
CNN مقابل RNN: الفرق بين CNN و RNN
نشرت: 2021-02-25جدول المحتويات
مقدمة
في مجال الذكاء الاصطناعي ، تُستخدم الشبكات العصبية المستوحاة من الدماغ البشري على نطاق واسع في استخراج ومعالجة المعلومات المعقدة من البيانات المختلفة واستخدام كل من الشبكات العصبية التلافيفية (CNN) والشبكات العصبية المتكررة (RNN) في مثل هذه التطبيقات تثبت أنها مفيدة.
في هذه المقالة ، يجب أن نفهم المفاهيم الكامنة وراء كل من الشبكات العصبية التلافيفية والشبكات العصبية المتكررة ، ونرى تطبيقاتها ونميز الاختلافات بين كلا النوعين الشائعين من الشبكات العصبية.
تعلم تدريب التعلم الآلي من أفضل الجامعات في العالم. احصل على درجة الماجستير أو برنامج PGP التنفيذي أو برامج الشهادات المتقدمة لتسريع مسار حياتك المهنية.
الشبكات العصبية والتعلم العميق
قبل أن ندخل في مفاهيم كل من الشبكات العصبية التلافيفية والشبكات العصبية المتكررة ، دعونا نفهم المفاهيم الكامنة وراء الشبكات العصبية وكيف ترتبط بالتعلم العميق.
في الآونة الأخيرة ، أصبح التعلم العميق مفهومًا يستخدم على نطاق واسع في العديد من المجالات ، وبالتالي فهو موضوع ساخن هذه الأيام. ولكن ما هو سبب الحديث عنها على نطاق واسع؟ للإجابة على هذا السؤال ، سنتعرف على مفهوم الشبكات العصبية.
باختصار ، الشبكات العصبية هي العمود الفقري للتعلم العميق. إنها مجموعة من الطبقات تتكون من عناصر شديدة الترابط تُعرف باسم الخلايا العصبية التي تقوم بسلسلة من التحولات على البيانات التي تولد فهمها الخاص لتلك البيانات التي نشير إليها بالمصطلح ، السمات.

ما هي الشبكات العصبية؟
المفهوم الأول الذي نحتاج إلى تجاوزه هو مفهوم الشبكات العصبية. نحن نعلم أن الدماغ البشري هو أحد الهياكل المعقدة التي تمت دراستها على الإطلاق. نظرًا لتعقيدها ، كانت هناك صعوبة كبيرة في كشف أعمالها الداخلية ولكن في الوقت الحاضر ، يتم إجراء عدة أنواع من البحث للكشف عن أسرارها. يعمل هذا الدماغ البشري كمصدر إلهام وراء نماذج الشبكة العصبية.
بحكم التعريف ، الشبكات العصبية هي الوحدات الوظيفية للتعلم العميق التي تستخدم هذه الشبكات العصبية لتقليد نشاط الدماغ وحل المشكلات المعقدة. عندما يتم تغذية بيانات الإدخال إلى الشبكة العصبية ، تتم معالجتها من خلال طبقات الإدراك الحسي وأخيراً تعطي المخرجات.
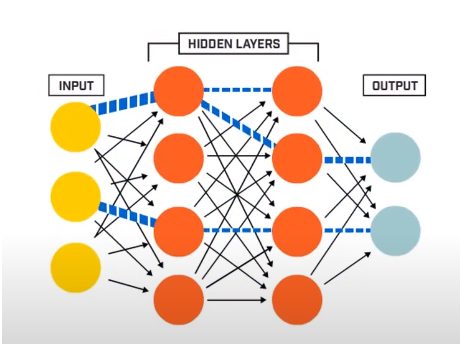
تتكون الشبكة العصبية بشكل أساسي من 3 طبقات -
- طبقة الإدخال
- طبقات مخفية
- طبقة الإخراج
تقرأ طبقة الإدخال بيانات الإدخال التي يتم إدخالها في نظام الشبكة العصبية لمزيد من المعالجة المسبقة بواسطة الطبقات اللاحقة من الخلايا العصبية الاصطناعية. جميع الطبقات الموجودة بين طبقة الإدخال وطبقة الإخراج تسمى الطبقات المخفية.
