
كيفية بناء مكشطة منتج أمازون باستخدام Node.js
نشرت: 2022-03-10هل سبق لك أن كنت في وضع تحتاج فيه إلى معرفة سوق منتج معين عن كثب؟ ربما تقوم بتشغيل بعض البرامج وتحتاج إلى معرفة كيفية تسعيرها. أو ربما لديك بالفعل منتجك الخاص في السوق وتريد معرفة الميزات التي يجب إضافتها للحصول على ميزة تنافسية. أو ربما ترغب فقط في شراء شيء ما لنفسك وتريد التأكد من حصولك على أفضل قيمة مقابل ما تدفعه.
تشترك كل هذه المواقف في شيء واحد: تحتاج إلى بيانات دقيقة لاتخاذ القرار الصحيح . في الواقع ، هناك شيء آخر يشاركونه. يمكن أن تستفيد جميع السيناريوهات من استخدام مكشطة الويب.
تجريف الويب هو ممارسة استخراج كميات كبيرة من بيانات الويب من خلال استخدام البرامج. لذلك ، في جوهرها ، إنها طريقة لأتمتة العملية الشاقة المتمثلة في الضغط على "نسخ" ثم "لصق" 200 مرة. بالطبع ، يمكن للروبوت أن يفعل ذلك في الوقت الذي استغرقته لقراءة هذه الجملة ، لذا فهي ليست أقل مللاً فحسب ، بل أسرع كثيرًا أيضًا.
لكن السؤال الملح هو: لماذا قد يرغب شخص ما في كشط صفحات أمازون؟
أنت على وشك معرفة ذلك! لكن أولاً وقبل كل شيء ، أود أن أوضح شيئًا الآن - في حين أن فعل تجريف البيانات المتاحة للجمهور أمر قانوني ، فإن أمازون لديها بعض التدابير لمنع ذلك على صفحاتهم. على هذا النحو ، أحثك دائمًا على الانتباه إلى موقع الويب أثناء تجريفه ، والحرص على عدم إتلافه ، واتباع الإرشادات الأخلاقية.
يوصى بقراءة : "دليل التجريف الأخلاقي للمواقع الديناميكية باستخدام Node.js ومحرك الدمى" بواسطة Andreas Altheimer
لماذا يجب عليك استخراج بيانات منتج أمازون
لكونك أكبر بائع تجزئة عبر الإنترنت على هذا الكوكب ، فمن الآمن أن نقول إنه إذا كنت ترغب في شراء شيء ما ، فمن المحتمل أن تحصل عليه من أمازون. لذلك ، من نافلة القول مدى ضخامة كنز البيانات الموجود على موقع الويب.
عند تجريف الويب ، يجب أن يكون سؤالك الأساسي هو ما يجب فعله بكل تلك البيانات. في حين أن هناك العديد من الأسباب الفردية ، فإنها تتلخص في حالتين بارزتين: تحسين منتجاتك وإيجاد أفضل الصفقات.
"
لنبدأ بالسيناريو الأول. ما لم تكن قد صممت منتجًا جديدًا مبتكرًا حقًا ، فمن المحتمل أنه يمكنك بالفعل العثور على شيء مشابه على الأقل على Amazon. يمكن أن يوفر لك كشط صفحات المنتج هذه بيانات لا تقدر بثمن مثل:
- استراتيجية تسعير المنافسين
لذلك ، يمكنك تعديل أسعارك لتكون تنافسية وفهم كيفية تعامل الآخرين مع الصفقات الترويجية ؛ - آراء العملاء
لمعرفة أكثر ما تهتم به قاعدة عملائك في المستقبل وكيفية تحسين تجربتهم ؛ - الميزات الأكثر شيوعًا
لمعرفة ما تقدمه منافسيك لمعرفة الوظائف الحاسمة وأيها يمكن تركها لوقت لاحق.
في الأساس ، تمتلك أمازون كل ما تحتاجه لإجراء تحليل عميق للسوق والمنتجات. ستكون مستعدًا بشكل أفضل لتصميم ، وإطلاق ، وتوسيع مجموعة منتجاتك بهذه البيانات.
