
المعالجة المسبقة للبيانات في التعلم الآلي: 7 خطوات سهلة للمتابعة
نشرت: 2021-07-15تعد المعالجة المسبقة للبيانات في التعلم الآلي خطوة حاسمة تساعد على تحسين جودة البيانات لتعزيز استخراج رؤى ذات مغزى من البيانات. تشير المعالجة المسبقة للبيانات في التعلم الآلي إلى تقنية إعداد (تنظيف وتنظيم) البيانات الأولية لجعلها مناسبة لمبنى وتدريب نماذج التعلم الآلي. بكلمات بسيطة ، المعالجة المسبقة للبيانات في Machine Learning هي تقنية استخراج البيانات التي تحول البيانات الخام إلى تنسيق مفهوم وقابل للقراءة.
جدول المحتويات
لماذا المعالجة المسبقة للبيانات في التعلم الآلي؟
عندما يتعلق الأمر بإنشاء نموذج التعلم الآلي ، فإن المعالجة المسبقة للبيانات هي الخطوة الأولى التي تحدد بدء العملية. عادةً ما تكون بيانات العالم الحقيقي غير كاملة وغير متسقة وغير دقيقة (تحتوي على أخطاء أو قيم متطرفة) ، وغالبًا ما تفتقر إلى قيم / اتجاهات سمات محددة. هذا هو المكان الذي تدخل فيه المعالجة المسبقة للبيانات في السيناريو - فهي تساعد على تنظيف البيانات الأولية وتنسيقها وتنظيمها ، مما يجعلها جاهزة للعمل لنماذج التعلم الآلي. دعنا نستكشف الخطوات المختلفة للمعالجة المسبقة للبيانات في التعلم الآلي.
انضم إلى دورة الذكاء الاصطناعي عبر الإنترنت من أفضل الجامعات في العالم - الماجستير ، وبرامج الدراسات العليا التنفيذية ، وبرنامج الشهادات المتقدمة في ML & AI لتسريع مسار حياتك المهنية.
خطوات المعالجة المسبقة للبيانات في التعلم الآلي
هناك سبع خطوات مهمة في المعالجة المسبقة للبيانات في التعلم الآلي:
1. الحصول على مجموعة البيانات
يعد الحصول على مجموعة البيانات الخطوة الأولى في المعالجة المسبقة للبيانات في التعلم الآلي. لإنشاء نماذج التعلم الآلي وتطويرها ، يجب أن تحصل أولاً على مجموعة البيانات ذات الصلة. ستتألف مجموعة البيانات هذه من البيانات التي تم جمعها من مصادر متعددة ومتباينة والتي يتم دمجها بعد ذلك في تنسيق مناسب لتشكيل مجموعة بيانات. تختلف تنسيقات مجموعة البيانات وفقًا لحالات الاستخدام. على سبيل المثال ، ستكون مجموعة البيانات التجارية مختلفة تمامًا عن مجموعة البيانات الطبية. بينما ستحتوي مجموعة بيانات الأعمال على بيانات الصناعة والأعمال ذات الصلة ، ستشمل مجموعة البيانات الطبية البيانات المتعلقة بالرعاية الصحية.
هناك العديد من المصادر عبر الإنترنت حيث يمكنك تنزيل مجموعات البيانات مثل https://www.kaggle.com/uciml/datasets و https://archive.ics.uci.edu/ml/index.php . يمكنك أيضًا إنشاء مجموعة بيانات من خلال جمع البيانات عبر واجهات برمجة تطبيقات Python المختلفة. بمجرد أن تصبح مجموعة البيانات جاهزة ، يجب عليك وضعها في تنسيقات ملفات CSV أو HTML أو XLSX.

2. استيراد جميع المكتبات الهامة
نظرًا لأن Python هي المكتبة الأكثر استخدامًا والأكثر تفضيلًا من قِبل علماء البيانات حول العالم ، فسوف نوضح لك كيفية استيراد مكتبات Python للمعالجة المسبقة للبيانات في التعلم الآلي. اقرأ المزيد عن مكتبات Python لعلوم البيانات هنا. يمكن لمكتبات Python المحددة مسبقًا تنفيذ مهام معالجة بيانات محددة مسبقًا. يعد استيراد جميع المكتبات المهمة هو الخطوة الثانية في المعالجة المسبقة للبيانات في التعلم الآلي. مكتبات Python الأساسية الثلاثة المستخدمة في المعالجة المسبقة للبيانات في التعلم الآلي هي:
- NumPy - NumPy هي الحزمة الأساسية للحسابات العلمية في Python. ومن ثم ، يتم استخدامه لإدخال أي نوع من العمليات الحسابية في الكود. باستخدام NumPy ، يمكنك أيضًا إضافة مصفوفات ومصفوفات كبيرة متعددة الأبعاد في التعليمات البرمجية الخاصة بك.
