
هياكل البيانات في بايثون - دليل كامل
نشرت: 2021-06-14جدول المحتويات
ما هي بنية البيانات؟
تشير بنية البيانات إلى التخزين الحسابي للبيانات من أجل الاستخدام الفعال. يقوم بتخزين البيانات بطريقة يمكن تعديلها والوصول إليها بسهولة. يشير بشكل جماعي إلى قيم البيانات والعلاقة بينها والعمليات التي يمكن تنفيذها على البيانات. تكمن أهمية بنية البيانات في تطبيقها لتطوير برامج الكمبيوتر. نظرًا لأن برامج الكمبيوتر تعتمد بشكل كبير على البيانات ، فإن الترتيب المناسب للبيانات لسهولة الوصول إليها له أهمية قصوى تجاه أي برنامج أو برنامج.
الوظائف الأربع الرئيسية لهيكل البيانات هي
- لإدخال المعلومات
- لمعالجة المعلومات
- للحفاظ على المعلومات
- لاسترداد المعلومات
أنواع هياكل البيانات في بايثون
يتم دعم العديد من هياكل البيانات بواسطة Python لسهولة الوصول إلى البيانات وتخزينها. يمكن تصنيف أنواع هياكل بيانات Python على أنها أنواع بيانات بدائية وغير بدائية. تتضمن أنواع البيانات السابقة الأعداد الصحيحة ، والعائمة ، والسلاسل النصية ، والمنطقية ، بينما النوع الأخير هو المصفوفة ، والقائمة ، والمجموعات ، والقواميس ، والمجموعات ، والملفات. لذلك ، فإن هياكل البيانات في Python عبارة عن هياكل بيانات مضمنة وهياكل بيانات محددة من قبل المستخدم. يشار إلى بنية البيانات المضمنة باسم بنية البيانات غير البدائية.
هياكل البيانات المدمجة
تمتلك Python العديد من هياكل البيانات التي تعمل كحاويات لتخزين البيانات الأخرى. هياكل بيانات Python هذه هي List ، و Dictionaries ، و Tuple ، و Sets.
هياكل البيانات المعرفة من قبل المستخدم
يمكن برمجة هياكل البيانات هذه بنفس وظيفة هياكل البيانات المضمنة في Python . هياكل البيانات المعرفة من قبل المستخدم هي ؛ قائمة مرتبطة ، مكدس ، قائمة انتظار ، شجرة ، رسم بياني ، و Hashmap.
قائمة بهياكل البيانات المضمنة وشرحها
1. قائمة
يتم ترتيب البيانات المخزنة في القائمة بشكل تسلسلي ومن أنواع بيانات مختلفة. لكل بيانات ، يتم تعيين عنوان ويعرف بالفهرس. تبدأ قيمة الفهرس بـ 0 وتستمر حتى العنصر الأخير. وهذا ما يسمى بالمؤشر الإيجابي. يوجد فهرس سالب أيضًا إذا تم الوصول إلى العناصر بشكل عكسي. وهذا ما يسمى بالفهرسة السلبية.
إنشاء القائمة
يتم إنشاء القائمة كأقواس مربعة. يمكن بعد ذلك إضافة العناصر وفقًا لذلك. يمكن إضافته داخل الأقواس المربعة لإنشاء قائمة. إذا لم تتم إضافة أي عناصر ، فسيتم إنشاء قائمة فارغة. وإلا سيتم إنشاء العناصر داخل القائمة.
| إدخال my_list = [] # إنشاء قائمة فارغة طباعة (my_list) my_list = [1، 2، 3، "مثال"، 3.132] # إنشاء قائمة بالبيانات طباعة (my_list) | انتاج | [] [1 ، 2 ، 3 ، "مثال" ، 3.132] |
إضافة العناصر داخل القائمة
يتم استخدام ثلاث وظائف لإضافة عناصر داخل القائمة. هذه الدالات هي append () و extension () و insert ().
- تتم إضافة جميع العناصر كعنصر واحد باستخدام الوظيفة append ().
- لإضافة العناصر واحدًا تلو الآخر في القائمة ، يتم استخدام وظيفة extension ().
