
بناء خدمة تسجيل مركزية في المنزل
نشرت: 2022-03-10نعلم جميعًا مدى أهمية تصحيح الأخطاء في تحسين أداء التطبيق وميزاته. يدير BrowserStack مليون جلسة في اليوم على حزمة تطبيقات موزعة بشكل كبير! يتضمن كل منها عدة أجزاء متحركة ، حيث يمكن لجلسة العميل الفردية أن تمتد على مكونات متعددة عبر مناطق جغرافية متعددة.
بدون الإطار والأدوات المناسبة ، يمكن أن تكون عملية تصحيح الأخطاء كابوسًا. في حالتنا ، كنا بحاجة إلى طريقة لجمع الأحداث التي تحدث خلال مراحل مختلفة من كل عملية من أجل الحصول على فهم متعمق لكل شيء يحدث خلال الجلسة. مع بنيتنا التحتية ، أصبح حل هذه المشكلة معقدًا حيث قد يكون لكل مكون أحداث متعددة من دورة حياته الخاصة بمعالجة الطلب.
لهذا السبب قمنا بتطوير أداة خدمة التسجيل المركزي (CLS) الداخلية الخاصة بنا لتسجيل جميع الأحداث المهمة التي يتم تسجيلها أثناء الجلسة. تساعد هذه الأحداث مطورينا على تحديد الظروف التي يحدث فيها خطأ ما في الجلسة وتساعد في تتبع بعض مقاييس المنتج الرئيسية.
تتراوح بيانات تصحيح الأخطاء من أشياء بسيطة مثل زمن استجابة واجهة برمجة التطبيقات (API) إلى مراقبة سلامة شبكة المستخدم. في هذه المقالة ، نشارك قصتنا الخاصة ببناء أداة CLS الخاصة بنا والتي تجمع 70 جرامًا من البيانات الزمنية ذات الصلة يوميًا من أكثر من 100 مكون بشكل موثوق ، وعلى نطاق واسع ومثالي EC2 كبيرتين M3.
قرار البناء في المنزل
أولاً ، دعنا نفكر في سبب قيامنا ببناء أداة CLS داخل الشركة بدلاً من استخدام حل موجود. ترسل كل جلسة من جلساتنا 15 حدثًا في المتوسط ، من مكونات متعددة إلى الخدمة - تترجم إلى ما يقرب من 15 مليون حدث إجمالي يوميًا.
احتاجت خدمتنا إلى القدرة على تخزين كل هذه البيانات. لقد سعينا إلى إيجاد حل كامل لدعم تخزين الأحداث وإرسالها والاستعلام عنها عبر الأحداث. نظرًا لأننا نظرنا في حلول الجهات الخارجية مثل Amplitude و Keen ، فقد تضمنت مقاييس التقييم لدينا التكلفة والأداء في التعامل مع الطلبات المتوازية العالية وسهولة التبني. لسوء الحظ ، لم نتمكن من العثور على التوافق الذي يلبي جميع متطلباتنا في حدود الميزانية - على الرغم من أن الفوائد كانت ستشمل توفير الوقت وتقليل التنبيهات. في حين أن الأمر سيستغرق جهدًا إضافيًا ، فقد قررنا تطوير حل داخلي بأنفسنا.

تفاصيل تقنية
فيما يتعلق بتصميم مكوننا ، حددنا المتطلبات الأساسية التالية:
- أداء العميل
لا يؤثر على أداء العميل / المكون الذي يرسل الأحداث. - مقياس
قادرة على التعامل مع عدد كبير من الطلبات في نفس الوقت. - أداء الخدمة
سريع لمعالجة جميع الأحداث التي يتم إرسالها إليه. - نظرة ثاقبة البيانات
يحتاج كل حدث تم تسجيله إلى الحصول على بعض المعلومات الوصفية لتتمكن من تحديد المكون أو المستخدم أو الحساب أو الرسالة بشكل فريد وتقديم المزيد من المعلومات لمساعدة المطور على تصحيح الأخطاء بشكل أسرع. - واجهة الاستعلام
يمكن للمطورين الاستعلام عن جميع الأحداث لجلسة معينة ، مما يساعد في تصحيح أخطاء جلسة معينة ، أو إنشاء تقارير سلامة المكونات ، أو إنشاء إحصاءات أداء مفيدة لأنظمتنا. - اعتماد أسرع وأسهل
سهولة التكامل مع مكون موجود أو جديد دون إثقال كاهل الفرق واستهلاك مواردها. - صيانة منخفضة
نحن فريق هندسي صغير ، لذلك بحثنا عن حل لتقليل التنبيهات!