في هذه الطبقات المخفية ، تستفيد الخلايا العصبية الموجودة فيها من المدخلات المرجحة والتحيزات وتنتج مخرجات باستخدام وظائف التنشيط. طبقة المخرجات هي الطبقة الأخيرة من الخلايا العصبية التي تعطينا مخرجات البرنامج المحدد.
مصدر
كيف تعمل الشبكات العصبية؟
الآن بعد أن أصبح لدينا فكرة عن الهيكل الأساسي للشبكات العصبية ، سنمضي قدمًا ونفهم كيفية عملها. لفهم عملها ، علينا أولاً التعرف على أحد الهياكل الأساسية للشبكات العصبية ، والمعروفة باسم Perceptron.
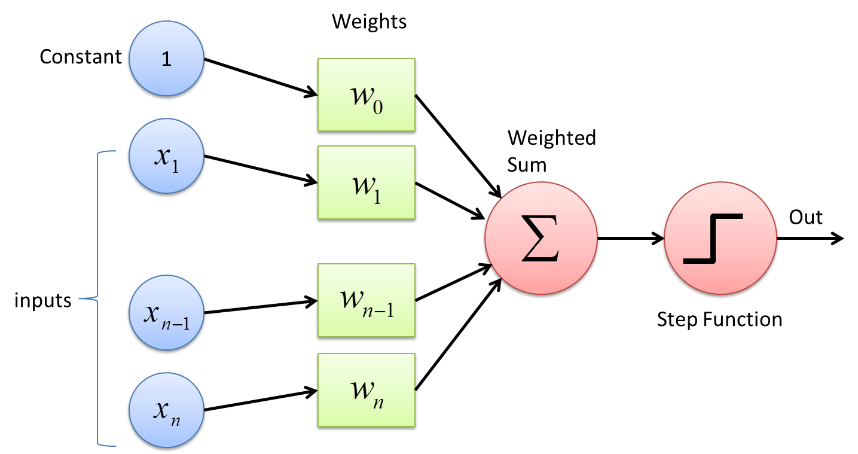
Perceptron هو نوع من الشبكات العصبية وهو أبسط شكل. إنها شبكة عصبية اصطناعية بسيطة مع طبقة مخفية واحدة فقط. في شبكة Perceptron ، يتم توصيل كل خلية عصبية مع كل خلية عصبية أخرى في الاتجاه الأمامي.
يتم ترجيح الروابط بين هذه الخلايا العصبية بسبب تقوية المعلومات التي يتم نقلها بين الخلايا العصبية أو تخفيفها بواسطة هذه الأوزان. في عملية تدريب الشبكات العصبية ، يتم تعديل هذه الأوزان للحصول على القيمة الصحيحة.
يستخدم Perceptron وظيفة مصنف ثنائي حيث يتم تعيين متجه من المتغيرات التي تكون ثنائية بطبيعتها إلى ناتج ثنائي واحد. يمكن أيضًا استخدام هذا في التعلم الخاضع للإشراف. الخطوات في خوارزمية التعلم Perceptron هي -
- اضرب جميع المدخلات بأوزانها w ، حيث w هي أرقام حقيقية يمكن أن تكون ثابتة أو عشوائية في البداية.
- أضف الناتج معًا للحصول على المجموع المرجح ∑ wj xj
- بمجرد الحصول على المجموع المرجح للمدخلات ، يتم تطبيق وظيفة التنشيط لتحديد ما إذا كان المبلغ المرجح أكبر من قيمة حد معينة أم لا اعتمادًا على وظيفة التنشيط المطبقة. يتم تعيين الإخراج على أنه 1 أو 0 وفقًا لشرط العتبة. هنا تشير القيمة "-threshold" أيضًا إلى مصطلح التحيز ، ب.
