميزة وما الذي قرأ الباندا نوع بياناته. أنواع البيانات الرقمية هي في الغالب int64 أو float64. يتم تخصيص نوع بيانات "الكائن" للسمات المستندة إلى النص أو الفئوية.
يتم تعيين الميزات المستندة إلى التاريخ والوقت هناك أوقات لا يفهم فيها Pandas نوع بيانات الميزة. في مثل هذه الحالات ، يقوم فقط بتعيين نوع بيانات "الكائن" بشكل كسول. يمكننا تحديد أنواع بيانات العمود بشكل صريح أثناء قراءة البيانات باستخدام read_csv.
اختيار الأعمدة الفئوية والرقمية
| # أضف جميع الأعمدة الفئوية والرقمية إلى قوائم منفصلة categorical = data.select_dtypes ( 'object' ) .columns الرقمية = data.select_dtypes ( 'number' ) .columns |


هنا النوع الذي مررناه كـ "رقم" يحدد جميع الأعمدة بأنواع البيانات التي لها أي نوع من الأرقام - سواء كان int64 أو float64.
إعادة تسمية الأعمدة
| # إعادة تسمية أسماء الأعمدة data = data.rename (أعمدة = { "Engine HP" : "HP" ، "اسطوانات المحرك" : "الاسطوانات" ، "نوع النقل" : "ناقل الحركة" ، "Driven_Wheels" : "Drive Mode" ، "الطريق السريع MPG" : "MPG-H" ، "MSRP" : "السعر" }) داتا.هيد ( 5 ) |

تأخذ وظيفة إعادة التسمية قاموسًا يحتوي على أسماء الأعمدة المراد إعادة تسميتها وأسمائها الجديدة.
معالجة القيم المفقودة والصفوف المكررة
تعتبر القيم المفقودة واحدة من أكثر المشكلات / التناقضات شيوعًا في أي مجموعة بيانات واقعية. يعتبر التعامل مع القيم المفقودة في حد ذاته موضوعًا واسعًا حيث توجد طرق متعددة للقيام بذلك. بعض الطرق هي طرق أكثر عمومية ، وبعضها أكثر تحديدًا لمجموعة البيانات التي قد يتعامل معها المرء.
التحقق من القيم المفقودة
| # التحقق من القيم المفقودة data.isnull (). sum () |
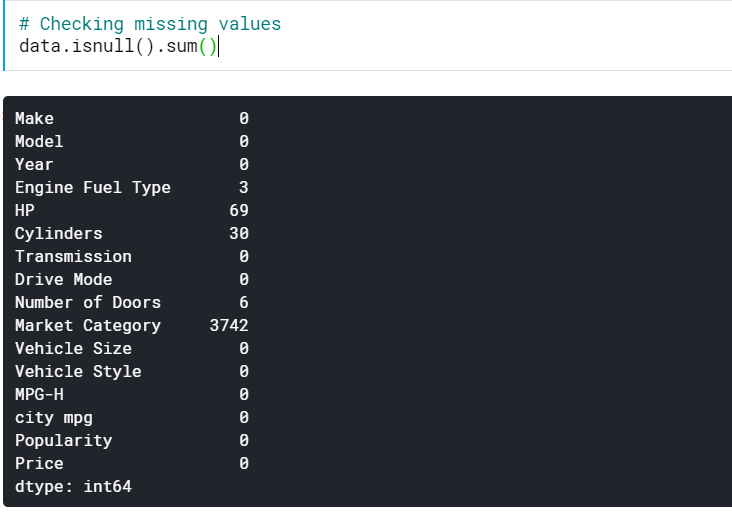
هذا يعطينا عدد القيم المفقودة في جميع الأعمدة. يمكننا أيضًا رؤية النسبة المئوية للقيم المفقودة.