بناء حل CLS لدينا
القرار 1: اختيار واجهة لفضح
أثناء تطوير CLS ، من الواضح أننا لم نرغب في فقد أي من بياناتنا ، لكننا لم نرغب في أن يتأثر أداء المكون أيضًا. ناهيك عن العامل الإضافي المتمثل في منع المكونات الحالية من أن تصبح أكثر تعقيدًا ، حيث سيؤدي ذلك إلى تأخير التبني والإصدار بشكل عام. عند تحديد واجهتنا ، أخذنا في الاعتبار الخيارات التالية:
- تخزين الأحداث في Redis المحلي في كل مكون ، حيث يدفعها معالج الخلفية إلى CLS. ومع ذلك ، يتطلب هذا تغييرًا في جميع المكونات ، جنبًا إلى جنب مع تقديم Redis للمكونات التي لم تحتوي عليها بالفعل.
- نموذج الناشر - المشترك ، حيث يكون Redis أقرب إلى CLS. عندما ينشر الجميع الأحداث ، لدينا مرة أخرى عامل المكونات الذي يعمل في جميع أنحاء العالم. خلال وقت الازدحام الشديد ، قد يؤدي ذلك إلى تأخير المكونات. علاوة على ذلك ، يمكن أن تقفز هذه الكتابة بشكل متقطع تصل إلى خمس ثوان (بسبب الإنترنت وحده).
- إرسال الأحداث عبر UDP ، مما يوفر تأثيرًا أقل على أداء التطبيق. في هذه الحالة ، سيتم إرسال البيانات ونسيانها ، ومع ذلك ، فإن العيب هنا هو فقدان البيانات.
ومن المثير للاهتمام ، أن فقدان البيانات عبر UDP كان أقل من 0.1 بالمائة ، وهو مبلغ مقبول بالنسبة لنا للنظر في إنشاء مثل هذه الخدمة. تمكنا من إقناع جميع الفرق بأن هذا القدر من الخسارة يستحق الأداء ، ومضينا قدمًا للاستفادة من واجهة UDP التي تستمع إلى جميع الأحداث التي يتم إرسالها.
على الرغم من أن إحدى النتائج كانت ذات تأثير أقل على أداء التطبيق ، إلا أننا واجهنا مشكلة حيث لم يتم السماح بحركة مرور UDP من جميع الشبكات ، ومعظمها من مستخدمينا - مما تسبب في بعض الحالات في عدم تلقي أي بيانات على الإطلاق. كحل بديل ، قمنا بدعم أحداث التسجيل باستخدام طلبات HTTP. سيتم إرسال جميع الأحداث القادمة من جانب المستخدم عبر HTTP ، في حين أن جميع الأحداث التي يتم تسجيلها من مكوناتنا ستكون عبر UDP.
القرار 2: Tech Stack (اللغة والإطار والتخزين)
نحن متجر روبي. ومع ذلك ، لم نكن متأكدين مما إذا كان روبي سيكون خيارًا أفضل لمشكلتنا الخاصة. يجب أن تتعامل خدمتنا مع الكثير من الطلبات الواردة ، فضلاً عن معالجة الكثير من عمليات الكتابة. مع قفل Global Interpreter ، سيكون تحقيق تعدد مؤشرات الترابط أو التزامن أمرًا صعبًا في Ruby (من فضلك لا تأخذ أي مخالفة - نحن نحب Ruby!). لذلك كنا بحاجة إلى حل من شأنه أن يساعدنا في تحقيق هذا النوع من التزامن.