- Pandas - Pandas هي مكتبة بايثون ممتازة مفتوحة المصدر لمعالجة البيانات وتحليلها. يتم استخدامه على نطاق واسع لاستيراد مجموعات البيانات وإدارتها. يحزم في هياكل بيانات عالية الأداء وسهلة الاستخدام وأدوات تحليل البيانات لبايثون.
- Matplotlib - Matplotlib هي مكتبة تخطيط Python ثنائية الأبعاد تُستخدم لرسم أي نوع من المخططات في Python. يمكنه تقديم أرقام جودة النشر في العديد من تنسيقات النسخ المطبوعة والبيئات التفاعلية عبر الأنظمة الأساسية (قذائف IPython ، دفتر Jupyter ، خوادم تطبيقات الويب ، إلخ).
قراءة : أفكار مشروع التعلم الآلي للمبتدئين
3. استيراد مجموعة البيانات
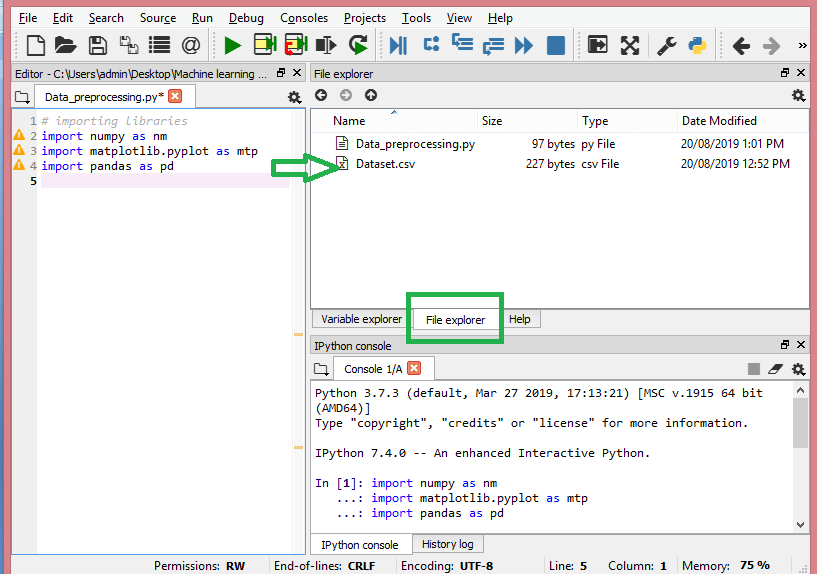
في هذه الخطوة ، تحتاج إلى استيراد مجموعة / مجموعات البيانات التي جمعتها لمشروع ML في متناول اليد. يعد استيراد مجموعة البيانات إحدى الخطوات المهمة في المعالجة المسبقة للبيانات في التعلم الآلي. ومع ذلك ، قبل أن تتمكن من استيراد مجموعة / مجموعات البيانات ، يجب عليك تعيين الدليل الحالي كدليل العمل. يمكنك ضبط دليل العمل في Spyder IDE في ثلاث خطوات بسيطة:
- احفظ ملف Python في الدليل الذي يحتوي على مجموعة البيانات.
- انتقل إلى خيار File Explorer في Spyder IDE واختر الدليل المطلوب.
- الآن ، انقر فوق الزر F5 أو خيار التشغيل لتنفيذ الملف.
مصدر
هذه هي الطريقة التي يجب أن يبدو عليها دليل العمل.
بمجرد تعيين دليل العمل الذي يحتوي على مجموعة البيانات ذات الصلة ، يمكنك استيراد مجموعة البيانات باستخدام وظيفة "read_csv ()" في مكتبة Pandas. يمكن لهذه الوظيفة قراءة ملف CSV (إما محليًا أو من خلال عنوان URL) وأيضًا إجراء عمليات مختلفة عليه. تتم كتابة read_csv () على النحو التالي:
data_set = pd.read_csv ("Dataset.csv")
في هذا السطر من التعليمات البرمجية ، تشير "data_set" إلى اسم المتغير الذي قمت بتخزين مجموعة البيانات فيه. تحتوي الوظيفة أيضًا على اسم مجموعة البيانات. بمجرد تنفيذ هذا الرمز ، سيتم استيراد مجموعة البيانات بنجاح.