- لإضافة العناصر حسب قيمة الفهرس الخاصة بهم ، يتم استخدام الوظيفة insert ().
| إدخال my_list = [1، 2، 3] طباعة (my_list) my_list.append ([555، 12]) #add كعنصر واحد طباعة (my_list) my_list.extend ([234، 'more_example']) # إضافة كعناصر مختلفة طباعة (my_list) my_list.insert (1، 'insert_example') #add element i طباعة (my_list) | انتاج: [1، 2، 3] [1 ، 2 ، 3 ، [555 ، 12]] [1، 2، 3، [555، 12]، 234، 'more_example'] [1، 'insert_example'، 2، 3، [555، 12]، 234، 'more_example'] |
حذف العناصر داخل القائمة
يتم استخدام الكلمة الأساسية المضمنة "del" في لغة python لحذف عنصر من القائمة. ومع ذلك ، لا تقوم هذه الوظيفة بإرجاع العنصر المحذوف.
- لإرجاع عنصر محذوف ، يتم استخدام وظيفة pop (). يستخدم قيمة الفهرس للعنصر المراد حذفه.
- تُستخدم الوظيفة remove () لحذف عنصر بقيمته.
انتاج:
[1 ، 2 ، 3 ، "مثال" ، 3.132 ، 30]
[1 ، 2 ، 3 ، 3.132 ، 30]
العنصر المنبثق: 2 القائمة المتبقية: [1 ، 3 ، 3.132 ، 30]
[]
تقييم العناصر في القائمة
- تقييم العنصر في القائمة أمر بسيط. ستؤدي طباعة القائمة إلى عرض العناصر مباشرة.
- يمكن تقييم عناصر محددة بتمرير قيمة المؤشر.
انتاج:
1
2
3
مثال
3.132
10
30
[1 ، 2 ، 3 ، "مثال" ، 3.132 ، 10 ، 30]
مثال
[1، 2]
[30 ، 10 ، 3.132 ، "مثال" ، 3 ، 2 ، 1]
بالإضافة إلى العمليات المذكورة أعلاه ، تتوفر العديد من الوظائف المضمنة الأخرى في Python للعمل مع القوائم.
- len (): تُستخدم الوظيفة لإرجاع طول القائمة.
- index (): تسمح هذه الوظيفة للمستخدم بمعرفة قيمة الفهرس للقيمة التي تم تمريرها.
- تُستخدم الدالة count () للعثور على عدد القيمة التي تم تمريرها إليها.
- Sort () يفرز القيمة في قائمة ويعدل القائمة.
- Sorted () يفرز القيمة في قائمة ويعيد القائمة.
انتاج |
6
3
2
[1 ، 2 ، 3 ، 10 ، 10 ، 30]
[30 ، 10 ، 10 ، 3 ، 2 ، 1]
2. القاموس
القاموس هو نوع من بنية البيانات حيث يتم تخزين أزواج القيمة الرئيسية بدلاً من العناصر الفردية. يمكن تفسير ذلك بمثال دليل الهاتف الذي يحتوي على جميع أرقام الأفراد إلى جانب أرقام هواتفهم. يحدد الاسم ورقم الهاتف هنا القيم الثابتة التي تمثل "المفتاح" وأرقام وأسماء جميع الأفراد كقيم لهذا المفتاح. سيؤدي تقييم المفتاح إلى منح الوصول إلى جميع القيم المخزنة داخل هذا المفتاح. تُعرف بنية القيمة الرئيسية المحددة في Python باسم القاموس.
إنشاء قاموس
- أقواس الزهرة خامدة وظيفة ديكت () يمكن استخدامها لإنشاء قاموس.
- يجب إضافة أزواج المفتاح والقيمة أثناء إنشاء القاموس.
التعديل في أزواج المفتاح والقيمة
لا يمكن إجراء أي تعديلات في القاموس إلا من خلال المفتاح. لذلك ، يجب الوصول إلى المفاتيح أولاً ثم إجراء التعديلات.
| إدخال my_dict = {'First': 'Python'، 'Second': 'Java'} print (my_dict) my_dict ['Second'] = 'C ++' #changing element print (my_dict) my_dict ['Third'] = 'Ruby' #adding طباعة زوج مفتاح القيمة (my_dict) | انتاج: {'First': 'Python'، 'Second': 'Java'} {'First': 'Python'، 'Second': 'C ++'} {'First': 'Python'، 'Second': 'C ++'، 'Third': 'Ruby'} |
حذف القاموس
يتم استخدام وظيفة clear () لحذف القاموس بأكمله. يمكن تقييم القاموس من خلال المفاتيح باستخدام وظيفة get () أو تمرير قيم المفاتيح.
| إدخال ديكت = {'شهر': 'يناير'، 'الموسم': 'الشتاء'} طباعة (ديكت ["الأول"]) طباعة (ديكت.جيت ("ثانية") | انتاج | كانون الثاني شتاء |
الوظائف الأخرى المرتبطة بالقاموس هي المفاتيح () والقيم () والعناصر ().
