
دليل الكشط الأخلاقي للمواقع الديناميكية باستخدام Node.js ومحرك الدمى
نشرت: 2022-03-10لنبدأ بقسم صغير حول ما يعنيه تجريف الويب بالفعل. كل منا يستخدم تجريف الويب في حياتنا اليومية. إنه يصف فقط عملية استخراج المعلومات من موقع الويب. وبالتالي ، إذا قمت بنسخ ولصق وصفة طبق المعكرونة المفضل لديك من الإنترنت إلى دفتر ملاحظاتك الشخصي ، فأنت تقوم بعملية تجريف الويب .
عند استخدام هذا المصطلح في صناعة البرمجيات ، نشير عادةً إلى أتمتة هذه المهمة اليدوية باستخدام قطعة من البرامج. بالتمسك بمثال "طبق المعكرونة" السابق ، تتضمن هذه العملية عادةً خطوتين:
- إحضار الصفحة
يجب أولاً تنزيل الصفحة ككل. هذه الخطوة تشبه فتح الصفحة في متصفح الويب الخاص بك عند الكشط يدويًا. - تحليل البيانات
الآن ، يتعين علينا استخراج الوصفة في HTML لموقع الويب وتحويلها إلى تنسيق يمكن قراءته آليًا مثل JSON أو XML.
في الماضي ، عملت في العديد من الشركات كمستشار بيانات. لقد اندهشت لرؤية عدد مهام استخراج البيانات والتجميع والإثراء التي لا تزال تتم يدويًا على الرغم من أنه يمكن أتمتتها بسهولة باستخدام بضعة أسطر من التعليمات البرمجية. هذا هو بالضبط ما يدور حوله تجريف الويب بالنسبة لي: استخراج وتطبيع أجزاء قيمة من المعلومات من موقع ويب لتغذية عملية تجارية أخرى ذات قيمة دافعة.
خلال هذا الوقت ، رأيت الشركات تستخدم تجريف الويب لجميع أنواع حالات الاستخدام. ركزت شركات الاستثمار بشكل أساسي على جمع البيانات البديلة ، مثل مراجعات المنتجات أو معلومات الأسعار أو منشورات وسائل التواصل الاجتماعي لدعم استثماراتها المالية.
هذا مثال واحد. اتصل بي أحد العملاء لاستخراج بيانات مراجعة المنتج للحصول على قائمة شاملة من المنتجات من العديد من مواقع التجارة الإلكترونية ، بما في ذلك التقييم وموقع المراجع ونص المراجعة لكل مراجعة تم إرسالها. مكنت بيانات النتائج العميل من تحديد الاتجاهات حول شعبية المنتج في الأسواق المختلفة. هذا مثال ممتاز على كيف يمكن لجزء واحد من المعلومات التي تبدو "عديمة الفائدة" أن يصبح ذا قيمة عند مقارنته بكمية أكبر.
تعمل الشركات الأخرى على تسريع عملية مبيعاتها باستخدام تجريف الويب لتوليد العملاء المتوقعين. تتضمن هذه العملية عادةً استخراج معلومات الاتصال مثل رقم الهاتف وعنوان البريد الإلكتروني واسم جهة الاتصال لقائمة معينة من مواقع الويب. تمنح أتمتة هذه المهمة فرق المبيعات مزيدًا من الوقت للتعرف على العملاء المحتملين. وبالتالي ، تزداد كفاءة عملية البيع.
التزم بالقواعد
بشكل عام ، يعد تجريف البيانات المتاحة للجمهور من الويب أمرًا قانونيًا ، كما تؤكده الولاية القضائية في قضية Linkedin مقابل HiQ. ومع ذلك ، فقد وضعت لنفسي مجموعة أخلاقية من القواعد التي أحب الالتزام بها عند بدء مشروع تجريف ويب جديد. هذا يشمل:
- التحقق من ملف robots.txt.
عادةً ما تحتوي على معلومات واضحة حول أجزاء الموقع التي لا بأس بصاحب الصفحة الوصول إليها بواسطة الروبوتات وأدوات الكشط وتسلط الضوء على الأقسام التي لا ينبغي الوصول إليها. - قراءة الشروط والأحكام.
مقارنةً بملف robots.txt ، لا تتوفر هذه المعلومة في كثير من الأحيان ، ولكنها توضح عادةً كيفية تعاملهم مع أدوات كاشطات البيانات. - القشط بسرعة معتدلة.