أثناء عملية استيراد مجموعة البيانات ، هناك شيء أساسي آخر يجب عليك القيام به - استخراج المتغيرات التابعة والمستقلة. لكل نموذج من نماذج التعلم الآلي ، من الضروري فصل المتغيرات المستقلة (مصفوفة الميزات) والمتغيرات التابعة في مجموعة البيانات.
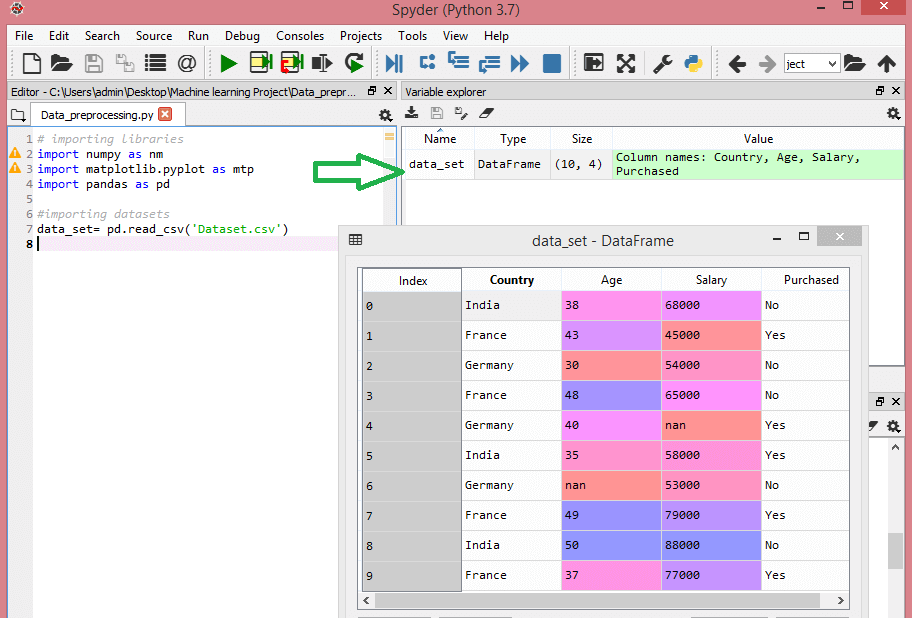
ضع في اعتبارك مجموعة البيانات هذه:
مصدر
تحتوي مجموعة البيانات هذه على ثلاثة متغيرات مستقلة - البلد والعمر والراتب ومتغير تابع واحد - تم شراؤه.
كيف تستخرج المتغيرات المستقلة؟
لاستخراج المتغيرات المستقلة ، يمكنك استخدام وظيفة "iloc []" في مكتبة Pandas. يمكن لهذه الوظيفة استخراج الصفوف والأعمدة المحددة من مجموعة البيانات.
x = data_set.iloc [:،: - 1] .values
في سطر التعليمات البرمجية أعلاه ، تأخذ النقطتان الأولى (:) بعين الاعتبار جميع الصفوف والنقطتان الثانية (:) تأخذ في الاعتبار جميع الأعمدة. يحتوي الكود على ": -1" حيث يتعين عليك استبعاد العمود الأخير الذي يحتوي على المتغير التابع. من خلال تنفيذ هذا الرمز ، ستحصل على مصفوفة الميزات ، مثل هذا -
[['الهند' 38.0 68000.0]
['فرنسا' 43.0 45000.0]
["ألمانيا" 30.0 54000.0]
["فرنسا" 48.0 65000.0]
["ألمانيا" 40.0 نان]
['India' 35.0 58000.0]
["ألمانيا" nan 53000.0]
["فرنسا" 49.0 79000.0]
["الهند" 50.0 88000.0]
["فرنسا" 37.0 77000.0]]
كيف تستخرج المتغير التابع؟
يمكنك استخدام وظيفة "iloc []" لاستخراج المتغير التابع أيضًا. إليك كيف تكتبها:
y = data_set.iloc [:، 3] .values
يعتبر هذا السطر من التعليمات البرمجية جميع الصفوف التي تحتوي على العمود الأخير فقط. من خلال تنفيذ الكود أعلاه ، ستحصل على مجموعة من المتغيرات التابعة ، مثل -
مصفوفة (["لا" ، "نعم" ، "لا" ، "لا" ، "نعم" ، "نعم" ، "لا" ، "نعم" ، "لا" ، "نعم"] ،
نوع dtype = كائن)
4. تحديد ومعالجة القيم المفقودة
في المعالجة المسبقة للبيانات ، من المهم تحديد القيم المفقودة ومعالجتها بشكل صحيح ، وفي حالة عدم القيام بذلك ، قد تستخلص استنتاجات واستنتاجات غير دقيقة وخاطئة من البيانات. وغني عن القول أن هذا سيعيق مشروع ML الخاص بك.