3. Tuple
على غرار القائمة ، تعد Tuples قوائم تخزين البيانات ، ولكن الاختلاف الوحيد هو أن البيانات المخزنة في المجموعة لا يمكن تعديلها. إذا كانت البيانات داخل المجموعة قابلة للتغيير ، عندها فقط يمكن تغيير البيانات.
- يمكن إنشاء المجموعات من خلال وظيفة tuple ().
إدخال
new_tuple = (10 ، 20 ، 30 ، 40)
طباعة (new_tuple)
انتاج |
(10 ، 20 ، 30 ، 40)
- يمكن تقييم العناصر الموجودة في المجموعة بنفس طريقة تقييم العناصر في القائمة.
إدخال
new_tuple2 = (10، 20، 30، "العمر")
لـ x في new_tuple2:
طباعة (x)
طباعة (new_tuple2)
طباعة (new_tuple2 [0])
انتاج |
10
20
30
سن
(10 ، 20 ، 30 ، "عمر")
10
- يتم استخدام عامل التشغيل "+" لإلحاق مجموعة أخرى
إدخال
tuple = (1، 2، 3)
tuple = tuple + (4، 5، 6
print (tuple)
انتاج |
(1 ، 2 ، 3 ، 4 ، 5 ، 6)
4. مجموعة
تشبه بنية البيانات المحددة المجموعات الحسابية. إنها في الأساس مجموعة من العناصر الفريدة. إذا استمرت البيانات في التكرار ، فحينئذٍ تنظر المجموعات في إضافة هذا العنصر مرة واحدة فقط.

- يمكن إنشاء مجموعة فقط عن طريق تمرير القيم إليها داخل الأقواس الزهرية.
إدخال
المجموعة = {10 ، 20 ، 30 ، 40 ، 40 ، 40}
طباعة (مجموعة)
انتاج |
{10 ، 20 ، 30 ، 40}
- يمكن استخدام الوظيفة add () لإضافة عناصر إلى مجموعة.
- لدمج البيانات من مجموعتين ، يمكن استخدام وظيفة union ().
- لتحديد البيانات الموجودة في كلا المجموعتين ، يتم استخدام وظيفة التقاطع ().
- تقوم دالة الفرق () بإخراج البيانات الفريدة للمجموعة فقط ، مما يؤدي إلى إزالة البيانات الشائعة.
- تقوم الدالة symmetric_difference () بإخراج البيانات الفريدة لكلتا المجموعتين.
قائمة بهياكل البيانات المعرفة من قبل المستخدم وشرحها
1. الأكوام
المكدس عبارة عن بنية خطية تكون إما بنية Last in First out (LIFO) أو First in Last Out (FIFO). توجد عمليتان رئيسيتان في المكدس ، أي الدفع والفرقعة. الدفع يعني إلحاق عنصر بأعلى القائمة بينما الفرقعة تعني إزالة عنصر من أسفل المكدس. العملية موصوفة بشكل جيد في الشكل 1.
فائدة المكدس
- يمكن تقييم العناصر السابقة من خلال التتبع العكسي.
- مطابقة العناصر العودية.