يمكن أن ينطبق السيناريو الثاني على كل من الشركات والأفراد العاديين. الفكرة تشبه إلى حد كبير ما ذكرته سابقًا. يمكنك كشط الأسعار والميزات والمراجعات لجميع المنتجات التي يمكنك اختيارها ، وبالتالي ، ستتمكن من اختيار المنتج الذي يوفر أكبر قدر من الفوائد بأقل سعر. بعد كل شيء ، من الذي لا يحب صفقة جيدة؟
لا تستحق كل المنتجات هذا المستوى من الاهتمام بالتفاصيل ، ولكن يمكن أن تحدث فرقًا كبيرًا مع عمليات الشراء باهظة الثمن. لسوء الحظ ، على الرغم من أن الفوائد واضحة ، إلا أن العديد من الصعوبات تتماشى مع تجريف Amazon.
تحديات تجريف بيانات منتج أمازون
ليست كل المواقع هي نفسها. كقاعدة عامة ، كلما كان موقع الويب أكثر تعقيدًا وانتشارًا ، كان من الصعب التخلص منه. أتذكر عندما قلت أن أمازون كان أبرز موقع للتجارة الإلكترونية؟ حسنًا ، هذا يجعلها شائعة للغاية ومعقدة بشكل معقول.
أولاً ، تعرف أمازون كيف تعمل روبوتات القشط ، لذا فإن موقع الويب لديه إجراءات مضادة. وبالتحديد ، إذا كانت الكاشطة تتبع نمطًا يمكن التنبؤ به ، وترسل الطلبات على فترات زمنية محددة ، أو أسرع مما يمكن للإنسان أو باستخدام معلمات متطابقة تقريبًا ، فسوف تلاحظ أمازون عنوان IP وتحظره. يمكن للوكلاء حل هذه المشكلة ، لكنني لم أكن بحاجة إليهم لأننا لن نقوم بحذف الكثير من الصفحات في المثال.
بعد ذلك ، تستخدم أمازون عن عمد هياكل صفحات مختلفة لمنتجاتها. وهذا يعني أنه إذا قمت بفحص الصفحات بحثًا عن منتجات مختلفة ، فهناك فرصة جيدة لأن تجد اختلافات كبيرة في هيكلها وسماتها. السبب وراء ذلك بسيط للغاية. تحتاج إلى تكييف كود الكاشطة الخاص بك لنظام معين ، وإذا كنت تستخدم نفس البرنامج النصي على نوع جديد من الصفحات ، فسيتعين عليك إعادة كتابة أجزاء منه. لذلك ، فهي تجعلك تعمل بشكل أكبر من أجل البيانات.
أخيرًا ، يعد موقع أمازون موقعًا واسعًا. إذا كنت ترغب في جمع كميات كبيرة من البيانات ، فإن تشغيل برنامج الكشط على جهاز الكمبيوتر الخاص بك قد يستغرق وقتًا طويلاً للغاية لتلبية احتياجاتك. يتم تعزيز هذه المشكلة بشكل أكبر من خلال حقيقة أن السير بسرعة كبيرة سيؤدي إلى حظر المكشطة. لذا ، إذا كنت تريد كميات كبيرة من البيانات بسرعة ، فستحتاج إلى مكشطة قوية حقًا.
حسنًا ، يكفي الحديث عن المشكلات ، دعنا نركز على الحلول!
كيفية بناء مكشطة ويب للأمازون
لتبسيط الأمور ، سنتخذ نهجًا تدريجيًا لكتابة التعليمات البرمجية. لا تتردد في العمل بالتوازي مع الدليل.
ابحث عن البيانات التي نحتاجها
إذن ، هذا سيناريو: سأنتقل في غضون بضعة أشهر إلى مكان جديد ، وسأحتاج إلى رفين جديدين لحمل الكتب والمجلات. أريد أن أعرف كل خياراتي وأن أحصل على صفقة جيدة بقدر ما أستطيع. لذلك ، دعنا نذهب إلى سوق أمازون ، ونبحث عن "الرفوف" ، ونرى ما الذي نحصل عليه.