بهذه الطريقة ، يمكن استخدام خوارزمية التعلم Perceptron لإطلاق (القيمة = 1) الخلايا العصبية الموجودة في الشبكات العصبية التي تم تصميمها وتطويرها اليوم. تمثيل آخر لخوارزمية التعلم Perceptron هو -
و (س) = 1 ، إذا ∑ wj xj + b ≥ 0
0 ، إذا ∑ wj xj + b <0
على الرغم من عدم استخدام Perceptrons على نطاق واسع في الوقت الحاضر ، إلا أنه لا يزال أحد المفاهيم الأساسية في الشبكات العصبية. في مزيد من البحث ، كان من المفهوم أن التغييرات الصغيرة في أي من الأوزان أو التحيز حتى في إدراك واحد يمكن أن تغير الناتج بشكل كبير من 1 إلى 0 أو العكس. كان هذا أحد العيوب الرئيسية لـ Perceptron. وبالتالي ، تم تطوير وظائف التنشيط الأكثر تعقيدًا مثل ReLU والوظائف السينية التي تقدم فقط تغييرات معتدلة في أوزان وتحيز الخلايا العصبية الاصطناعية.
مصدر
الشبكات العصبية التلافيفية
الشبكة العصبية التلافيفية هي خوارزمية التعلم العميق التي تأخذ صورة كمدخل ، وتخصص أوزانًا وتحيزات مختلفة لأجزاء مختلفة من الصورة بحيث تكون مختلفة عن بعضها البعض. بمجرد أن تصبح قابلة للتفاضل ، باستخدام وظائف التنشيط المختلفة ، يمكن أن يؤدي نموذج الشبكة العصبية التلافيفية العديد من المهام في مجال معالجة الصور بما في ذلك التعرف على الصور وتصنيف الصور واكتشاف الكائن والوجه وما إلى ذلك.
إن أساس نموذج الشبكة العصبية التلافيفية هو أنه يتلقى صورة إدخال. يمكن تسمية صورة الإدخال (مثل قطة ، كلب ، أسد ، إلخ) أو غير موسومة. بناءً على ذلك ، يتم تصنيف خوارزميات التعلم العميق إلى نوعين هما الخوارزميات الخاضعة للإشراف حيث يتم تسمية الصور والخوارزميات غير الخاضعة للإشراف حيث لا يتم إعطاء الصور أي تسمية معينة.
بالنسبة لجهاز الكمبيوتر ، يُنظر إلى صورة الإدخال على أنها مصفوفة من البكسلات ، وغالبًا ما تكون في شكل مصفوفة. الصور في الغالب من الشكل hxwxd (حيث h = الارتفاع ، w = العرض ، d = البعد). على سبيل المثال ، تشير صورة بحجم 16 × 16 × 3 مصفوفة مصفوفة إلى صورة RGB (3 ترمز إلى قيم RGB). من ناحية أخرى ، تمثل صورة مصفوفة 14 × 14 × 1 صورة ذات تدرج رمادي.

مصدر
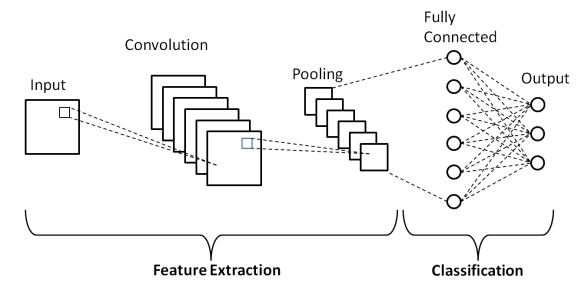
طبقات الشبكة العصبية التلافيفية
كما هو موضح في البنية الأساسية للشبكة العصبية التلافيفية أعلاه ، يتكون نموذج CNN من عدة طبقات تخضع خلالها الصور المدخلة للمعالجة المسبقة للحصول على المخرجات. في الأساس ، يتم تمييز هذه الطبقات إلى جزأين -
- الطبقات الثلاث الأولى بما في ذلك طبقة الإدخال وطبقة الالتفاف وطبقة التجميع التي تعمل كأداة لاستخراج المعالم لاشتقاق ميزات المستوى الأساسي من الصور التي يتم إدخالها في النموذج.
- تستفيد الطبقة النهائية المتصلة بالكامل وطبقة الإخراج من إخراج طبقات استخراج الميزة وتتنبأ بفئة للصورة اعتمادًا على الميزات المستخرجة.
الطبقة الأولى هي طبقة الإدخال حيث يتم تغذية الصورة في نموذج الشبكة العصبية التلافيفية في شكل مصفوفة ، أي 32 × 32 × 3 ، حيث تشير 3 إلى أن الصورة عبارة عن صورة RGB ذات ارتفاع وعرض متساويين 32 بكسل. بعد ذلك ، تمر صور الإدخال هذه عبر الطبقة التلافيفية حيث يتم تنفيذ العملية الرياضية للالتفاف.