| # النسبة المئوية للقيم المفقودة data.isnull (). mean () * 100 |
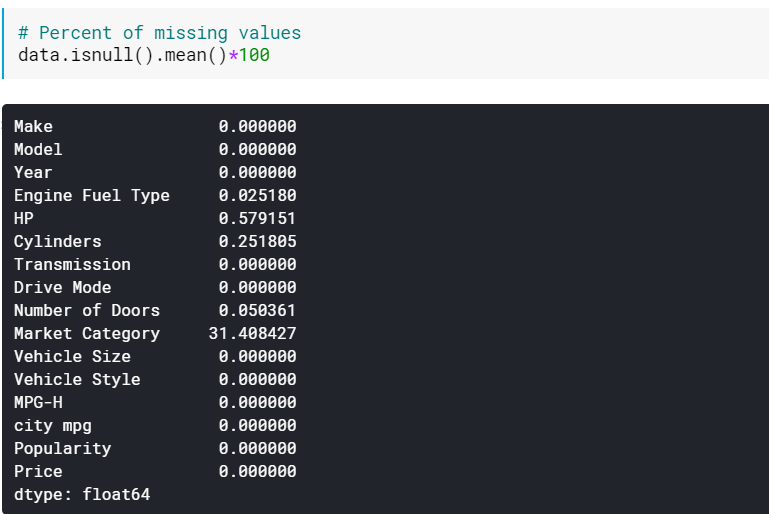
قد يكون التحقق من النسب مفيدًا عند وجود عدد كبير من الأعمدة التي تحتوي على قيم مفقودة. في مثل هذه الحالات ، يمكن فقط إسقاط الأعمدة التي بها الكثير من القيم المفقودة (على سبيل المثال ،> 60٪ مفقودة).
فرض القيم المفقودة
| #Imputing القيم المفقودة للأعمدة الرقمية بالمتوسط البيانات [الرقمية] = البيانات [العددية]. فيلنا (البيانات [العددية]. يعني (). iloc [ 0 ]) #Imputing القيم المفقودة للأعمدة الفئوية حسب الوضع data [categorical] = data [categorical] .fillna (بيانات [فئوية] .mode (). iloc [ 0 ]) |
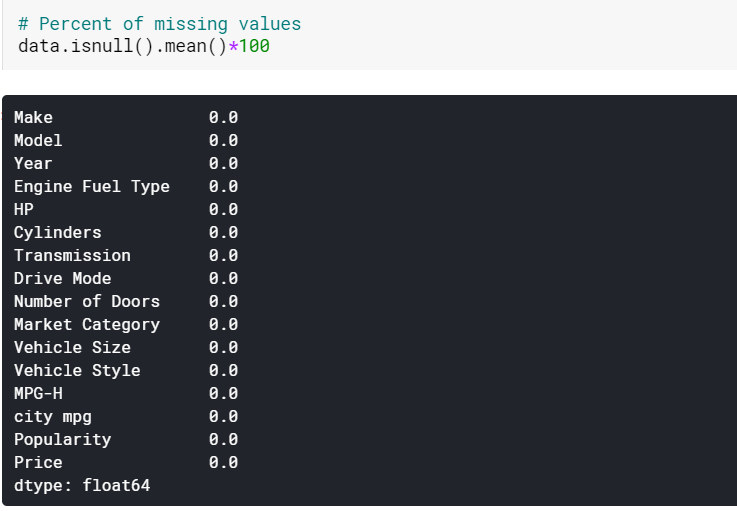
نحن هنا ببساطة نعزو القيم المفقودة في الأعمدة الرقمية بوسائلها الخاصة والقيم الموجودة في الأعمدة الفئوية حسب أوضاعها. وكما نرى ، لا توجد قيم مفقودة الآن.
يرجى ملاحظة أن هذه هي الطريقة الأكثر بدائية لإسناد القيم ولا تعمل في حالات الحياة الواقعية حيث يتم تطوير طرق أكثر تعقيدًا ، على سبيل المثال ، الاستيفاء ، KNN ، إلخ.
معالجة الصفوف المكررة
| # إسقاط الصفوف المكررة data.drop_duplicates (inplace = True ) |
هذا فقط يسقط الصفوف المكررة.
الخروج: أفكار ومواضيع مشروع بايثون
تحليل ثنائي المتغير
الآن دعنا نرى كيفية الحصول على المزيد من الأفكار عن طريق إجراء تحليل ثنائي المتغير. المتغير الثنائي يعني التحليل الذي يتكون من متغيرين أو سمات. تتوفر أنواع مختلفة من المؤامرات لأنواع مختلفة من الميزات.