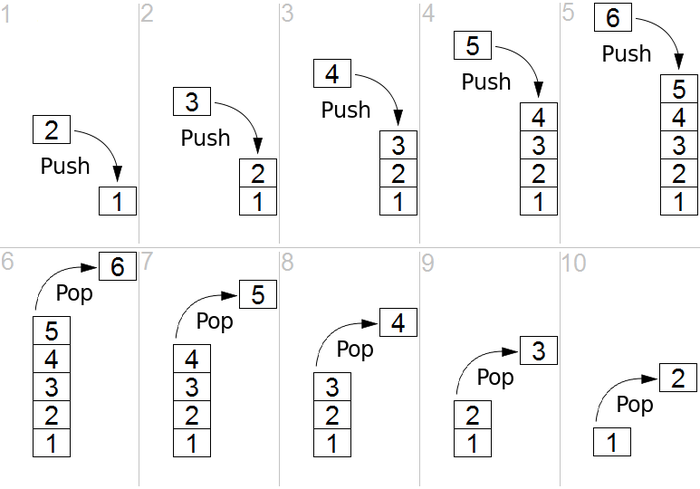
مصدر
الشكل 1: تمثيل رسومي للمكدس
مثال

انتاج |
['اول ثان ثالث']
['الاول الثاني الثالث الرابع الخامس']
الخامس
['الأول الثاني الثالث الرابع']
2. قائمة الانتظار
على غرار المكدسات ، فإن قائمة الانتظار هي بنية خطية تسمح بإدراج عنصر في أحد طرفيه وحذفه من الطرف الآخر. تُعرف العمليتان باسم enqueue و dequeue. تتم إزالة العنصر المضاف مؤخرًا أولاً مثل الحزم. يظهر تمثيل رسومي لقائمة الانتظار في الشكل 2. أحد الاستخدامات الرئيسية لقائمة الانتظار هو معالجة الأشياء بمجرد دخولها.
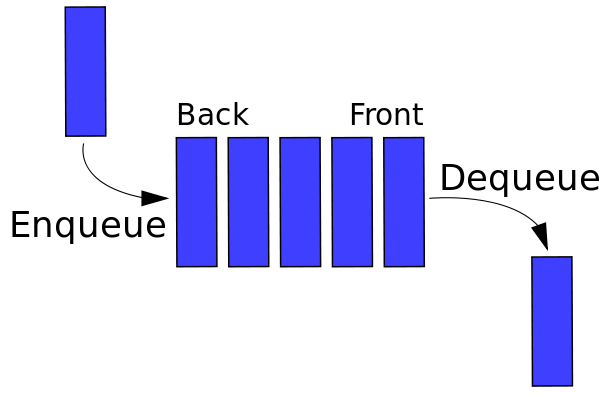
مصدر
الشكل 2 : تمثيل رسومي لقوائم الانتظار
مثال

انتاج |
['اول ثان ثالث']
['الاول الثاني الثالث الرابع الخامس']
أول
الخامس
["الثاني" ، "الثالث" ، "الرابع" ، "الخامس"]
3. شجرة
الأشجار هي هياكل بيانات غير خطية وهرمية تتكون من عقد مرتبطة بالحواف. تحتوي بنية بيانات شجرة Python على عقدة جذر وعقدة أصل وعقدة فرعية. الجذر هو العنصر الأعلى في بنية البيانات. الشجرة الثنائية هي بنية لا تحتوي فيها العناصر على أكثر من عقدتين فرعيتين.
فائدة الشجرة
- يعرض العلاقات الهيكلية لعناصر البيانات.
- اجتياز كل عقدة بكفاءة
- يمكن للمستخدمين إدخال البيانات والبحث فيها واستردادها وحذفها.
- هياكل البيانات المرنة
الشكل 3: تمثيل رسومي لشجرة
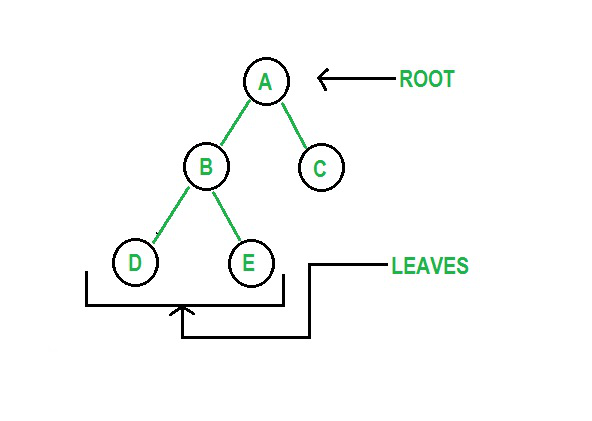
مصدر
مثال:

انتاج |
أولا
ثانيا
ثالث
4. الرسم البياني
هيكل بيانات غير خطي آخر في بايثون هو الرسم البياني الذي يتكون من عقد وحواف. يعرض مجموعة من الكائنات ، مع بعض الكائنات المتصلة من خلال الروابط. الرؤوس عبارة عن كائنات مترابطة بينما تسمى الروابط بالحواف. يمكن تمثيل الرسم البياني من خلال هيكل بيانات قاموس Python ، حيث يمثل المفتاح الرؤوس والقيم تمثل الحواف.