يُنشئ القشط حمل الخادم على البنية التحتية للموقع المستهدف. اعتمادًا على ما تتخلص منه ومستوى التزامن الذي تعمل به الكاشطة ، يمكن أن تتسبب حركة المرور في حدوث مشكلات للبنية التحتية لخادم الموقع المستهدف. بالطبع ، تلعب سعة الخادم دورًا كبيرًا في هذه المعادلة. ومن ثم ، فإن سرعة الكاشطة الخاصة بي هي دائمًا توازن بين كمية البيانات التي أهدف إلى كشطها وشعبية الموقع المستهدف. يمكن تحقيق هذا التوازن من خلال الإجابة على سؤال واحد: "هل ستؤدي السرعة المخططة إلى تغيير حركة المرور العضوية للموقع بشكل كبير؟". في الحالات التي أكون فيها غير متأكد من مقدار حركة المرور الطبيعية للموقع ، أستخدم أدوات مثل ahrefs للحصول على فكرة تقريبية.
اختيار التكنولوجيا المناسبة
في الواقع ، يعد التجريف باستخدام متصفح بدون رأس أحد أقل التقنيات أداءً التي يمكنك استخدامها ، حيث إنه يؤثر بشدة على البنية التحتية الخاصة بك. يمكن لنواة واحدة من معالج جهازك التعامل مع مثيل Chrome واحد تقريبًا.
دعنا نجري مثالاً حسابيًا سريعًا لنرى ما يعنيه هذا لمشروع تجريف الويب في العالم الحقيقي.
سيناريو
- تريد كشط 20000 عنوان URL.
- متوسط زمن الاستجابة من الموقع المستهدف هو 6 ثوان.
- يحتوي الخادم الخاص بك على نواتين لوحدة المعالجة المركزية.
سيستغرق المشروع 16 ساعة ليكتمل.
ومن ثم ، أحاول دائمًا تجنب استخدام متصفح عند إجراء اختبار جدوى كشط لموقع ويب ديناميكي.
فيما يلي قائمة تحقق صغيرة أراجعها دائمًا:
- هل يمكنني فرض حالة الصفحة المطلوبة من خلال معلمات GET في عنوان URL؟ إذا كانت الإجابة بنعم ، فيمكننا ببساطة تشغيل طلب HTTP باستخدام المعلمات الملحقة.
- هل جزء المعلومات الديناميكي من مصدر الصفحة ومتاح من خلال كائن JavaScript في مكان ما في DOM؟ إذا كانت الإجابة بنعم ، فيمكننا مرة أخرى استخدام طلب HTTP عادي وتحليل البيانات من الكائن المُحدد.
- هل يتم جلب البيانات من خلال طلب XHR؟ إذا كان الأمر كذلك ، فهل يمكنني الوصول مباشرة إلى نقطة النهاية باستخدام عميل HTTP؟ إذا كانت الإجابة بنعم ، فيمكننا إرسال طلب HTTP إلى نقطة النهاية مباشرةً. في كثير من الأحيان ، يتم تنسيق الاستجابة بتنسيق JSON ، مما يجعل حياتنا أسهل بكثير.
إذا تمت الإجابة على جميع الأسئلة بـ "لا" محددة ، فإننا نفد رسميًا من الخيارات الممكنة لاستخدام عميل HTTP. بالطبع ، قد يكون هناك المزيد من التعديلات الخاصة بالمواقع التي يمكننا تجربتها ، ولكن عادةً ما يكون الوقت المطلوب لاكتشافها مرتفعًا جدًا ، مقارنةً بالأداء الأبطأ لمتصفح بدون رأس. يكمن جمال تجريف المستعرض في أنه يمكنك كشط أي شيء يخضع للقاعدة الأساسية التالية:
إذا كان بإمكانك الوصول إليه باستخدام متصفح ، فيمكنك التخلص منه.
لنأخذ الموقع التالي كمثال للكاشطة الخاصة بنا: https://quotes.toscrape.com/search.aspx. يحتوي على اقتباسات من قائمة المؤلفين المعينين لقائمة الموضوعات. يتم جلب جميع البيانات عبر XHR.
