
ورقة الغش النهائية لعلوم البيانات التي يجب أن يمتلكها علماء البيانات
نشرت: 2021-01-29لجميع هؤلاء المحترفين والمبتدئين الناشئين على حد سواء الذين يفكرون في الغوص في عالم علم البيانات المزدهر ، قمنا بتجميع ورقة غش سريعة لتجعلك مطلعًا على الأساسيات والمنهجيات التي تؤكد هذا المجال.
جدول المحتويات
علم البيانات - الأساسيات
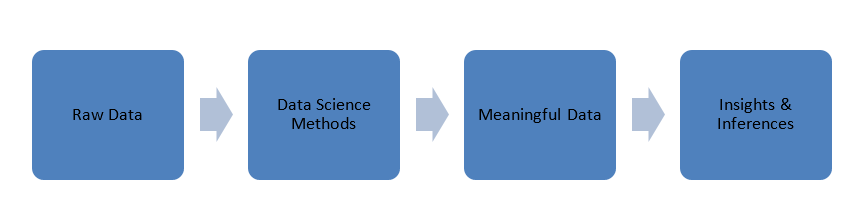
البيانات التي يتم إنشاؤها في عالمنا هي في شكل خام ، على سبيل المثال ، الأرقام ، الرموز ، الكلمات ، الجمل ، إلخ. يأخذ علم البيانات هذه البيانات الخام لمعالجتها باستخدام الأساليب العلمية لتحويلها إلى أشكال ذات مغزى لاكتساب المعرفة والرؤى .
بيانات
قبل أن نتعمق في مبادئ علم البيانات ، لنتحدث قليلاً عن البيانات وأنواعها ومعالجة البيانات.
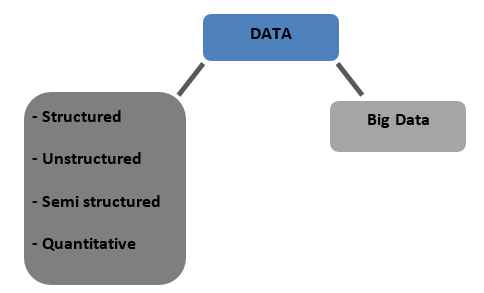
أنواع البيانات
منظم - البيانات التي يتم تخزينها بتنسيق مجدول في قواعد البيانات. يمكن أن تكون إما رقمية أو نصية
غير منظمة - تسمى البيانات التي لا يمكن جدولتها بأي بنية محددة يمكن التحدث عنها بالبيانات غير المهيكلة
شبه منظمة - بيانات مختلطة مع سمات البيانات المنظمة وغير المهيكلة
الكمية - البيانات ذات القيم الرقمية المحددة التي يمكن قياسها كمياً
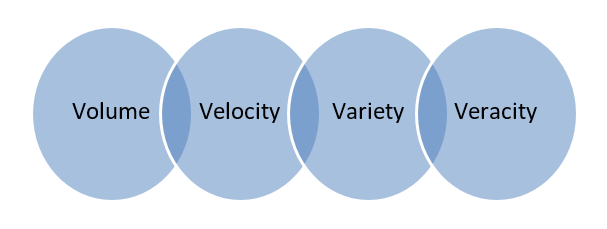
البيانات الكبيرة - البيانات المخزنة في قواعد بيانات ضخمة تغطي عدة أجهزة كمبيوتر أو مزارع خوادم تسمى البيانات الكبيرة. تعتبر البيانات البيومترية وبيانات الوسائط الاجتماعية وما إلى ذلك بيانات كبيرة. تتميز البيانات الضخمة بـ 4 فولت
معالجة البيانات
تصنيف البيانات - إنها عملية تصنيف البيانات أو تصنيفها إلى فئات مثل العددية أو النصية أو المصورة أو النص أو الفيديو ، إلخ.
تطهير البيانات - يتكون من إزالة البيانات المفقودة / غير المتسقة / غير المتوافقة أو استبدال البيانات باستخدام إحدى الطرق التالية.
- إقحام
- ارشادي
- تعيين عشوائي
- أقرب جار
إخفاء البيانات - إخفاء أو إخفاء البيانات السرية للحفاظ على خصوصية المعلومات الحساسة مع الاستمرار في معالجتها.