العمليات الأساسية التي يمكن أداؤها على الرسوم البيانية
- عرض رؤوس وحواف الرسم البياني.
- إضافة الرأس.
- إضافة حافة.
- إنشاء الرسم البياني
فائدة الرسم البياني
- من السهل فهم ومتابعة تمثيل الرسم البياني.
- إنها بنية رائعة لتمثيل العلاقات المرتبطة ، أي أصدقاء Facebook.
الشكل 4: تمثيل رسومي للرسم البياني
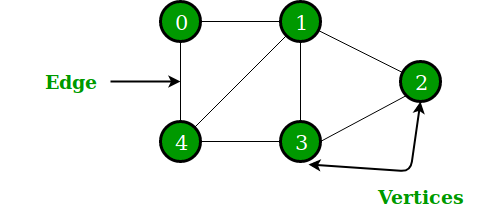
مصدر
مثال

ز = رسم بياني (4)
g.edge (0، 2)
g.edge (1، 3)
g.edge (3، 2)
g.edge (0، 3)
ز .__ repr __ ()
انتاج |
قائمة تجاور قمة الرأس 0
الرأس -> 3 -> 2
قائمة تجاور قمة الرأس 1
الرأس -> 3
قائمة تجاور قمة الرأس 2
الرأس -> 3 -> 0
قائمة تجاور قمة الرأس 3
الرأس -> 0 -> 2 -> 1
5. Hashmap
Hashmaps هي هياكل بيانات بيثون مفهرسة مفيدة لتخزين أزواج القيمة الرئيسية. يتم استرداد البيانات المخزنة في hashmaps من خلال المفاتيح التي يتم حسابها من خلال مساعدة وظيفة التجزئة. هذه الأنواع من هياكل البيانات مفيدة لتخزين بيانات الطلاب ، وتفاصيل العملاء ، وما إلى ذلك. القواميس في لغة بيثون هي مثال على hashmaps.
مثال

انتاج |
0 -> أولا
1 -> ثانية
2 -> الثالث
0 -> أولا
1 -> ثانية
2 -> الثالث
3 -> الرابع
0 -> أولا
1 -> ثانية
2 -> الثالث
فائدة
- إنها الطريقة الأكثر مرونة وموثوقية لاسترداد المعلومات من هياكل البيانات الأخرى.
6. القائمة المرتبطة
إنه نوع من بنية البيانات الخطية. في الأساس ، هي عبارة عن سلسلة من عناصر البيانات المرتبطة ببعضها البعض من خلال روابط في Python. العناصر الموجودة في قائمة مرتبطة متصلة من خلال المؤشرات. يشار إلى العقدة الأولى من بنية البيانات هذه بالرأس ويشار إلى العقدة الأخيرة باسم الذيل. لذلك ، تتكون القائمة المرتبطة من العقد التي تحتوي على قيم ، وتتكون كل عقدة من مؤشر مرتبط بعقدة أخرى.
فائدة القوائم المرتبطة
- مقارنة بالمصفوفة التي تم إصلاحها ، فإن القائمة المرتبطة هي شكل ديناميكي لإدخال البيانات. يتم حفظ الذاكرة لأنها تخصص ذاكرة العقد. أثناء التواجد في المصفوفة ، يجب تحديد الحجم مسبقًا ، مما يؤدي إلى إهدار الذاكرة.
- يمكن تخزين القائمة المرتبطة في أي مكان في الذاكرة. يمكن تحديث عقدة القائمة المرتبطة ونقلها إلى موقع مختلف.