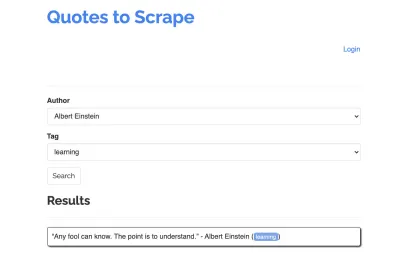
كل من ألقى نظرة فاحصة على أداء الموقع وتصفح قائمة المراجعة أعلاه ربما أدرك أنه يمكن بالفعل كشط الاقتباسات باستخدام عميل HTTP ، حيث يمكن استردادها عن طريق تقديم طلب POST على نقطة نهاية الأسعار مباشرة. ولكن نظرًا لأنه من المفترض أن يغطي هذا البرنامج التعليمي كيفية كشط موقع ويب باستخدام محرك العرائس ، فسوف نتظاهر بأن هذا مستحيل.
تثبيت المتطلبات
نظرًا لأننا سنبني كل شيء باستخدام Node.js ، فلنقم أولاً بإنشاء وفتح مجلد جديد ، وإنشاء مشروع Node جديد بداخله ، وتشغيل الأمر التالي:
mkdir js-webscraper cd js-webscraper npm initيرجى التأكد من أنك قمت بالفعل بتثبيت npm. سيطرح علينا المثبت بعض الأسئلة حول المعلومات الوصفية حول هذا المشروع ، والتي يمكننا جميعًا تخطيها ، بالضغط على Enter .
تركيب محرك العرائس
لقد كنا نتحدث عن التجريف باستخدام متصفح من قبل. Puppeteer هي واجهة برمجة تطبيقات Node.js تتيح لنا التحدث إلى مثيل Chrome بدون رأس برمجيًا.
لنقم بتثبيته باستخدام npm:
npm install puppeteerبناء مكشطة لدينا
الآن ، لنبدأ في بناء الكاشطة الخاصة بنا عن طريق إنشاء ملف جديد يسمى scraper.js .
أولاً ، نقوم باستيراد المكتبة المثبتة مسبقًا ، Puppeteer:
const puppeteer = require('puppeteer');كخطوة تالية ، نطلب من Puppeteer فتح مثيل متصفح جديد داخل وظيفة غير متزامنة وذاتية التنفيذ:
(async function scrape() { const browser = await puppeteer.launch({ headless: false }); // scraping logic comes here… })();ملاحظة : افتراضيًا ، يتم إيقاف تشغيل وضع مقطوعة الرأس ، حيث يؤدي ذلك إلى زيادة الأداء. ومع ذلك ، عند بناء مكشطة جديدة ، أود إيقاف تشغيل وضع مقطوعة الرأس. يتيح لنا ذلك متابعة العملية التي يمر بها المتصفح ومشاهدة كل المحتوى المقدم. سيساعدنا هذا في تصحيح البرنامج النصي الخاص بنا لاحقًا.
داخل مثيل المتصفح المفتوح لدينا ، نفتح الآن صفحة جديدة ونوجه نحو عنوان URL المستهدف:
const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); كجزء من الوظيفة غير المتزامنة ، سنستخدم تعليمة await الانتظار حتى يتم تنفيذ الأمر التالي قبل متابعة السطر التالي من التعليمات البرمجية.
الآن بعد أن فتحنا نافذة المتصفح بنجاح وانتقلنا إلى الصفحة ، يتعين علينا إنشاء حالة موقع الويب ، بحيث تصبح الأجزاء المطلوبة من المعلومات مرئية للتخلص منها.
يتم إنشاء الموضوعات المتاحة ديناميكيًا لمؤلف مختار. ومن ثم ، سنختار أولاً "ألبرت أينشتاين" وننتظر قائمة الموضوعات التي تم إنشاؤها. بمجرد إنشاء القائمة بالكامل ، نختار "التعلم" كموضوع ونختاره كمعامل نموذج ثانٍ. ثم نضغط على "إرسال" ونستخرج علامات الاقتباس المسترجعة من الحاوية التي تحتوي على النتائج.