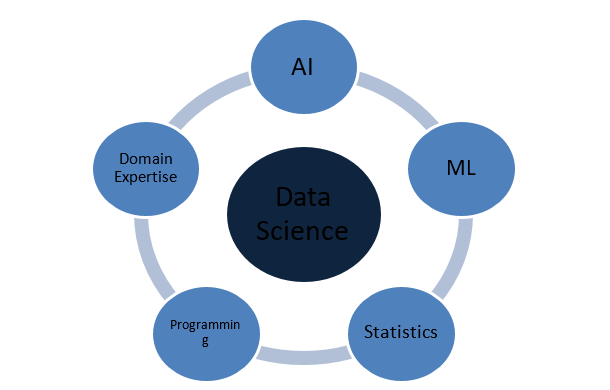
مما يتكون علم البيانات؟
مفاهيم الإحصاء
تراجع
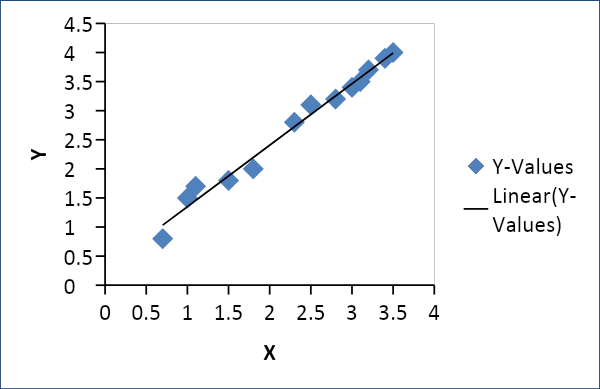
الانحدارالخطي
يُستخدم الانحدار الخطي لتأسيس علاقة بين متغيرين مثل العرض والطلب ، والسعر والاستهلاك ، وما إلى ذلك. وهو يربط متغيرًا واحدًا x كدالة خطية لمتغير آخر y على النحو التالي
ص = و (س) أو ص = م س + ج ، حيث م = معامل
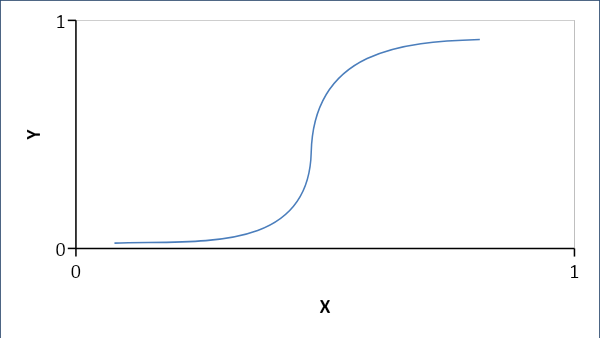
الانحدار اللوجستي
يؤسس الانحدار اللوجستي علاقة احتمالية بدلاً من علاقة خطية بين المتغيرات. الإجابة الناتجة هي إما 0 أو 1 ونبحث عن الاحتمالات والمنحنى على شكل حرف S.
إذا كانت p <0.5 ، فسيكون 0 آخر 1
معادلة:
ص = ه ^ (ب 0 + ب 1 س) / (1 + ه ^ (ب 0 + ب 1 س))
حيث b0 = تحيز و b1 = معامل
احتمالا
يساعد الاحتمال على التنبؤ باحتمالية حدوث حدث. بعض المصطلحات:
عينة: مجموعة النتائج المحتملة
الحدث: هي مجموعة فرعية من مساحة العينة
المتغير العشوائي: تساعد المتغيرات العشوائية في تعيين أو تحديد النتائج المحتملة للأرقام أو الخط في مساحة العينة
التوزيعات الاحتمالية
التوزيعات المنفصلة: تعطي الاحتمال كمجموعة من القيم المنفصلة (عدد صحيح)
ف [X = س] = ص (س)
 مصدر الصورة
مصدر الصورة
التوزيعات المستمرة: يعطي الاحتمال على عدد من النقاط أو الفواصل الزمنية المستمرة بدلاً من القيم المنفصلة. معادلة:
P [a ≤ x ≤ b] = a∫bf (x) dx ، حيث a ، b هي النقاط
مصدر الصورة
الارتباط والتغاير
الانحراف المعياري: الاختلاف أو الانحراف لمجموعة بيانات معينة عن قيمتها المتوسطة
σ = √ {(Σi = 1N (xi - x)) / (N -1)}
التغاير
يحدد مدى انحراف المتغيرات العشوائية X و Y مع متوسط مجموعة البيانات.