كنا حريصين أيضًا على تقييم لغة جديدة في مجموعتنا التقنية ، وبدا هذا المشروع مثاليًا لتجربة أشياء جديدة. هذا عندما قررنا إعطاء Golang فرصة لأنه قدم دعمًا داخليًا للتزامن والخيوط خفيفة الوزن وإجراءات الانتقال. تمثل كل نقطة بيانات مسجلة زوجًا من قيم المفاتيح حيث يكون "المفتاح" هو الحدث و "القيمة" بمثابة القيمة المرتبطة به.
لكن وجود مفتاح وقيمة بسيطين لا يكفيان لاسترداد البيانات المتعلقة بالجلسة - فهناك المزيد من البيانات الوصفية لها. لمعالجة هذا الأمر ، قررنا أن أي حدث يحتاج إلى تسجيل سيكون له معرّف جلسة إلى جانب مفتاحه وقيمته. أضفنا أيضًا حقولًا إضافية مثل الطابع الزمني ومعرف المستخدم والمكون الذي يسجل البيانات ، بحيث أصبح من السهل جلب البيانات وتحليلها.

الآن بعد أن قررنا هيكل الحمولة ، كان علينا اختيار مخزن البيانات الخاص بنا. لقد درسنا Elastic Search ، لكننا أردنا أيضًا دعم طلبات التحديث للمفاتيح. سيؤدي هذا إلى إعادة فهرسة المستند بأكمله ، مما قد يؤثر على أداء كتاباتنا. كان موقع MongoDB أكثر منطقية كمخزن بيانات لأنه سيكون من الأسهل الاستعلام عن جميع الأحداث بناءً على أي من حقول البيانات التي سيتم إضافتها. كان هذا سهلا!
القرار 3: حجم قاعدة البيانات ضخم ويصعب الاستعلام والأرشفة!
من أجل قطع الصيانة ، يجب أن تتعامل خدمتنا مع أكبر عدد ممكن من الأحداث. نظرًا لمعدل إصدار BrowserStack للميزات والمنتجات ، كنا على يقين من أن عدد أحداثنا سيزداد بمعدلات أعلى بمرور الوقت ، مما يعني أن خدمتنا يجب أن تستمر في الأداء الجيد. مع زيادة المساحة ، تستغرق عمليات القراءة والكتابة مزيدًا من الوقت - مما قد يكون له تأثير كبير على أداء الخدمة.
كان الحل الأول الذي اكتشفناه هو نقل السجلات من فترة معينة بعيدًا عن قاعدة البيانات (في حالتنا ، قررنا في 15 يومًا). للقيام بذلك ، أنشأنا قاعدة بيانات مختلفة لكل يوم ، مما يسمح لنا بالعثور على سجلات أقدم من فترة معينة دون الحاجة إلى مسح جميع المستندات المكتوبة ضوئيًا. الآن نزيل باستمرار قواعد البيانات التي مضى عليها أكثر من 15 يومًا من Mongo ، مع الاحتفاظ بالنسخ الاحتياطية بالطبع في حالة حدوث ذلك.
الجزء المتبقي الوحيد كان واجهة مطور للاستعلام عن البيانات المتعلقة بالجلسة. بصراحة ، كانت هذه أسهل مشكلة يمكن حلها. نحن نقدم واجهة HTTP ، حيث يمكن للأشخاص الاستعلام عن الأحداث المتعلقة بالجلسة في قاعدة البيانات المقابلة في MongoDB ، عن أي بيانات لها معرف جلسة معين.