نظرًا لأننا سنحول هذا الآن إلى منطق JavaScript ، فلنقم أولاً بعمل قائمة بجميع محددات العناصر التي تحدثنا عنها في الفقرة السابقة:
| المؤلف حدد المجال | #author |
| علامة تحديد الحقل | #tag |
| زر الإرسال | input[type="submit"] |
| حاوية الاقتباس | .quote |
قبل أن نبدأ في التفاعل مع الصفحة ، سوف نتأكد من أن جميع العناصر التي سنصل إليها مرئية ، عن طريق إضافة الأسطر التالية إلى البرنامج النصي الخاص بنا:

await page.waitForSelector('#author'); await page.waitForSelector('#tag');بعد ذلك ، سنحدد قيمًا للحقلين المختارين لدينا:
await page.select('select#author', 'Albert Einstein'); await page.select('select#tag', 'learning');نحن الآن جاهزون لإجراء بحثنا عن طريق الضغط على زر "بحث" على الصفحة وانتظار ظهور علامات الاقتباس:
await page.click('.btn'); await page.waitForSelector('.quote'); نظرًا لأننا الآن بصدد الوصول إلى بنية HTML للصفحة ، فإننا نستدعي وظيفة page.evaluate() المقدمة ، ونختار الحاوية التي تحتوي على علامات الاقتباس (إنها واحدة فقط في هذه الحالة). ثم نبني كائنًا ونعرِّف القيمة null على أنها القيمة الاحتياطية لكل معلمة object :
let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, }; }); return quotes; });يمكننا جعل جميع النتائج مرئية في وحدة التحكم الخاصة بنا عن طريق تسجيلها:
console.log(quotes);أخيرًا ، دعنا نغلق متصفحنا ونضيف عبارة catch:
await browser.close();تبدو المكشطة الكاملة كما يلي:
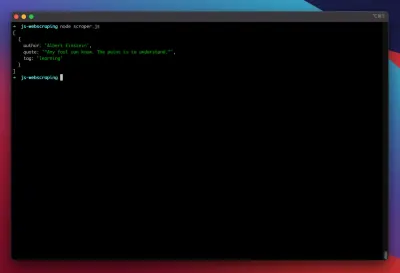
const puppeteer = require('puppeteer'); (async function scrape() { const browser = await puppeteer.launch({ headless: false }); const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('#author'); await page.select('#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); // logging results console.log(quotes); await browser.close(); })();دعنا نحاول تشغيل الكاشطة الخاصة بنا باستخدام:
node scraper.jsوها نحن ذا! تقوم أداة الكشط بإرجاع كائن الاقتباس كما هو متوقع:
تحسينات متقدمة
الكاشطة الأساسية لدينا تعمل الآن. دعنا نضيف بعض التحسينات لإعداده لبعض مهام الكشط الأكثر جدية.
تعيين وكيل المستخدم
بشكل افتراضي ، يستخدم Puppeteer وكيل مستخدم يحتوي على السلسلة HeadlessChrome . يبحث عدد قليل جدًا من مواقع الويب عن هذا النوع من التوقيع ويحظر الطلبات الواردة بتوقيع كهذا. لتجنب أن يكون ذلك سببًا محتملاً لفشل الكاشطة ، أقوم دائمًا بتعيين وكيل مستخدم مخصص عن طريق إضافة السطر التالي إلى الكود الخاص بنا:
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36');يمكن تحسين ذلك بشكل أكبر عن طريق اختيار وكيل مستخدم عشوائي مع كل طلب من مجموعة من أكثر 5 وكلاء مستخدم شيوعًا. يمكن العثور على قائمة بوكلاء المستخدم الأكثر شيوعًا في قطعة على وكلاء المستخدم الأكثر شيوعًا.
تنفيذ الوكيل
يجعل برنامج Puppeteer الاتصال بالخادم الوكيل أمرًا سهلاً للغاية ، حيث يمكن تمرير عنوان الوكيل إلى Puppeteer عند الإطلاق ، على النحو التالي:
const browser = await puppeteer.launch({ headless: false, args: [ '--proxy-server=<PROXY-ADDRESS>' ] });يوفر sslproxies قائمة كبيرة من البروكسيات المجانية التي يمكنك استخدامها. بدلاً من ذلك ، يمكن استخدام خدمات الوكيل الدورية. نظرًا لأنه يتم عادةً مشاركة الوكلاء بين العديد من العملاء (أو المستخدمين المجانيين في هذه الحالة) ، يصبح الاتصال غير موثوق به أكثر مما هو عليه بالفعل في ظل الظروف العادية. هذه هي اللحظة المثالية للتحدث عن معالجة الأخطاء وإعادة المحاولة.