في الأساس ، هناك طريقتان للتعامل مع البيانات المفقودة:
- حذف صف معين - في هذه الطريقة ، تقوم بإزالة صف معين يحتوي على قيمة فارغة لميزة أو عمود معين حيث يكون أكثر من 75٪ من القيم مفقودة. ومع ذلك ، فإن هذه الطريقة ليست فعالة بنسبة 100٪ ، ويوصى باستخدامها فقط عندما تحتوي مجموعة البيانات على عينات مناسبة. يجب عليك التأكد من عدم وجود إضافة تحيز بعد حذف البيانات.
- حساب المتوسط - هذه الطريقة مفيدة للميزات التي تحتوي على بيانات رقمية مثل العمر والراتب والسنة وما إلى ذلك. هنا ، يمكنك حساب المتوسط أو الوسيط أو الوضع لميزة معينة أو عمود أو صف يحتوي على قيمة مفقودة واستبدال نتيجة للقيمة المفقودة. يمكن أن تضيف هذه الطريقة تباينًا إلى مجموعة البيانات ، ويمكن إبطال أي فقد للبيانات بكفاءة. ومن ثم ، فإنها تعطي نتائج أفضل مقارنة بالطريقة الأولى (حذف الصفوف / الأعمدة). طريقة أخرى للتقريب هي من خلال انحراف القيم المجاورة. ومع ذلك ، فإن هذا يعمل بشكل أفضل مع البيانات الخطية.
قراءة: تطبيقات تطبيقات التعلم الآلي باستخدام السحابة
5. ترميز البيانات الفئوية
تشير البيانات الفئوية إلى المعلومات التي تحتوي على فئات محددة ضمن مجموعة البيانات. في مجموعة البيانات المذكورة أعلاه ، هناك نوعان من المتغيرات الفئوية - البلد والمشتراة.
تعتمد نماذج التعلم الآلي بشكل أساسي على المعادلات الرياضية. وبالتالي ، يمكنك أن تفهم بشكل بديهي أن الاحتفاظ بالبيانات الفئوية في المعادلة سيؤدي إلى مشاكل معينة لأنك ستحتاج فقط إلى أرقام في المعادلات.
كيف يتم ترميز متغير الدولة؟
كما هو موضح في مثال مجموعة البيانات الخاصة بنا ، سيتسبب عمود البلد في حدوث مشكلات ، لذلك يجب عليك تحويله إلى قيم عددية. للقيام بذلك ، يمكنك استخدام فئة LabelEncoder () من مكتبة التعلم sci-kit. سيكون الرمز على النحو التالي -
# بيانات كاتدورية
# لمتغير البلد
من sklearn.preprocessing استيراد LabelEncoder
label_encoder_x = LabelEncoder ()
x [:، 0] = label_encoder_x.fit_transform (x [:، 0])
وسيكون الناتج -
الخارج [15]:
مجموعة ([2، 38.0، 68000.0]،
[0 ، 43.0 ، 45000.0] ،
[1 ، 30.0 ، 54000.0] ،
[0 ، 48.0 ، 65000.0] ،
[1 ، 40.0 ، 65222.22222222222] ،
[2، 35.0، 58000.0] ،
[1، 41.111111111111114، 53000.0] ،
[0 ، 49.0 ، 79000.0] ،
[2 ، 50.0 ، 88000.0] ،
[0 ، 37.0 ، 77000.0]] ، النوع = كائن)
هنا يمكننا أن نرى أن فئة LabelEncoder قد نجحت في ترميز المتغيرات إلى أرقام. ومع ذلك ، هناك متغيرات الدولة التي تم ترميزها كـ 0 و 1 و 2 في الإخراج الموضح أعلاه. لذلك ، قد يفترض نموذج ML أن هناك بعض الارتباط بين المتغيرات الثلاثة ، مما ينتج عنه ناتج خاطئ. للتخلص من هذه المشكلة ، سنستخدم الآن التشفير الوهمي.