يتم تحويل صورة الإدخال إلى مصفوفة مربعة أخرى تُعرف بالنواة أو المرشح. من خلال تحريك النواة واحدًا تلو الآخر فوق وحدات البكسل الخاصة بالصورة المدخلة ، نحصل على صورة الإخراج المعروفة باسم خريطة المعالم التي توفر معلومات حول ميزات المستوى الأساسي للصورة مثل الحواف والخطوط.
الطبقة التلافيفية تتبعها طبقة التجميع التي تهدف إلى تقليل حجم خريطة المعالم لتقليل التكلفة الحسابية. يتم ذلك عن طريق عدة أنواع من التجميع مثل Max Pooling و Average Pooling و Sum Pooling.
طبقة الاتصال الكامل (FC) هي الطبقة قبل الأخيرة من نموذج الشبكة العصبية التلافيفية حيث يتم تسطيح الطبقات وتغذيتها إلى طبقة FC. هنا ، باستخدام وظائف التنشيط مثل وظائف Sigmoid و ReLU و tanH ، يتم توقع التسمية ويتم تقديمها في طبقة الإخراج النهائية .
حيث تقصر شبكة سي إن إن
مع وجود العديد من التطبيقات المفيدة للشبكة العصبية التلافيفية في بيانات الصور المرئية ، فإن شبكات CNN لديها عيب بسيط من حيث أنها لا تعمل بشكل جيد مع سلسلة من الصور (مقاطع الفيديو) وتفشل في تفسير المعلومات الزمنية وكتل النص.
من أجل التعامل مع البيانات الزمنية أو المتسلسلة مثل الجمل ، نحتاج إلى خوارزميات تتعلم من البيانات السابقة وكذلك البيانات المستقبلية في التسلسل. لحسن الحظ ، فإن الشبكات العصبية المتكررة تفعل ذلك بالضبط.
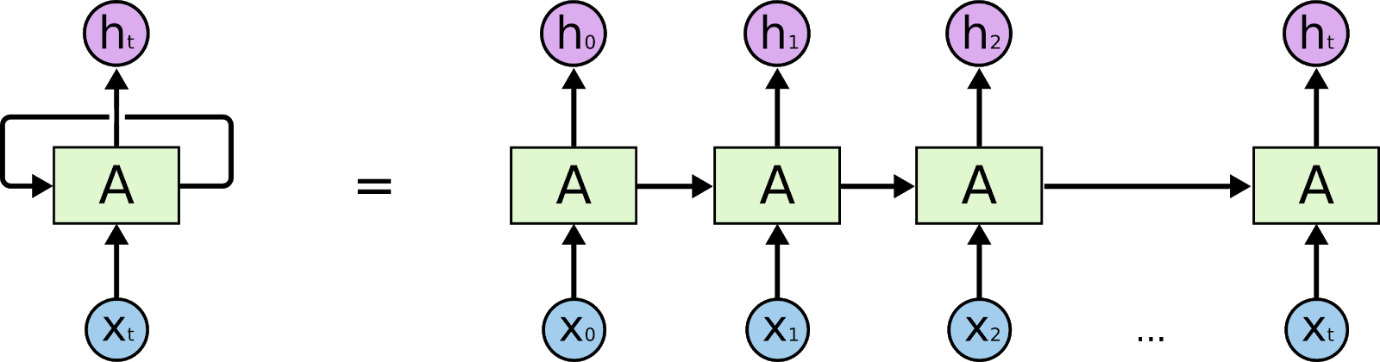
الشبكات العصبية المتكررة
الشبكات العصبية المتكررة هي شبكات مصممة لتفسير المعلومات الزمنية أو المتسلسلة. تستخدم RNNs نقاط بيانات أخرى في تسلسل لعمل تنبؤات أفضل. يفعلون ذلك عن طريق أخذ المدخلات وإعادة استخدام تنشيط العقد السابقة أو العقد اللاحقة في التسلسل للتأثير على المخرجات.