عنوان URL لهذا البحث والصفحة التي سنقوم بكشطها موجودان هنا.
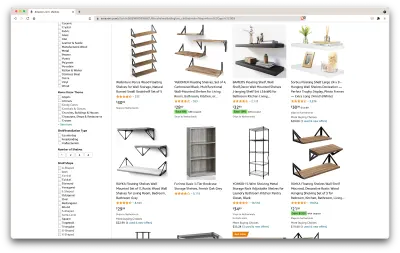
حسنًا ، دعنا نقيّم ما لدينا هنا. بمجرد إلقاء نظرة خاطفة على الصفحة ، يمكننا الحصول على صورة جيدة عن:
- كيف تبدو الرفوف
- ما تتضمنه الحزمة ؛
- كيف يقوم العملاء بتقييمهم ؛
- سعرهم
- الارتباط بالمنتج ؛
- اقتراح لبديل أرخص لبعض العناصر.
هذا أكثر مما يمكن أن نطلبه!
احصل على الأدوات المطلوبة
دعنا نتأكد من تثبيت جميع الأدوات التالية وتكوينها قبل المتابعة إلى الخطوة التالية.
- كروم
يمكننا تنزيله من هنا. - VSCode
اتبع التعليمات الواردة في هذه الصفحة لتثبيته على جهازك المحدد. - Node.js
قبل البدء في استخدام Axios أو Cheerio ، نحتاج إلى تثبيت Node.js و Node Package Manager. أسهل طريقة لتثبيت Node.js و NPM هي الحصول على أحد المثبتات من المصدر الرسمي Node.Js وتشغيله.
الآن ، لنقم بإنشاء مشروع NPM جديد. قم بإنشاء مجلد جديد للمشروع وقم بتشغيل الأمر التالي:
npm init -yلإنشاء مكشطة الويب ، نحتاج إلى تثبيت اثنين من التبعيات في مشروعنا:
- تشيريو
مكتبة مفتوحة المصدر تساعدنا في استخراج المعلومات المفيدة عن طريق تحليل العلامات وتوفير واجهة برمجة تطبيقات لمعالجة البيانات الناتجة. يسمح لنا Cheerio بتحديد العلامات الخاصة بمستند HTML باستخدام المحددات:$("div"). يساعدنا هذا المحدد المحدد في اختيار جميع عناصر<div>على الصفحة. لتثبيت Cheerio ، يرجى تشغيل الأمر التالي في مجلد المشاريع:
npm install cheerio- أكسيوس
مكتبة JavaScript تُستخدم لإجراء طلبات HTTP من Node.js.
npm install axiosافحص مصدر الصفحة
في الخطوات التالية ، سنتعلم المزيد حول كيفية تنظيم المعلومات على الصفحة. الفكرة هي الحصول على فهم أفضل لما يمكن أن نتخلص منه من مصدرنا.
تساعدنا أدوات المطور في استكشاف نموذج كائن المستند (DOM) لموقع الويب بشكل تفاعلي. سنستخدم أدوات المطور في Chrome ، ولكن يمكنك استخدام أي متصفح ويب يناسبك.
لنفتحه بالنقر بزر الماوس الأيمن في أي مكان على الصفحة وتحديد خيار "فحص":
سيؤدي هذا إلى فتح نافذة جديدة تحتوي على شفرة المصدر للصفحة. كما قلنا من قبل ، نتطلع إلى كشف معلومات كل رف.
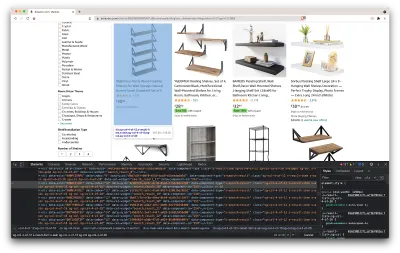
كما نرى من لقطة الشاشة أعلاه ، تحتوي الحاويات التي تحتوي على جميع البيانات على الفئات التالية:
sg-col-4-of-12 s-result-item s-asin sg-col-4-of-16 sg-col sg-col-4-of-20في الخطوة التالية ، سنستخدم Cheerio لتحديد جميع العناصر التي تحتوي على البيانات التي نحتاجها.