المتغيرات الوهمية هي تلك التي تأخذ القيم 0 أو 1 للإشارة إلى غياب أو وجود تأثير قاطع محدد يمكن أن يغير النتيجة. في هذه الحالة ، تشير القيمة 1 إلى وجود هذا المتغير في عمود معين بينما تصبح المتغيرات الأخرى ذات قيمة 0. في الترميز الوهمي ، يساوي عدد الأعمدة عدد الفئات.
نظرًا لأن مجموعة البيانات الخاصة بنا تتكون من ثلاث فئات ، فإنها ستنتج ثلاثة أعمدة لها القيمتان 0 و 1. بالنسبة إلى التشفير الوهمي ، سنستخدم فئة OneHotEncoder في مكتبة scikit-Learn. سيكون كود الإدخال على النحو التالي -
# لمتغير البلد
من sklearn.preprocessing استيراد LabelEncoder ، OneHotEncoder
label_encoder_x = LabelEncoder ()
x [:، 0] = label_encoder_x.fit_transform (x [:، 0])
# ترميز المتغيرات الوهمية
onehot_encoder = OneHotEncoder (categorical_features = [0])
س = onehot_encoder.fit_transform (x) .toarray ()
عند تنفيذ هذا الرمز ، ستحصل على الإخراج التالي -
صفيف ([0.00000000e + 00 ، 0.00000000e + 00 ، 1.00000000e + 00 ، 3.80000000e + 01 ،
6.80000000e + 04] ،
[1.00000000e + 00 ، 0.00000000e + 00 ، 0.00000000e + 00 ، 4.30000000e + 01 ،
4.50000000e + 04] ،
[0.00000000e + 00 ، 1.00000000e + 00 ، 0.00000000e + 00 ، 3.00000000e + 01 ،

5.40000000e + 04] ،
[1.00000000e + 00 ، 0.00000000e + 00 ، 0.00000000e + 00 ، 4.80000000e + 01 ،
6.50000000e + 04] ،
[0.00000000e + 00 ، 1.00000000e + 00 ، 0.00000000e + 00 ، 4.00000000e + 01 ،
6.52222222e + 04] ،
[0.00000000e + 00 ، 0.00000000e + 00 ، 1.00000000e + 00 ، 3.50000000e + 01 ،
5.80000000e + 04] ،
[0.00000000e + 00 ، 1.00000000e + 00 ، 0.00000000e + 00 ، 4.11111111e + 01 ،
5.30000000e + 04] ،
[1.00000000e + 00 ، 0.00000000e + 00 ، 0.00000000e + 00 ، 4.90000000e + 01 ،
7.90000000e + 04] ،
[0.00000000e + 00 ، 0.00000000e + 00 ، 1.00000000e + 00 ، 5.00000000e + 01 ،
8.80000000e + 04] ،
[1.00000000e + 00 ، 0.00000000e + 00 ، 0.00000000e + 00 ، 3.70000000e + 01 ،
7.70000000e + 04]])
في الإخراج الموضح أعلاه ، يتم تقسيم جميع المتغيرات إلى ثلاثة أعمدة ومشفرة في القيمتين 0 و 1.
كيف يتم ترميز المتغير الذي تم شراؤه؟
بالنسبة للمتغير الفئوي الثاني ، أي الذي تم شراؤه ، يمكنك استخدام كائن "labelencoder" لفئة LableEncoder. لا نستخدم فئة OneHotEncoder نظرًا لأن المتغير الذي تم شراؤه يحتوي على فئتين فقط نعم أو لا ، وكلاهما مشفر في 0 و 1.
سيكون رمز الإدخال لهذا المتغير -
labelencoder_y = LabelEncoder ()
y = labelencoder_y.fit_transform (y)
سيكون الإخراج -
خارج [17]: صفيف ([0 ، 1 ، 0 ، 0 ، 1 ، 1 ، 0 ، 1 ، 0 ، 1])
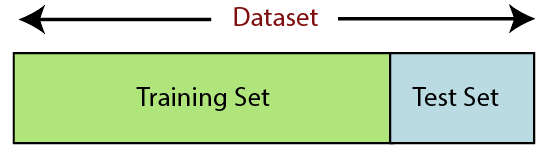
6. تقسيم مجموعة البيانات
يعد تقسيم مجموعة البيانات الخطوة التالية في المعالجة المسبقة للبيانات في التعلم الآلي. يجب تقسيم كل مجموعة بيانات لنموذج التعلم الآلي إلى مجموعتين منفصلتين - مجموعة التدريب ومجموعة الاختبار.