مصدر
نتيجة لذاكرتها الداخلية ، يمكن للشبكات العصبية المتكررة أن تتذكر التفاصيل الحيوية مثل المدخلات التي تلقتها ، مما يجعلها دقيقة للغاية في التنبؤ بما سيأتي بعد ذلك. وبالتالي ، فهي الخوارزمية الأكثر تفضيلاً للبيانات المتسلسلة مثل السلاسل الزمنية والكلام والنصوص والصوت والفيديو وغيرها الكثير. يمكن للشبكات العصبية المتكررة تكوين فهم أعمق بكثير للتسلسل وسياقه مقارنة بالخوارزميات الأخرى.
كيف تعمل الشبكات العصبية المتكررة؟
إن قاعدة فهم العمل على الشبكات العصبية المتكررة هي نفسها المستخدمة في الشبكات العصبية التلافيفية ، وهي الشبكات العصبية البسيطة ذات التغذية الأمامية ، والمعروفة أيضًا باسم Perceptron. بالإضافة إلى ذلك ، في الشبكات العصبية المتكررة ، يتم تغذية الإخراج من الخطوة السابقة كمدخل إلى الخطوة الحالية. في معظم الشبكات العصبية ، يكون الإخراج عادةً مستقلاً عن المدخلات والعكس صحيح ، وهذا هو الفرق الأساسي بين RNN والشبكات العصبية الأخرى.
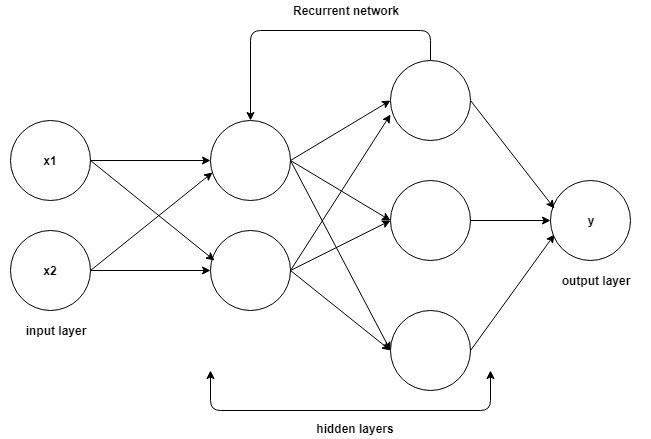
مصدر
لذلك ، يحتوي RNN على مدخلين: الحاضر والماضي القريب. هذا مهم لأن تسلسل البيانات يحتوي على معلومات مهمة حول ما سيأتي بعد ذلك ، ولهذا السبب يمكن لـ RNN القيام بأشياء لا تستطيع الخوارزميات الأخرى القيام بها. الميزة الرئيسية والأكثر أهمية للشبكات العصبية المتكررة هي الحالة المخفية ، التي تتذكر بعض المعلومات حول التسلسل.
تحتوي الشبكات العصبية المتكررة على ذاكرة تخزن جميع المعلومات حول ما تم حسابه. باستخدام نفس المعلمات لكل إدخال وتنفيذ نفس المهمة على جميع المدخلات أو الطبقات المخفية ، يتم تقليل تعقيد المعلمات.