إحضار البيانات
بعد أن قمنا بتثبيت جميع التبعيات المذكورة أعلاه ، فلنقم بإنشاء ملف index.js جديد واكتب سطور التعليمات البرمجية التالية:
const axios = require("axios"); const cheerio = require("cheerio"); const fetchShelves = async () => { try { const response = await axios.get('https://www.amazon.com/s?crid=36QNR0DBY6M7J&k=shelves&ref=glow_cls&refresh=1&sprefix=s%2Caps%2C309'); const html = response.data; const $ = cheerio.load(html); const shelves = []; $('div.sg-col-4-of-12.s-result-item.s-asin.sg-col-4-of-16.sg-col.sg-col-4-of-20').each((_idx, el) => { const shelf = $(el) const title = shelf.find('span.a-size-base-plus.a-color-base.a-text-normal').text() shelves.push(title) }); return shelves; } catch (error) { throw error; } }; fetchShelves().then((shelves) => console.log(shelves)); كما نرى ، نقوم باستيراد التبعيات التي نحتاجها في أول سطرين ، ثم نقوم بإنشاء وظيفة fetchShelves() التي ، باستخدام Cheerio ، تحصل على جميع العناصر التي تحتوي على معلومات منتجاتنا من الصفحة.
يتكرر فوق كل منهم ويدفعه إلى مصفوفة فارغة للحصول على نتيجة منسقة بشكل أفضل.
ستعيد الدالة fetchShelves() عنوان المنتج فقط في الوقت الحالي ، لذلك دعونا نحصل على بقية المعلومات التي نحتاجها. يرجى إضافة سطور التعليمات البرمجية التالية بعد السطر الذي حددنا فيه title المتغير.
const image = shelf.find('img.s-image').attr('src') const link = shelf.find('aa-link-normal.a-text-normal').attr('href') const reviews = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div.a-row.a-size-small').children('span').last().attr('aria-label') const stars = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div > span').attr('aria-label') const price = shelf.find('span.a-price > span.a-offscreen').text() let element = { title, image, link: `https://amazon.com${link}`, price, } if (reviews) { element.reviews = reviews } if (stars) { element.stars = stars } واستبدل الأرفف ، shelves.push(title) shelves.push(element) .
نحن الآن نختار جميع المعلومات التي نحتاجها ونضيفها إلى كائن جديد يسمى element . ثم يتم دفع كل عنصر إلى مصفوفة shelves للحصول على قائمة بالكائنات تحتوي فقط على البيانات التي نبحث عنها.
هكذا يجب أن يبدو كائن shelf قبل إضافته إلى قائمتنا:
{ title: 'SUPERJARE Wall Mounted Shelves, Set of 2, Display Ledge, Storage Rack for Room/Kitchen/Office - White', image: 'https://m.media-amazon.com/images/I/61fTtaQNPnL._AC_UL320_.jpg', link: 'https://amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_btf_aps_sr_pg1_1?ie=UTF8&adId=A03078372WABZ8V6NFP9L&url=%2FSUPERJARE-Mounted-Floating-Shelves-Display%2Fdp%2FB07H4NRT36%2Fref%3Dsr_1_59_sspa%3Fcrid%3D36QNR0DBY6M7J%26dchild%3D1%26keywords%3Dshelves%26qid%3D1627970918%26refresh%3D1%26sprefix%3Ds%252Caps%252C309%26sr%3D8-59-spons%26psc%3D1&qualifier=1627970918&id=3373422987100422&widgetName=sp_btf', price: '$32.99', reviews: '6,171', stars: '4.7 out of 5 stars' }تنسيق البيانات
الآن وقد تمكنا من جلب البيانات التي نحتاجها ، فمن الجيد حفظها كملف .CSV لتحسين إمكانية القراءة. بعد الحصول على جميع البيانات ، سنستخدم الوحدة fs التي توفرها Node.js ونحفظ ملفًا جديدًا يسمى save saved-shelves.csv إلى مجلد المشروع. قم باستيراد الوحدة النمطية fs في الجزء العلوي من الملف وانسخها أو اكتبها على طول سطور التعليمات البرمجية التالية:
let csvContent = shelves.map(element => { return Object.values(element).map(item => `"${item}"`).join(',') }).join("\n") fs.writeFile('saved-shelves.csv', "Title, Image, Link, Price, Reviews, Stars" + '\n' + csvContent, 'utf8', function (err) { if (err) { console.log('Some error occurred - file either not saved or corrupted.') } else{ console.log('File has been saved!') } }) كما نرى ، في الأسطر الثلاثة الأولى ، نقوم بتنسيق البيانات التي جمعناها سابقًا من خلال ضم جميع قيم كائن الرف باستخدام فاصلة. بعد ذلك ، باستخدام الوحدة النمطية fs ، نقوم بإنشاء ملف يسمى saved-shelves.csv ، وإضافة صف جديد يحتوي على رؤوس الأعمدة ، وإضافة البيانات التي قمنا بتنسيقها للتو وإنشاء وظيفة رد الاتصال التي تعالج الأخطاء.