مصدر
تشير مجموعة التدريب إلى المجموعة الفرعية لمجموعة البيانات المستخدمة لتدريب نموذج التعلم الآلي. هنا ، أنت على علم بالفعل بالإخراج. مجموعة الاختبار ، من ناحية أخرى ، هي مجموعة فرعية من مجموعة البيانات المستخدمة لاختبار نموذج التعلم الآلي. يستخدم نموذج ML مجموعة الاختبار للتنبؤ بالنتائج.
عادة ، يتم تقسيم مجموعة البيانات إلى نسبة 70:30 أو نسبة 80:20. هذا يعني أنك تأخذ 70٪ أو 80٪ من البيانات لتدريب النموذج بينما تترك الباقي 30٪ أو 20٪. تختلف عملية التقسيم حسب شكل وحجم مجموعة البيانات المعنية.
لتقسيم مجموعة البيانات ، يجب عليك كتابة السطر التالي من التعليمات البرمجية -
من sklearn.model_selection استيراد train_test_split
x_train، x_test، y_train، y_test = train_test_split (x، y، test_size = 0.2، random_state = 0)
هنا ، يقسم السطر الأول مصفوفات مجموعة البيانات إلى مجموعات فرعية للقطار والاختبار العشوائي. يتضمن السطر الثاني من الكود أربعة متغيرات:
- x_train - ميزات لبيانات التدريب
- x_test - ميزات لبيانات الاختبار
- y_train - المتغيرات التابعة لبيانات التدريب
- y_test - متغير مستقل لاختبار البيانات
وبالتالي ، فإن الدالة train_test_split () تتضمن أربع معلمات ، أول اثنتين منها مخصصة لمصفوفات البيانات. تحدد وظيفة test_size حجم مجموعة الاختبار. حجم_الاختبار ربما .5 أو .3 أو .2 - وهذا يحدد نسبة القسمة بين مجموعات التدريب والاختبار. تحدد المعلمة الأخيرة ، "random_state" ، البذور لمولد عشوائي بحيث يكون الناتج دائمًا هو نفسه.
7. ميزة التحجيم
يشير مقياس الميزة إلى نهاية المعالجة المسبقة للبيانات في التعلم الآلي. إنها طريقة لتوحيد المتغيرات المستقلة لمجموعة البيانات ضمن نطاق معين. بمعنى آخر ، يحد مقياس الميزة من نطاق المتغيرات بحيث يمكنك مقارنتها على أسس مشتركة.
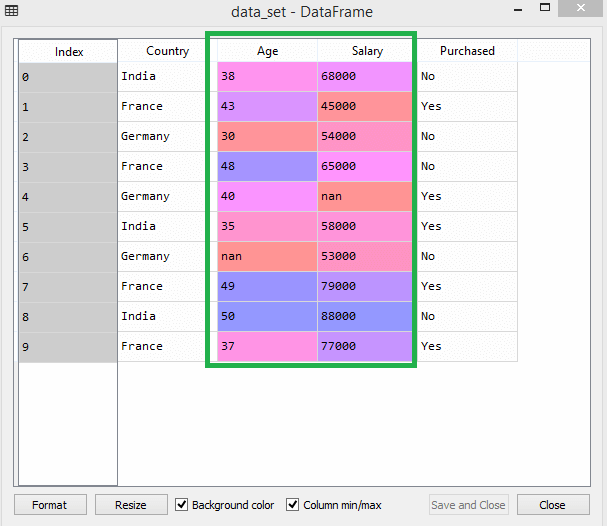
ضع في اعتبارك مجموعة البيانات هذه على سبيل المثال -
مصدر
في مجموعة البيانات ، يمكنك ملاحظة أن أعمدة العمر والراتب لا تحتوي على نفس المقياس. في مثل هذا السيناريو ، إذا قمت بحساب أي قيمتين من عمودي العمر والراتب ، فسوف تهيمن قيم المرتب على قيم العمر وتقدم نتائج غير صحيحة. وبالتالي ، يجب عليك إزالة هذه المشكلة عن طريق إجراء تحجيم الميزات لتعلم الآلة.