بنيان
لنتحدث عن المكونات الداخلية للخدمة ، مع مراعاة النقاط التالية:
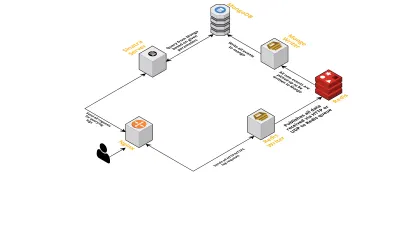
- كما ناقشنا سابقًا ، كنا بحاجة إلى واجهتين - واحدة تستمع عبر UDP والأخرى تستمع عبر HTTP. لذلك قمنا ببناء خادمين ، مرة أخرى لكل واجهة ، للاستماع إلى الأحداث. بمجرد وصول حدث ما ، نقوم بتحليله للتحقق مما إذا كان يحتوي على الحقول المطلوبة - هذه هي معرف الجلسة والمفتاح والقيمة. إذا لم يحدث ذلك ، يتم إسقاط البيانات. خلاف ذلك ، يتم تمرير البيانات عبر قناة Go إلى goroutine آخر ، تكون مسؤوليته الوحيدة هي الكتابة إلى MongoDB.
- مصدر قلق محتمل هنا هو الكتابة إلى MongoDB. إذا كانت عمليات الكتابة إلى MongoDB أبطأ من معدل تلقي البيانات ، فإن هذا يؤدي إلى حدوث اختناق. وهذا بدوره يؤدي إلى تجويع الأحداث الواردة الأخرى ويعني إسقاط البيانات. لذلك ، يجب أن يكون الخادم سريعًا في معالجة السجلات الواردة وأن يكون جاهزًا لمعالجة السجلات القادمة. لمعالجة المشكلة ، قمنا بتقسيم الخادم إلى جزأين: الأول يستقبل جميع الأحداث ويضعها في قائمة الانتظار للجزء الثاني ، والذي يعالجها ويكتبها في MongoDB.
- للاصطفاف اخترنا Redis. من خلال تقسيم المكون بأكمله إلى هاتين القطعتين ، قللنا من عبء عمل الخادم ، مما أتاح له مساحة للتعامل مع المزيد من السجلات.
- كتبنا خدمة صغيرة باستخدام خادم سيناترا للتعامل مع جميع أعمال الاستعلام عن MongoDB بمعلمات معينة. يقوم بإرجاع استجابة HTML / JSON للمطورين عندما يحتاجون إلى معلومات حول جلسة معينة.
كل هذه العمليات تعمل بسعادة على مثيل واحد m3.large .
طلبات مخصصة
نظرًا لأن أداة CLS الخاصة بنا شهدت استخدامًا أكبر بمرور الوقت ، فقد احتاجت إلى المزيد من الميزات. أدناه ، نناقش هذه وكيف تمت إضافتها.
بيانات وصفية مفقودة
بالتدريج مع زيادة عدد المكونات في BrowserStack ، طلبنا المزيد من CLS. على سبيل المثال ، كنا بحاجة إلى القدرة على تسجيل الأحداث من المكونات التي تفتقر إلى معرف الجلسة. وإلا فإن الحصول على واحدة من شأنه أن يثقل كاهل بنيتنا التحتية ، في شكل التأثير على أداء التطبيق وتكبد حركة المرور على خوادمنا الرئيسية.
لقد عالجنا ذلك من خلال تمكين تسجيل الأحداث باستخدام مفاتيح أخرى ، مثل معرفات الجهاز والمستخدم. الآن كلما تم إنشاء جلسة أو تحديثها ، يتم إعلام CLS بمعرف الجلسة ، بالإضافة إلى معرفات المستخدم والمطراف ذات الصلة. يقوم بتخزين الخريطة التي يمكن استرجاعها من خلال عملية الكتابة إلى MongoDB. كلما تم استرداد حدث يحتوي على المستخدم أو معرف الجهاز ، تتم إضافة معرف الجلسة.
التعامل مع البريد العشوائي (مشكلات التعليمات البرمجية في المكونات الأخرى)
واجه CLS أيضًا الصعوبات المعتادة في التعامل مع أحداث البريد العشوائي. غالبًا ما وجدنا عمليات نشر في المكونات التي أدت إلى إنشاء حجم ضخم من الطلبات المرسلة إلى CLS. ستعاني السجلات الأخرى في هذه العملية ، حيث أصبح الخادم مشغولًا جدًا لمعالجة هذه السجلات وتم إسقاط السجلات المهمة.