Cov (X، Y) = σ2XY = E [(X − μX) (Y − μY)] = E [XY] μX μY
علاقه مترابطه
يحدد الارتباط مدى العلاقة الخطية بين المتغيرات جنبًا إلى جنب مع اتجاهها ، + ve أو -ve
ρXY = σ2XY / σX * * σY
الذكاء الاصطناعي
تسمى قدرة الآلات على اكتساب المعرفة واتخاذ القرارات بناءً على المدخلات بالذكاء الاصطناعي أو ببساطة الذكاء الاصطناعي.
أنواع
- الآلات التفاعلية: يعمل الذكاء الاصطناعي الآلي التفاعلي من خلال تعلم كيفية التفاعل مع السيناريوهات المحددة مسبقًا من خلال التضييق على الخيارات الأسرع والأفضل. تفتقر إلى الذاكرة وهي الأفضل للمهام ذات مجموعة محددة من المعلمات. موثوق للغاية ومتسق.
- ذاكرة محدودة: يحتوي هذا الذكاء الاصطناعي على بعض البيانات الواقعية القائمة على المراقبة والبيانات القديمة التي يتم تغذيتها به. يمكنه التعلم واتخاذ القرارات بناءً على البيانات المعطاة ولكن لا يمكنه اكتساب خبرات جديدة.
- نظرية العقل: إنها ذكاء اصطناعي تفاعلي يمكنه اتخاذ القرارات بناءً على سلوك الكيانات المحيطة.
- الوعي الذاتي: هذا الذكاء الاصطناعي يدرك وجوده ويعمل بصرف النظر عن البيئة المحيطة. يمكنه تطوير القدرات المعرفية وفهم وتقييم تأثيرات أفعاله على البيئة المحيطة.
شروط الذكاء الاصطناعي
الشبكات العصبية
الشبكات العصبية هي مجموعة أو شبكة من العقد المترابطة التي تنقل البيانات والمعلومات في النظام. تم تصميم NNs لتقليد الخلايا العصبية في أدمغتنا ويمكن أن تتخذ القرارات عن طريق التعلم والتنبؤ.

الاستدلال
الاستدلال هو القدرة على التنبؤ بناءً على التقديرات والتقديرات بسرعة باستخدام الخبرة السابقة في المواقف التي تكون فيها المعلومات المتاحة غير مكتملة. إنه سريع ولكنه غير دقيق أو دقيق.
الاستدلال المبني على حالة
القدرة على التعلم من حالات حل المشكلات السابقة وتطبيقها في المواقف الحالية للوصول إلى حل مقبول
معالجة اللغة الطبيعية
إنها ببساطة قدرة الآلة على الفهم والتفاعل بشكل مباشر في الكلام أو النص البشري. على سبيل المثال ، أوامر صوتية في السيارة
التعلم الالي
التعلم الآلي هو ببساطة أحد تطبيقات الذكاء الاصطناعي باستخدام نماذج وخوارزميات مختلفة للتنبؤ بالمشكلات وحلها.
أنواع
إشراف
تعتمد هذه الطريقة على بيانات الإدخال المرتبطة ببيانات الإخراج. يتم تزويد الجهاز بمجموعة من المتغيرات المستهدفة Y ويجب أن تصل إلى المتغير المستهدف من خلال مجموعة من متغيرات الإدخال X تحت إشراف خوارزمية التحسين. من أمثلة التعلم الخاضع للإشراف الشبكات العصبية ، والغابات العشوائية ، والتعلم العميق ، وآلات المتجهات الداعمة ، وما إلى ذلك.