للعدد - العددي
- مؤامرة مبعثر
- مؤامرة خط
- خريطة الحرارة للارتباطات
للفئات العددية
- شريط الرسم البياني
- مؤامرة الكمان
- مؤامرة سرب
من أجل Categorical-Categorical
- شريط الرسم البياني
- مؤامرة النقطة
خريطة التمثيل اللوني للارتباطات
| # التحقق من الارتباط بين المتغيرات. شكل plt (حجم الشكل = ( 15 ، 10 )) c = data.corr () sns.heatmap (c، cmap = "BrBG" ، التعليق التوضيحي = صحيح ) |
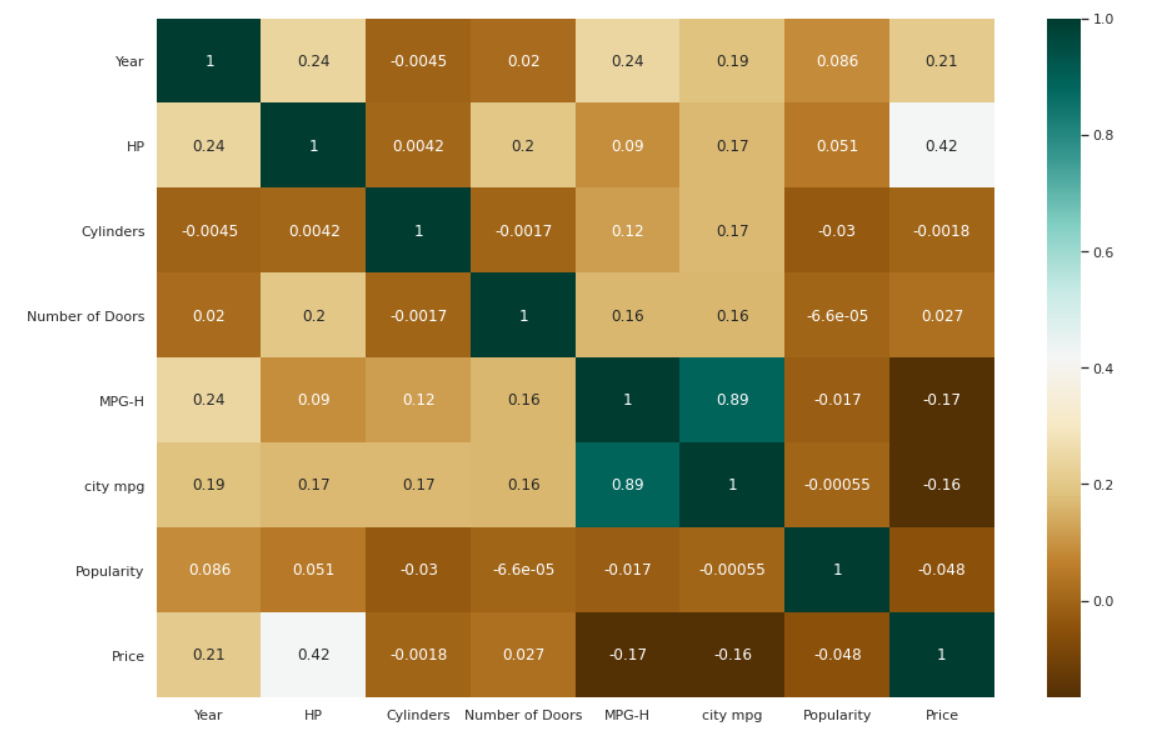
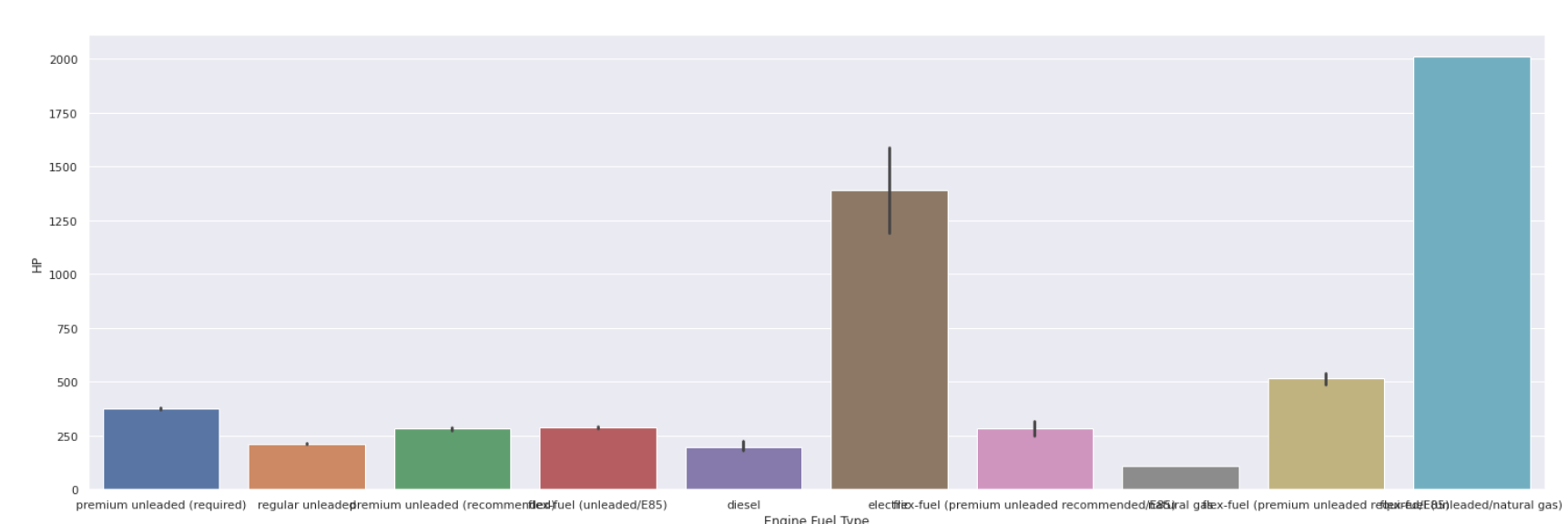
مؤامرة شريط
| sns.barplot (البيانات [ "نوع وقود المحرك" ] ، البيانات [ "HP" ]) |
احصل على شهادة علوم البيانات من أفضل الجامعات في العالم. تعلم برامج PG التنفيذية أو برامج الشهادات المتقدمة أو برامج الماجستير لتتبع حياتك المهنية بشكل سريع.