بالنسبة للجزء الأكبر ، كانت معظم البيانات التي يتم تسجيلها عبر طلبات HTTP. للتحكم بها ، نقوم بتمكين تحديد المعدل على nginx (باستخدام وحدة Limit_req_zone) ، والتي تحظر الطلبات من أي IP وجدنا أنها تصل إلى طلبات أكثر من رقم معين في فترة زمنية قصيرة. بالطبع ، نقوم بالاستفادة من التقارير الصحية على جميع عناوين IP المحظورة وإبلاغ الفرق المسؤولة.
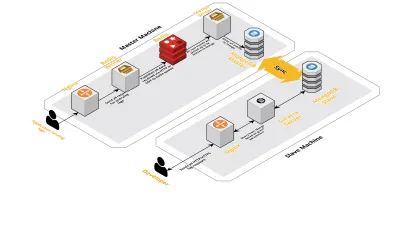
مقياس v2.0
مع زيادة جلساتنا اليومية ، زادت أيضًا البيانات التي يتم تسجيلها في CLS. أثر هذا على الاستفسارات التي كان مطوروها يشغلونها يوميًا ، وسرعان ما كان الاختناق الذي واجهناه مع الجهاز نفسه. يتكون إعدادنا من جهازين أساسيين يعملان على تشغيل جميع المكونات المذكورة أعلاه ، جنبًا إلى جنب مع مجموعة من البرامج النصية للاستعلام عن Mongo وتتبع المقاييس الرئيسية لكل منتج. بمرور الوقت ، زادت البيانات الموجودة على الجهاز بشكل كبير وبدأت البرامج النصية تستغرق الكثير من وقت وحدة المعالجة المركزية. حتى بعد محاولة تحسين استعلامات Mongo ، كنا نعود دائمًا إلى نفس المشكلات.
لحل هذه المشكلة ، أضفنا جهازًا آخر لتشغيل البرامج النصية للتقارير الصحية والواجهة للاستعلام عن هذه الجلسات. تضمنت العملية إقلاع آلة جديدة وإعداد عبد لـ Mongo يعمل على الجهاز الرئيسي. وقد ساعد هذا في تقليل ارتفاعات وحدة المعالجة المركزية التي رأيناها كل يوم بسبب هذه البرامج النصية.
خاتمة
يمكن أن يصبح إنشاء خدمة لمهمة بسيطة مثل تسجيل البيانات معقدًا ، مع زيادة كمية البيانات. تتناول هذه المقالة الحلول التي اكتشفناها ، جنبًا إلى جنب مع التحديات التي واجهناها أثناء حل هذه المشكلة. لقد جربنا مع Golang لمعرفة مدى ملاءمته لنظامنا البيئي ، وحتى الآن نحن راضون. لقد كان اختيارنا لإنشاء خدمة داخلية بدلاً من الدفع مقابل خدمة خارجية فعالاً للغاية من حيث التكلفة. لم يكن علينا أيضًا توسيع نطاق إعدادنا إلى جهاز آخر حتى وقت لاحق - عندما زاد حجم جلساتنا. بالطبع ، استندت اختياراتنا في تطوير CLS بالكامل إلى متطلباتنا وأولوياتنا.
تعالج CLS اليوم ما يصل إلى 15 مليون حدث كل يوم ، وتشكل ما يصل إلى 70 غيغابايت من البيانات. يتم استخدام هذه البيانات لمساعدتنا في حل أي مشاكل يواجهها عملاؤنا خلال أي جلسة. نحن نستخدم هذه البيانات أيضًا لأغراض أخرى. نظرًا للرؤى التي توفرها بيانات كل جلسة حول المنتجات المختلفة والمكونات الداخلية ، فقد بدأنا في الاستفادة من هذه البيانات لتتبع كل منتج. يتم تحقيق ذلك عن طريق استخراج المقاييس الرئيسية لجميع المكونات المهمة.
بشكل عام ، لقد شهدنا نجاحًا كبيرًا في بناء أداة CLS الخاصة بنا. إذا كان من المنطقي بالنسبة لك ، أنصحك بالتفكير في فعل الشيء نفسه!