غير خاضع للرقابة
في هذه الطريقة ، لا تحتوي متغيرات الإدخال على تصنيف أو ارتباط ، وتعمل الخوارزميات على إيجاد أنماط ومجموعات تؤدي إلى معرفة ورؤى جديدة.
عززت
يركز التعلم المعزز على تقنيات الارتجال لصقل سلوك التعلم أو صقله. إنها طريقة تعتمد على المكافأة حيث تقوم الآلة تدريجياً بتحسين تقنياتها للفوز بمكافأة مستهدفة.
طرق النمذجة
تراجع
نماذج الانحدار تعطي دائمًا الأرقام كمخرجات من خلال الاستيفاء أو الاستقراء للبيانات المستمرة.
تصنيف
تأتي نماذج التصنيف بمخرجات كفئة أو تسمية وهي أفضل في توقع النتائج المنفصلة مثل "أي نوع"
كلا من الانحدار والتصنيف هي نماذج خاضعة للإشراف.
تجمع
التجميع هو نموذج غير خاضع للإشراف يحدد المجموعات بناءً على السمات والسمات والميزات وما إلى ذلك.
خوارزميات ML
أشجار القرار
تستخدم أشجار القرار نهجًا ثنائيًا للوصول إلى حل بناءً على الأسئلة المتتالية في كل مرحلة بحيث تكون النتيجة إما من السؤالين المحتملين مثل "نعم" أو "لا". أشجار القرار سهلة التنفيذ والتفسير.
غابة عشوائية أو تعبئة
Random Forest هي خوارزمية متقدمة لأشجار القرار. يستخدم عددًا كبيرًا من أشجار القرار مما يجعل الهيكل كثيفًا ومعقدًا مثل الغابة. إنه يولد نتائج متعددة وبالتالي يؤدي إلى نتائج وأداء أكثر دقة.
ك- أقرب الجار (KNN)
يستفيد kNN من قرب أقرب نقاط البيانات على قطعة الأرض بالنسبة لنقطة بيانات جديدة للتنبؤ بالفئة التي تقع فيها. يتم تعيين نقطة البيانات الجديدة للفئة مع عدد أكبر من الجيران.
ك = عدد أقرب الجيران
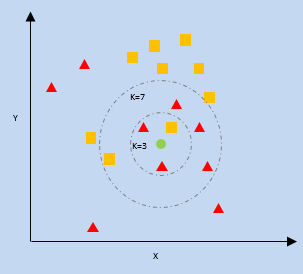
ساذج بايز
يعمل Naive Bayes على ركيزتين ، أولاً أن كل سمة من سمات نقاط البيانات مستقلة ، وغير مرتبطة ببعضها البعض ، أي فريدة ، وثانيًا على نظرية بايز التي تتنبأ بالنتائج بناءً على حالة أو فرضية.
مبرهنة بايز:
الفوسفور (س | ص) = {ف (ص | س) * ف (س)} / ف (ص)
حيث P (X | Y) = الاحتمال الشرطي لـ X نظرًا لحدوث Y
P (Y | X) = الاحتمال الشرطي لـ Y نظرًا لحدوث X
P (X) ، P (Y) = احتمالية X و Y بشكل فردي
دعم آلات المتجهات
تحاول هذه الخوارزمية فصل البيانات في الفضاء بناءً على الحدود التي يمكن أن تكون إما خطًا أو مستوى. تسمى هذه الحدود "المستوى الفائق" ويتم تحديدها من خلال أقرب نقاط البيانات لكل فئة والتي تسمى بدورها "متجهات الدعم". المسافة القصوى بين متجهات الدعم لأي جانب تسمى الهامش.
الشبكات العصبية
بيرسبترون
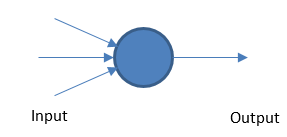
تعمل الشبكة العصبية الأساسية عن طريق أخذ المدخلات والمخرجات المرجحة بناءً على قيمة عتبة.