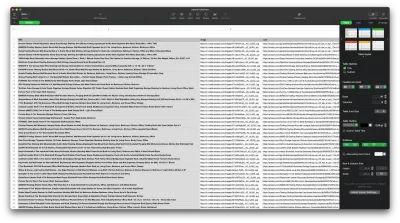
يجب أن تبدو النتيجة كما يلي:
نصائح إضافية!
كشط تطبيقات صفحة واحدة
أصبح المحتوى الديناميكي هو المعيار في الوقت الحاضر ، حيث أصبحت مواقع الويب أكثر تعقيدًا من أي وقت مضى. لتوفير أفضل تجربة مستخدم ممكنة ، يجب على المطورين اعتماد آليات تحميل مختلفة للمحتوى الديناميكي ، مما يجعل عملنا أكثر تعقيدًا. إذا كنت لا تعرف ما يعنيه ذلك ، فتخيل متصفحًا يفتقر إلى واجهة مستخدم رسومية. لحسن الحظ ، هناك Puppeteer - مكتبة العقدة السحرية التي توفر واجهة برمجة تطبيقات عالية المستوى للتحكم في مثيل Chrome عبر بروتوكول DevTools. ومع ذلك ، فإنه يوفر نفس وظائف المتصفح ، ولكن يجب التحكم فيه برمجيًا عن طريق كتابة سطرين من التعليمات البرمجية. دعونا نرى كيف يعمل ذلك.
في المشروع الذي تم إنشاؤه مسبقًا ، قم بتثبيت مكتبة Puppeteer عن طريق تشغيل npm install puppeteer ، وإنشاء ملف puppeteer.js جديد ، والنسخ أو الكتابة على طول سطور التعليمات البرمجية التالية:
const puppeteer = require('puppeteer') (async () => { try { const chrome = await puppeteer.launch() const page = await chrome.newPage() await page.goto('https://www.reddit.com/r/Kanye/hot/') await page.waitForSelector('.rpBJOHq2PR60pnwJlUyP0', { timeout: 2000 }) const body = await page.evaluate(() => { return document.querySelector('body').innerHTML }) console.log(body) await chrome.close() } catch (error) { console.log(error) } })() في المثال أعلاه ، نقوم بإنشاء مثيل Chrome ونفتح صفحة متصفح جديدة مطلوبة للانتقال إلى هذا الرابط. في السطر التالي ، نطلب من المتصفح بدون رأس الانتظار حتى يظهر العنصر الذي يحتوي على الفئة rpBJOHq2PR60pnwJlUyP0 على الصفحة. لقد حددنا أيضًا المدة التي يجب أن ينتظرها المتصفح حتى يتم تحميل الصفحة (2000 مللي ثانية).
باستخدام طريقة evaluate على متغير page ، أصدرنا تعليمات لمحرر العرائس بتنفيذ مقتطفات جافا سكريبت داخل سياق الصفحة بعد تحميل العنصر أخيرًا. سيسمح لنا ذلك بالوصول إلى محتوى HTML للصفحة وإرجاع نص الصفحة كناتج. نقوم بعد ذلك بإغلاق مثيل Chrome عن طريق استدعاء طريقة close على متغير chrome . يجب أن يتكون العمل الناتج من جميع تعليمات HTML البرمجية التي تم إنشاؤها ديناميكيًا. هذه هي الطريقة التي يمكن أن يساعدنا بها محرك الدمى في تحميل محتوى HTML ديناميكي .