خاتمة
كما رأينا ، هناك الكثير من الخطوات التي يجب تغطيتها أثناء استكشاف مجموعة البيانات. لقد غطينا عددًا قليلاً فقط من الجوانب في هذا البرنامج التعليمي ، لكن هذا سيمنحك أكثر من مجرد معرفة أساسية بـ EDA جيدة.
إذا كنت مهتمًا بالتعرف على Python ، وكل شيء عن علم البيانات ، فراجع IIIT-B & upGrad's دبلوم PG في علوم البيانات الذي تم إنشاؤه للمهنيين العاملين ويقدم أكثر من 10 دراسات حالة ومشاريع ، وورش عمل عملية عملية ، وإرشاد مع الصناعة خبراء ، وجهاً لوجه مع مرشدين في الصناعة ، وأكثر من 400 ساعة من التعلم والمساعدة في العمل مع الشركات الكبرى.
ما هي خطوات تحليل البيانات الاستكشافية؟
الخطوات الرئيسية التي تحتاج إلى القيام بها للقيام بتحليل البيانات الاستكشافية هي -
يجب تحديد المتغيرات وأنواع البيانات.
تحليل المقاييس الأساسية
التحليل أحادي المتغير غير الرسومية
التحليل الرسومي أحادي المتغير
تحليل البيانات ثنائية المتغير
التحولات المتغيرة
معالجة القيمة المفقودة
معالجة القيم المتطرفة
تحليل الارتباط
تقليل الأبعاد
ما هو الغرض من تحليل البيانات الاستكشافية؟
الهدف الأساسي من EDA هو المساعدة في تحليل البيانات قبل وضع أي افتراضات. يمكن أن يساعد في اكتشاف الأخطاء الواضحة ، وكذلك فهم أفضل لأنماط البيانات ، واكتشاف القيم المتطرفة أو الأحداث غير العادية ، واكتشاف العلاقات المثيرة بين المتغيرات.
يمكن لعلماء البيانات استخدام التحليل الاستكشافي لضمان أن النتائج التي توصلوا إليها دقيقة ومناسبة لأي نتائج وأهداف عمل مستهدفة. كما تساعد أكاديمية الإمارات الدبلوماسية أصحاب المصلحة من خلال التأكد من أنهم يجيبون على الأسئلة المناسبة. يمكن الرد على الانحرافات المعيارية والبيانات الفئوية وفواصل الثقة مع EDA. بعد الانتهاء من EDA واستخراج الرؤى ، يمكن تطبيق ميزاته على تحليل البيانات أو النمذجة الأكثر تقدمًا ، بما في ذلك التعلم الآلي.
ما هي الأنواع المختلفة لتحليل البيانات الاستكشافية؟
هناك نوعان من تقنيات EDA: الرسومية والكمية (غير الرسومية). من ناحية أخرى ، يتطلب النهج الكمي تجميع إحصاءات موجزة ، بينما تتطلب الأساليب الرسومية جمع البيانات بطريقة بيانية أو مرئية. النهج وحيد المتغير ومتعدد المتغيرات هي مجموعات فرعية من هذين النوعين من المنهجيات.
لاستكشاف العلاقات ، تنظر الأساليب أحادية المتغير إلى متغير واحد (عمود البيانات) في كل مرة ، بينما تنظر الأساليب متعددة المتغيرات إلى متغيرين أو أكثر في وقت واحد. الرسومية أحادية المتغير والمتعددة المتغيرات وغير الرسومية هي الأشكال الأربعة لـ EDA. الإجراءات الكمية أكثر موضوعية ، في حين أن الأساليب التصويرية أكثر ذاتية.