تعتمد معظم نماذج ML على المسافة الإقليدية ، والتي يتم تمثيلها على النحو التالي:
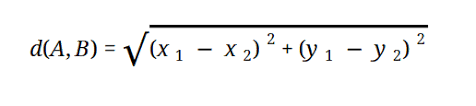
مصدر
يمكنك إجراء تحجيم الميزات في التعلم الآلي بطريقتين:
التوحيد
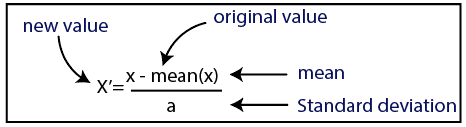
مصدر
تطبيع
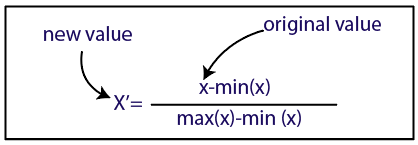
مصدر
بالنسبة لمجموعة البيانات الخاصة بنا ، سوف نستخدم طريقة التوحيد القياسي. للقيام بذلك ، سنقوم باستيراد فئة StandardScaler من مكتبة sci-kit-Learn باستخدام السطر التالي من التعليمات البرمجية:
من sklearn.preprocessing استيراد StandardScaler
ستكون الخطوة التالية هي إنشاء كائن من فئة StandardScaler للمتغيرات المستقلة. بعد ذلك ، يمكنك ملاءمة مجموعة بيانات التدريب وتحويلها باستخدام الكود التالي:
st_x = StandardScaler ()
x_train = st_x.fit_transform (x_train)
بالنسبة لمجموعة بيانات الاختبار ، يمكنك تطبيق وظيفة التحويل () مباشرةً (لا تحتاج إلى استخدام وظيفة fit_transform () لأنها تم إجراؤها بالفعل في مجموعة التدريب). سيكون الرمز على النحو التالي -
x_test = st_x.transform (x_test)
سيُظهر إخراج مجموعة بيانات الاختبار القيم المقاسة لـ x_train و x_test على النحو التالي:
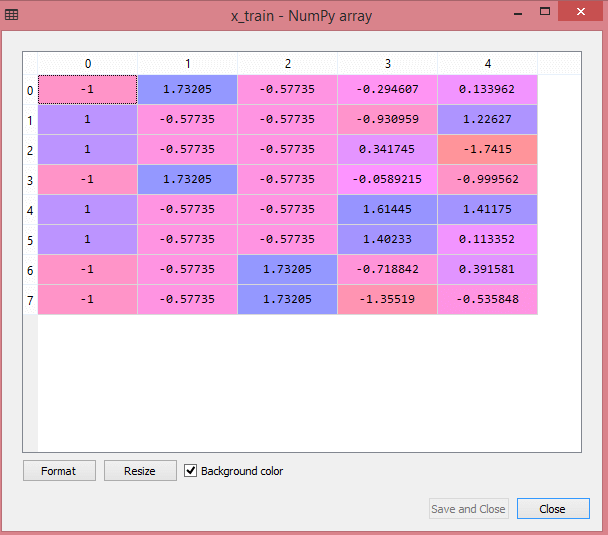
مصدر
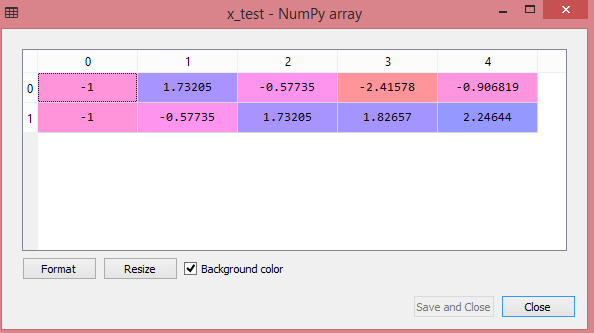
مصدر
يتم قياس جميع المتغيرات في الإخراج بين القيم -1 و 1.
الآن ، لدمج جميع الخطوات التي قمنا بها حتى الآن ، تحصل على:
# استيراد مكتبات
استيراد numpy مثل نانومتر
استيراد matplotlib.pyplot كـ mtp
استيراد الباندا كما pd
# استيراد مجموعات البيانات
data_set = pd.read_csv ("Dataset.csv")
# استخراج المتغير المستقل
x = data_set.iloc [:،: -1] .values
#Extracting المتغير التابع
y = data_set.iloc [:، 3] .values
# معالجة البيانات المفقودة (استبدال البيانات المفقودة بالقيمة المتوسطة)
من sklearn.preprocessing استيراد Imputer
Imputer = Imputer (مفقود_القيم = 'NaN' ، الإستراتيجية = 'متوسط' ، المحور = 0)