الشكل 6: تمثيل رسومي لقائمة مرتبطة
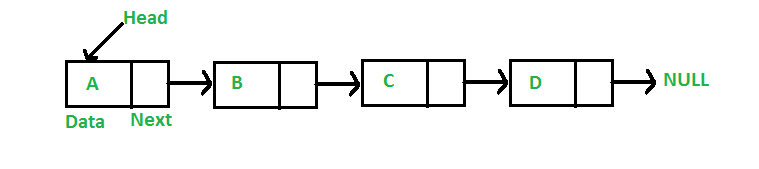
مصدر
مثال

انتاج:
['اول ثان ثالث']
["الأول" ، "الثاني" ، "الثالث" ، "السادس" ، "الرابع" ، "الخامس"]
["الأول" ، "الثالث" ، "السادس" ، "الرابع" ، "الخامس"]
خاتمة
تم استكشاف الأنواع المختلفة لهياكل البيانات في بيثون . سواء كنت مبتدئًا أو خبيرًا ، لا يمكن تجاهل هياكل البيانات والخوارزميات. أثناء إجراء أي شكل من أشكال العمليات على البيانات ، تلعب مفاهيم هياكل البيانات دورًا حيويًا. تساعد هياكل البيانات في تخزين المعلومات بطريقة منظمة ، بينما تساعد الخوارزميات في التوجيه خلال تحليل البيانات. لذلك ، تساعد كل من هياكل وخوارزميات بيانات Python عالم الكمبيوتر أو أي مستخدمين على معالجة بياناتهم.
إذا كنت مهتمًا بالتعرف على هياكل البيانات ، فراجع برنامج IIIT-B & upGrad التنفيذي PG في علوم البيانات الذي تم إنشاؤه للمهنيين العاملين ويقدم أكثر من 10 دراسات حالة ومشاريع ، وورش عمل عملية عملية ، وإرشاد مع خبراء الصناعة ، 1 - في 1 مع موجهين في الصناعة ، أكثر من 400 ساعة من التعلم والمساعدة في العمل مع الشركات الكبرى.
ما هي بنية البيانات الأسرع في Python؟
في القواميس ، تكون عمليات البحث أسرع لأن Python تستخدم جداول التجزئة لتنفيذها. إذا استخدمنا مفاهيم Big O لتوضيح التمييز ، فإن القواميس تمتلك تعقيدًا زمنيًا ثابتًا ، O (1) ، في حين أن القوائم لها تعقيد زمني خطي ، O (n).
في Python ، تعد القواميس أسرع طريقة للبحث عن البيانات التي تحتوي على آلاف الإدخالات بشكل متكرر. تم تحسين القواميس بشكل كبير لأنها من نوع الخرائط المضمنة في Python. ومع ذلك ، في القواميس والقوائم ، هناك مقايضة مشتركة بين المكان والزمان. إنه يشير إلى أنه بينما يمكننا تقليل الوقت المطلوب لنهجنا ، سنحتاج إلى استخدام مساحة أكبر للذاكرة.
في القوائم ، للحصول على ما تريد ، يجب أن تذهب من خلال القائمة الكاملة. من ناحية أخرى ، سيعيد القاموس القيمة التي تبحث عنها دون البحث في جميع المفاتيح.
أيهما أسرع في قائمة أو مصفوفة بايثون؟
بشكل عام ، تعد قوائم Python مرنة بشكل لا يصدق وقد تحتوي على بيانات عشوائية غير متجانسة تمامًا ، بالإضافة إلى إلحاقها بسرعة وفي وقت ثابت تقريبي. هم الطريق الذي يجب أن تسلكه إذا كنت بحاجة إلى تقليص حجم قائمتك وتوسيعها بسرعة وبدون ألم. ومع ذلك ، فإنها تشغل مساحة أكبر بكثير من المصفوفات ، ويرجع ذلك جزئيًا إلى أن كل عنصر في القائمة يتطلب إنشاء كائن Python منفصل.
من ناحية أخرى ، فإن نوع المصفوفة. Array هو في الأساس غلاف رفيع حول مصفوفات C. يمكن أن تحمل فقط بيانات متجانسة (أي بيانات من نفس النوع) ، وبالتالي تقتصر الذاكرة على حجم (كائن واحد) * بايت الطول.
ما هو الفرق بين مجموعة NumPy والقائمة؟
Numpy هي الحزمة الأساسية للحوسبة العلمية في Python. يستخدم كائن مصفوفة كبيرة متعددة الأبعاد بالإضافة إلى أدوات مساعدة لمعالجتها. المصفوفة العقدية هي شبكة من القيم من النوع المتطابق مفهرسة بواسطة مجموعة من الأعداد الصحيحة غير السالبة.
تم تضمين القوائم في مكتبة Python الأساسية. القائمة تشبه المصفوفة في بايثون ، ولكن يمكن تغيير حجمها وتحتوي على عناصر من أنواع مختلفة. ما هو الفرق الحقيقي هنا؟ الأداء هو الجواب. تعد هياكل البيانات Numpy أكثر كفاءة من حيث الحجم والأداء والوظائف.