الخطأ وإعادة المحاولة-الإدارة
يمكن أن تتسبب العديد من العوامل في فشل الكاشطة. وبالتالي ، من المهم معالجة الأخطاء وتحديد ما يجب أن يحدث في حالة الفشل. نظرًا لأننا ربطنا الكاشطة ببروكسي ونتوقع أن يكون الاتصال غير مستقر (خاصة لأننا نستخدم وكلاء مجانيين) ، فنحن نريد إعادة المحاولة أربع مرات قبل الاستسلام.
أيضًا ، لا فائدة من إعادة محاولة طلب بنفس عنوان IP مرة أخرى إذا كان قد فشل سابقًا. ومن ثم ، سنقوم ببناء نظام تدوير وكيل صغير.
بادئ ذي بدء ، نقوم بإنشاء متغيرين جديدين:
let retry = 0; let maxRetries = 5; في كل مرة نقوم فيها بتشغيل دالة scrape() ، سنزيد متغير إعادة المحاولة بمقدار 1. ثم نلف منطق الكشط الكامل بعبارة try and catch حتى نتمكن من معالجة الأخطاء. تحدث إدارة إعادة المحاولة داخل وظيفة catch الخاصة بنا:
سيتم إغلاق مثيل المتصفح السابق ، وإذا كان متغير إعادة المحاولة أصغر من متغير maxRetries ، فسيتم استدعاء وظيفة الكشط بشكل متكرر.
ستبدو الكاشطة الآن كما يلي:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); … // our scraping logic } catch(e) { console.log(e); await browser.close(); if (retry < maxRetries) { scrape(); } };الآن ، دعونا نضيف الدوار الوكيل المذكور سابقًا.
لنقم أولاً بإنشاء مصفوفة تحتوي على قائمة من الوكلاء:
let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ];الآن ، اختر قيمة عشوائية من المصفوفة:
var proxy = proxyList[Math.floor(Math.random() * proxyList.length)];يمكننا الآن تشغيل الوكيل الذي تم إنشاؤه ديناميكيًا مع مثيل محرك العرائس الخاص بنا:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] });بالطبع ، يمكن تحسين هذا الجهاز الدوار الوكيل بشكل أكبر لتحديد البروكسيات الميتة ، وما إلى ذلك ، ولكن هذا بالتأكيد سيتجاوز نطاق هذا البرنامج التعليمي.
هذا هو رمز الكاشطة (بما في ذلك جميع التحسينات):
const puppeteer = require('puppeteer'); // starting Puppeteer let retry = 0; let maxRetries = 5; (async function scrape() { retry++; let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ]; var proxy = proxyList[Math.floor(Math.random() * proxyList.length)]; console.log('proxy: ' + proxy); const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36'); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('select#author'); await page.select('select#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('select#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); console.log(quotes); await browser.close(); } catch (e) { await browser.close(); if (retry < maxRetries) { scrape(); } } })();هاهو! سيؤدي تشغيل الكاشطة داخل المحطة إلى إرجاع الأسعار.
الكاتب المسرحي كبديل لمحرك الدمى
تم تطوير محرك العرائس بواسطة Google. في بداية عام 2020 ، أصدرت Microsoft بديلاً يسمى Playwright. طاردت Microsoft الكثير من المهندسين من فريق محرك العرائس. ومن ثم ، تم تطوير Playwright من قبل الكثير من المهندسين الذين عملوا بالفعل على محرك العرائس. إلى جانب كونه الطفل الجديد على المدونة ، فإن أكبر نقطة تميز في Playwright هي دعم المستعرضات المتقاطعة ، حيث يدعم Chromium و Firefox و WebKit (Safari).
تُظهر اختبارات الأداء (مثل هذا الاختبار الذي أجرته Checkly) أن محرك العرائس يوفر عمومًا أداءً أفضل بنسبة 30٪ تقريبًا ، مقارنةً بالكاتب المسرحي ، وهو ما يطابق تجربتي الخاصة - على الأقل في وقت كتابة هذا التقرير.
الاختلافات الأخرى ، مثل حقيقة أنه يمكنك تشغيل أجهزة متعددة بمثيل متصفح واحد ، ليست ذات قيمة فعلية لسياق تجريف الويب.
موارد وروابط إضافية
- وثائق محرك العرائس
- تعلم العرائس والكاتب المسرحي
- تجريف الويب باستخدام Javascript بواسطة Zenscrape
- وكلاء المستخدم الأكثر شيوعًا
- محرك العرائس مقابل الكاتب المسرحي