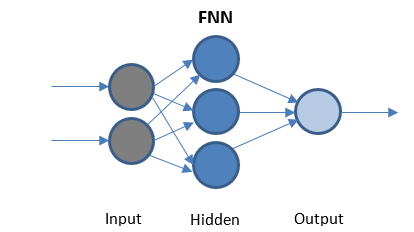
تغذية الشبكة العصبية إلى الأمام
FFN هي أبسط شبكة تنقل البيانات في اتجاه واحد فقط. قد يكون أو لا يحتوي على طبقات مخفية.
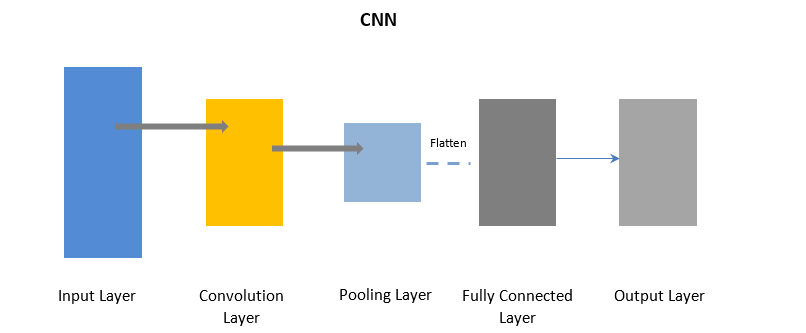
الشبكات العصبية التلافيفية
تستخدم CNN طبقة التفاف لمعالجة أجزاء معينة من بيانات الإدخال على دفعات متبوعة بطبقة تجميع لإكمال الإخراج.
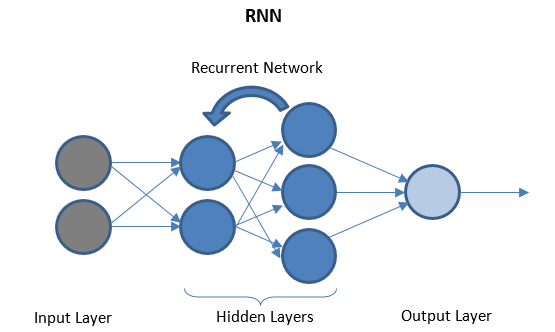
الشبكات العصبية المتكررة
يتكون RNN من بضع طبقات متكررة بين طبقات الإدخال / الإخراج التي يمكنها تخزين البيانات "التاريخية". تدفق البيانات ثنائي الاتجاه ويتم تغذيته للطبقات المتكررة لتحسين التنبؤات.
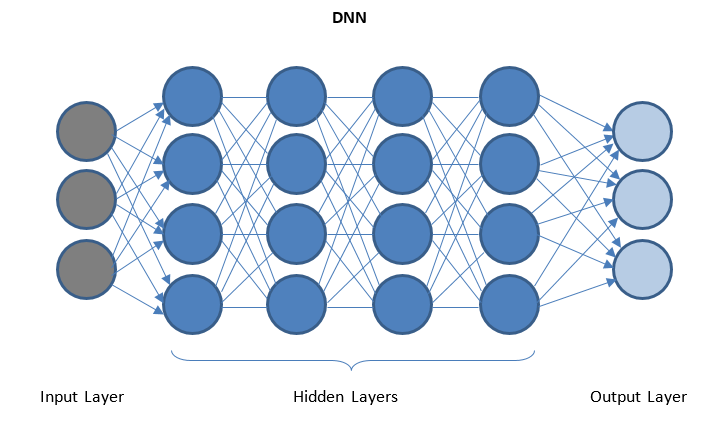
الشبكات العصبية العميقة والتعلم العميق
DNN عبارة عن شبكة ذات طبقات متعددة مخفية بين طبقات الإدخال / الإخراج. تطبق الطبقات المخفية عمليات تحويل متتالية على البيانات قبل إرسالها إلى طبقة الإخراج.
يتم تسهيل "التعلم العميق" من خلال DNN ويمكنه التعامل مع كميات هائلة من البيانات المعقدة وتحقيق دقة عالية بسبب الطبقات المخفية المتعددة
احصل على شهادة علوم البيانات من أفضل الجامعات في العالم. تعلم برامج PG التنفيذية أو برامج الشهادات المتقدمة أو برامج الماجستير لتتبع حياتك المهنية بشكل سريع.