الفرق بين CNN و RNN
| الشبكات العصبية التلافيفية | الشبكات العصبية المتكررة |
| في التعلم العميق ، الشبكة العصبية التلافيفية (CNN ، أو ConvNet) هي فئة من الشبكات العصبية العميقة ، الأكثر شيوعًا في تحليل الصور المرئية. | الشبكة العصبية المتكررة (RNN) هي فئة من الشبكات العصبية الاصطناعية حيث تشكل الاتصالات بين العقد رسمًا بيانيًا موجهًا على طول تسلسل زمني. |
| وهي مناسبة للبيانات المكانية مثل الصور. | يتم استخدام RNN للبيانات الزمنية ، وتسمى أيضًا البيانات المتسلسلة. |
| CNN هي نوع من الشبكات العصبية الاصطناعية ذات التغذية الأمامية مع أشكال مختلفة من الإدراك الحسي متعدد الطبقات المصممة لاستخدام كميات قليلة من المعالجة المسبقة. | يمكن لـ RNN ، على عكس الشبكات العصبية للتغذية الأمامية ، استخدام ذاكرتها الداخلية لمعالجة التسلسلات التعسفية للمدخلات. |
| تعتبر CNN أقوى من RNN. | تتضمن RNN توافقًا أقل للميزات عند مقارنتها بـ CNN. |
| تأخذ CNN مدخلات ذات أحجام ثابتة وتولد مخرجات ذات حجم ثابت. | يمكن لـ RNN معالجة أطوال الإدخال / الإخراج التعسفية. |
| تعد شبكات CNN مثالية لمعالجة الصور والفيديو. | RNNs مثالية لتحليل النص والكلام. |
| تشمل التطبيقات التعرف على الصور وتصنيف الصور وتحليل الصور الطبية واكتشاف الوجه ورؤية الكمبيوتر. | تشمل التطبيقات ترجمة النصوص ومعالجة اللغة الطبيعية وترجمة اللغة وتحليل المشاعر وتحليل الكلام. |
خاتمة
وهكذا ، في هذه المقالة حول الاختلافات بين النوعين الأكثر شيوعًا من الشبكات العصبية ، الشبكات العصبية التلافيفية والشبكات العصبية المتكررة ، تعلمنا البنية الأساسية للشبكة العصبية ، جنبًا إلى جنب مع أساسيات كل من CNN و RNN ، وأخيراً قمنا بتلخيص مقارنة موجزة بينهما مع تطبيقاتهما في العالم الحقيقي.
إذا كنت مهتمًا بمعرفة المزيد عن التعلم الآلي ، فراجع برنامج IIIT-B & upGrad's Executive PG في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة ومهمة ، IIIT -ب حالة الخريجين ، 5+ مشاريع التخرج العملية العملية والمساعدة في العمل مع الشركات الكبرى.
لماذا CNN أسرع من RNN؟
تعد شبكات CNN أسرع من شبكات RNN لأنها مصممة للتعامل مع الصور ، بينما تم تصميم شبكات RNN للتعامل مع النص. بينما يمكن تدريب RNNs على التعامل مع الصور ، لا يزال من الصعب عليهم فصل الميزات المتباينة القريبة من بعضها البعض. على سبيل المثال ، إذا كانت لديك صورة لوجه بعينين وأنف وفم ، فإن RNNs تواجه صعوبة في اكتشاف الميزة التي يجب عرضها أولاً. تستخدم شبكات CNN شبكة من النقاط ، وباستخدام خوارزمية ، يمكن تدريبهم على التعرف على الأشكال والأنماط. تعد شبكات CNN أفضل من شبكات RNN في فرز الصور ؛ إنها أسرع من RNNs لأنها سهلة الحساب ، وهي أفضل في فرز الصور.
ما هي ال RNN المستخدمة؟
الشبكات العصبية المتكررة (RNNs) هي فئة من الشبكات العصبية الاصطناعية حيث تشكل الاتصالات بين الوحدات دورة موجهة. يصبح إخراج إحدى الوحدات مدخلات وحدة أخرى وما إلى ذلك ، تمامًا مثل إخراج إحدى الخلايا العصبية التي تصبح مدخلات أخرى. تم استخدام RNNs بنجاح للقيام بمهام معقدة ، مثل التعرف على الكلام والترجمة الآلية ، التي يصعب تنفيذها بالطرق القياسية.
ما هي RNN وكيف تختلف عن Feedforward Neural Networks؟
الشبكات العصبية المتكررة (RNNs) هي نوع من الشبكات العصبية التي تستخدم لمعالجة البيانات المتسلسلة. تتكون الشبكة العصبية المتكررة من طبقة إدخال وطبقة مخفية واحدة أو أكثر وطبقة إخراج. تم تصميم الطبقة (الطبقات) المخفية لتعلم التمثيلات الداخلية لبيانات الإدخال ، والتي يتم تقديمها بعد ذلك إلى طبقة الإخراج كتمثيل خارجي. يتم تدريب RNN بمساعدة backpropagation. غالبًا ما تتم مقارنة شبكات RNN مع الشبكات العصبية المغذية (FNNs). بينما يمكن لكل من RNNs و FNNs تعلم التمثيلات الداخلية للبيانات ، فإن RNNs قادرة على تعلم التبعيات طويلة الأجل ، والتي لا تستطيع FNNs القيام بها.