# تركيب الكائن الحاجب على المتغيرات المستقلة x.
imputerimputer = imputer.fit (x [:، 1: 3])
# استبدال البيانات المفقودة بمتوسط القيمة المحسوبة
x [:، 1: 3] = imputer.transform (x [:، 1: 3])
# لمتغير البلد
من sklearn.preprocessing استيراد LabelEncoder ، OneHotEncoder
label_encoder_x = LabelEncoder ()
x [:، 0] = label_encoder_x.fit_transform (x [:، 0])
# ترميز المتغيرات الوهمية
onehot_encoder = OneHotEncoder (categorical_features = [0])
س = onehot_encoder.fit_transform (x) .toarray ()
#encoding للمتغير المشتراة
labelencoder_y = LabelEncoder ()
y = labelencoder_y.fit_transform (y)
# تقسيم مجموعة البيانات إلى مجموعة تدريب واختبار.
من sklearn.model_selection استيراد train_test_split
x_train، x_test، y_train، y_test = train_test_split (x، y، test_size = 0.2، random_state = 0)
#F Feature تحجيم مجموعات البيانات
من sklearn.preprocessing استيراد StandardScaler
st_x = StandardScaler ()
x_train = st_x.fit_transform (x_train)
x_test = st_x.transform (x_test)
إذن ، هذه هي معالجة البيانات في "التعلم الآلي" باختصار!
يمكنك التحقق من برنامج PG التنفيذي في IIT Delhi في التعلم الآلي والذكاء الاصطناعي بالاشتراك مع upGrad . IIT دلهي هي واحدة من أعرق المؤسسات في الهند. مع أكثر من 500 عضو من أعضاء هيئة التدريس الداخليين وهم الأفضل في الموضوعات.
ما هي أهمية معالجة البيانات؟
نظرًا لأن الأخطاء والتكرار والقيم المفقودة والتناقضات جميعها تعرض سلامة مجموعة البيانات للخطر ، فيجب عليك معالجتها جميعًا للحصول على نتيجة أكثر دقة. افترض أنك تستخدم مجموعة بيانات معيبة لتدريب نظام التعلم الآلي للتعامل مع مشتريات عملائك. من المحتمل أن ينتج عن النظام تحيزات وانحرافات ، مما يؤدي إلى تجربة مستخدم سيئة. نتيجة لذلك ، قبل استخدام هذه البيانات للغرض المقصود ، يجب أن تكون منظمة و "نظيفة" قدر الإمكان. اعتمادًا على نوع الصعوبة التي تتعامل معها ، هناك العديد من الخيارات.
ما هو تنظيف البيانات؟
من شبه المؤكد أنه ستكون هناك بيانات مفقودة وصاخبة في مجموعات البيانات الخاصة بك. نظرًا لأن إجراء جمع البيانات ليس مثاليًا ، سيكون لديك الكثير من المعلومات غير المفيدة والمفقودة. تنظيف البيانات هو الطريقة التي يجب أن تستخدمها للتعامل مع هذه المشكلة. يمكن تقسيم هذا إلى فئتين. الأول يناقش كيفية التعامل مع البيانات المفقودة. يمكنك اختيار تجاهل القيم المفقودة في هذا القسم من مجموعة البيانات (تسمى المجموعة). الطريقة الثانية لتنظيف البيانات هي البيانات الصاخبة. من الأهمية بمكان التخلص من البيانات غير المفيدة التي لا يمكن للأنظمة قراءتها إذا كنت تريد أن تتم العملية برمتها بسلاسة.
ماذا تقصد بتحويل البيانات وتقليلها؟
تنتقل المعالجة المسبقة للبيانات إلى مرحلة التحول بعد التعامل مع المخاوف. يمكنك استخدامه لتحويل البيانات إلى مطابقة ذات صلة للتحليل. التطبيع ، واختيار السمات ، والتقدير ، وإنشاء التسلسل الهرمي للمفهوم هي بعض الأساليب التي يمكن استخدامها لتحقيق ذلك. حتى بالنسبة للطرق الآلية ، قد يستغرق غربلة مجموعات البيانات الكبيرة وقتًا طويلاً. هذا هو السبب في أن مرحلة تقليل البيانات أمر بالغ الأهمية: فهي تقلل من حجم مجموعات البيانات عن طريق قصرها على المعلومات الأكثر أهمية ، وزيادة كفاءة التخزين مع تقليل النفقات المالية والوقتية للعمل معهم.