خاتمة
علم البيانات هو مجال واسع يمر عبر تدفقات مختلفة ولكنه يأتي على شكل ثورة وكشف لنا. علم البيانات مزدهر وسيغير طريقة عمل أنظمتنا وشعورها في المستقبل.
إذا كنت مهتمًا بالتعرف على علوم البيانات ، فراجع دبلوم PG في IIIT-B & upGrad في علوم البيانات والذي تم إنشاؤه للمهنيين العاملين ويقدم أكثر من 10 دراسات حالة ومشاريع ، وورش عمل عملية عملية ، وإرشاد مع خبراء الصناعة ، 1- على - 1 مع موجهين في الصناعة ، وأكثر من 400 ساعة من التعلم والمساعدة في العمل مع الشركات الكبرى.
ما هي لغة البرمجة الأنسب لعلوم البيانات ولماذا؟
هناك العشرات من لغات البرمجة لعلوم البيانات ، لكن غالبية مجتمع علوم البيانات يعتقدون أنه إذا كنت ترغب في التفوق في علم البيانات ، فإن Python هي الخيار الصحيح المناسب. فيما يلي بعض الأسباب التي تدعم هذا الاعتقاد:
1. تحتوي Python على مجموعة واسعة من الوحدات النمطية والمكتبات مثل TensorFlow و PyTorch التي تجعل من السهل التعامل مع مفاهيم علوم البيانات.
2. يساعد مجتمع مطوري Python الواسع باستمرار المبتدئين على الانتقال إلى المرحلة التالية من رحلة علم البيانات الخاصة بهم.
3. تعد هذه اللغة إلى حد بعيد واحدة من أكثر اللغات ملاءمة وسهولة في الكتابة مع بنية نظيفة مما يحسن قابليتها للقراءة.
ما هي المفاهيم التي تجعل علم البيانات مكتملا؟
علم البيانات هو مجال واسع يعمل كمظلة لمختلف المجالات الحاسمة الأخرى. فيما يلي أبرز المفاهيم التي يتكون منها علم البيانات:
إحصائيات
الإحصاء هو مفهوم مهم يجب أن تتفوق فيه ، للمضي قدمًا في علم البيانات. كما أن لديها بعض الموضوعات الفرعية:
1. الانحدار الخطي
2. الاحتمال
3. التوزيع الاحتمالي
الذكاء الاصطناعي
يُعرف العلم الذي يوفر للآلات دماغًا والسماح لهم باتخاذ قراراتهم الخاصة بناءً على المدخلات بالذكاء الاصطناعي. الآلات التفاعلية ، والذاكرة المحدودة ، ونظرية العقل ، والوعي الذاتي هي بعض أنواع الذكاء الاصطناعي.
التعلم الالي
يعد التعلم الآلي مكونًا مهمًا آخر لعلوم البيانات يتعامل مع آلات التدريس للتنبؤ بالنتائج المستقبلية بناءً على البيانات المقدمة. يحتوي التعلم الآلي على ثلاث طرق نمذجة بارزة - التجميع والانحدار والتصنيف.
وصف أنواع التعلم الآلي؟
يحتوي التعلم الآلي أو تعلم الآلة البسيط على ثلاثة أنواع رئيسية تعتمد على أساليب عملها. هذه الأنواع هي كما يلي:
1. التعلم تحت الإشراف
هذا هو النوع الأكثر بدائية من ML حيث يتم تسمية بيانات الإدخال. يتم تزويد الجهاز بمجموعة أصغر من البيانات التي تعطي الجهاز نظرة ثاقبة للمشكلة ويتم تدريبها عليها.
2. التعلم غير الخاضع للإشراف
أكبر ميزة لهذا النوع هي أن البيانات غير موسومة هنا والعمل البشري يكاد لا يكاد يذكر. هذا يفتح الباب لمجموعات بيانات أكبر بكثير ليتم تقديمها إلى النموذج.
3. التعلم المعزز هذا هو النوع الأكثر تقدمًا من ML المستوحى من حياة البشر. يتم تعزيز النواتج المرغوبة بينما يتم تثبيط المخرجات غير المجدية.