إذا كنت لا تشعر بالراحة عند استخدام برنامج Puppeteer ، فلاحظ أن هناك عدة بدائل ، مثل NightwatchJS أو NightmareJS أو CasperJS. إنها مختلفة بعض الشيء ، لكن في النهاية ، العملية متشابهة إلى حد كبير.
تعيين رؤوس user-agent
user-agent هو عنوان طلب يخبر موقع الويب الذي تزوره عن نفسك ، أي متصفحك ونظام التشغيل. يستخدم هذا لتحسين المحتوى لإعدادك ، لكن مواقع الويب تستخدمه أيضًا لتحديد الروبوتات التي ترسل الكثير من الطلبات - حتى لو تغيرت IPS.
إليك ما يبدو عليه عنوان user-agent :
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36من أجل عدم اكتشافك وحظرك ، يجب عليك تغيير هذا العنوان بانتظام. احرص على عدم إرسال ترويسة فارغة أو قديمة لأن هذا لا يجب أن يحدث أبدًا لمستخدم التشغيل ، وستتميز.
تحديد معدل
يمكن أن تجمع برامج كاشطات الويب المحتوى بسرعة كبيرة ، ولكن يجب تجنب السير بأقصى سرعة. هناك سببان لهذا:
- يمكن أن يؤدي وجود عدد كبير جدًا من الطلبات في وقت قصير إلى إبطاء خادم موقع الويب أو حتى تعطيله ، مما يتسبب في حدوث مشكلات للمالك والزائرين الآخرين. يمكن أن يتحول بشكل أساسي إلى هجوم DoS.
- بدون البروكسيات المتناوبة ، يكون الأمر أشبه بالإعلان بصوت عالٍ أنك تستخدم روبوتًا لأنه لن يرسل أي إنسان مئات أو آلاف الطلبات في الثانية.
الحل هو إدخال تأخير بين طلباتك ، وهي ممارسة تسمى "تحديد المعدل". ( إنه سهل التنفيذ أيضًا! )
في مثال محرك الدمى الموضح أعلاه ، قبل إنشاء متغير body ، يمكننا استخدام طريقة waitForTimeout التي يوفرها برنامج Puppeteer للانتظار بضع ثوانٍ قبل تقديم طلب آخر:
await page.waitForTimeout(3000); حيث ms هو عدد الثواني التي تريد انتظارها.
أيضًا ، إذا أردنا القيام بنفس الشيء لمثال axios ، فيمكننا إنشاء وعد يستدعي طريقة setTimeout() ، من أجل مساعدتنا في انتظار العدد المطلوب من المللي ثانية:
fetchShelves.then(result => new Promise(resolve => setTimeout(() => resolve(result), 3000)))وبهذه الطريقة ، يمكنك تجنب ممارسة الكثير من الضغط على الخادم المستهدف وأيضًا اتباع نهج أكثر إنسانية في تجريف الويب.
خواطر ختامية
ويوجد لديك ، دليل خطوة بخطوة لإنشاء مكشطة الويب الخاصة بك لبيانات منتج أمازون! لكن تذكر ، كان هذا مجرد موقف واحد. إذا كنت ترغب في كشط موقع ويب مختلف ، فسيتعين عليك إجراء بعض التعديلات للحصول على أي نتائج ذات مغزى.
القراءة ذات الصلة
إذا كنت لا تزال ترغب في رؤية المزيد من عمليات تجريف الويب قيد التنفيذ ، فإليك بعض مواد القراءة المفيدة لك:
- "The Ultimate Guide to Web Scraping with JavaScript and Node.Js،" Robert Sfichi
- "Advanced Node.JS Web Scraping with Puppeteer،" غابرييل سيوسي
- "Python Web Scraping: الدليل النهائي لبناء الكاشطة ،" Raluca Penciuc