
قم بإنشاء تطبيق ارتباط باستخدام FaunaDB و Netlify و 11ty
نشرت: 2022-03-10ثورة JAMstack (JavaScript و APIs و Markup) تسير على قدم وساق. المواقع الثابتة آمنة وسريعة وموثوقة وممتعة للعمل عليها. في قلب JAMstack توجد مولدات المواقع الثابتة (SSGs) التي تخزن بياناتك كملفات ثابتة: Markdown ، و YAML ، و JSON ، و HTML ، وما إلى ذلك. في بعض الأحيان ، قد تكون إدارة البيانات بهذه الطريقة معقدة للغاية. في بعض الأحيان ، ما زلنا بحاجة إلى قاعدة بيانات.
مع وضع ذلك في الاعتبار ، تعاونت Netlify - مضيف موقع ثابت و FaunaDB - قاعدة بيانات سحابية بدون خادم - لجعل الجمع بين كلا النظامين أسهل.
لماذا موقع ارتباطك؟
يعتبر JAMstack رائعًا للعديد من الاستخدامات الاحترافية ، ولكن أحد الجوانب المفضلة لدي في هذه المجموعة من التكنولوجيا هو حاجزها المنخفض لدخول الأدوات والمشاريع الشخصية.
هناك الكثير من المنتجات الجيدة في السوق لمعظم التطبيقات التي يمكنني طرحها ، ولكن لن يتم إعداد أي منها لي بالضبط. لن يمنحني أي شيء التحكم الكامل في المحتوى الخاص بي. لن يأتي أي منها بدون تكلفة (نقدية أو معلوماتية).
مع وضع ذلك في الاعتبار ، يمكننا إنشاء خدماتنا المصغرة باستخدام طرق JAMstack. في هذه الحالة ، سننشئ موقعًا لتخزين ونشر أي مقالات مثيرة صادفتها في قراءتي اليومية للتكنولوجيا.
أقضي الكثير من الوقت في قراءة المقالات التي تمت مشاركتها على Twitter. عندما أحب واحدة ، أصبت على أيقونة "القلب". ثم ، في غضون أيام قليلة ، يكاد يكون من المستحيل العثور عليه مع تدفق مفضلات جديدة. أريد أن أبني شيئًا قريبًا من راحة "القلب" ، لكنني أملك وأتحكم.
كيف سنقوم بفعل ذلك؟ أنا سعيد لأنك سألت.
هل أنت مهتم بالحصول على الكود؟ يمكنك الحصول عليه على Github أو نشره مباشرة إلى Netlify من هذا المستودع! الق نظرة على المنتج النهائي هنا.
تقنياتنا
وظائف الاستضافة وبدون خادم: Netlify
للاستضافة والوظائف التي لا تحتاج إلى خادم ، سنستخدم Netlify. كمكافأة إضافية ، من خلال التعاون الجديد المذكور أعلاه ، سيتصل CLI الخاص بـ Netlify - "Netlify Dev" - تلقائيًا بـ FaunaDB ويخزن مفاتيح API الخاصة بنا كمتغيرات البيئة.
قاعدة البيانات: FaunaDB
FaunaDB هي قاعدة بيانات NoSQL "بدون خادم". سنستخدمه لتخزين بيانات الإشارات المرجعية الخاصة بنا.
مولد الموقع الثابت: 11ty
أنا من أشد المؤمنين بـ HTML. لهذا السبب ، لن يستخدم البرنامج التعليمي JavaScript للواجهة الأمامية لعرض إشاراتنا المرجعية. بدلاً من ذلك ، سنستخدم 11ty كمولد موقع ثابت. يحتوي 11ty على وظيفة بيانات مضمنة تجعل جلب البيانات من واجهة برمجة التطبيقات أمرًا سهلاً مثل كتابة بضع وظائف JavaScript قصيرة.
اختصارات iOS
سنحتاج إلى طريقة سهلة لنشر البيانات في قاعدة البيانات الخاصة بنا. في هذه الحالة ، سنستخدم تطبيق Shortcuts الخاص بنظام iOS. يمكن تحويل هذا إلى Android أو سطح المكتب JavaScript bookmarklet أيضًا.
إعداد FaunaDB عبر Netlify Dev
سواء كنت قد اشتركت بالفعل في FaunaDB أو كنت بحاجة إلى إنشاء حساب جديد ، فإن أسهل طريقة لإعداد رابط بين FaunaDB و Netlify هي عبر CLI الخاص بـ Netlify: Netlify Dev. يمكنك العثور على التعليمات الكاملة من FaunaDB هنا أو اتباعها أدناه.
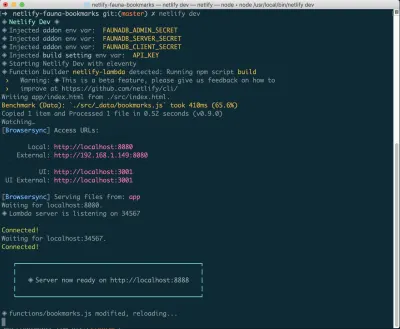
إذا لم يكن هذا مثبتًا لديك بالفعل ، فيمكنك تشغيل الأمر التالي في Terminal:
npm install netlify-cli -gمن داخل دليل المشروع الخاص بك ، قم بتشغيل الأوامر التالية:
netlify init // This will connect your project to a Netlify project netlify addons:create fauna // This will install the FaunaDB "addon" netlify addons:auth fauna // This command will run you through connecting your account or setting up an account بمجرد توصيل كل هذا ، يمكنك تشغيل netlify dev في مشروعك. سيؤدي هذا إلى تشغيل أي نصوص برمجية أنشأناها ، ولكن أيضًا الاتصال بخدمات Netlify و FaunaDB والاستيلاء على أي متغيرات بيئة ضرورية. مفيد!
إنشاء بياناتنا الأولى
من هنا ، سنقوم بتسجيل الدخول إلى FaunaDB وإنشاء مجموعة بياناتنا الأولى. سنبدأ بإنشاء قاعدة بيانات جديدة تسمى "الإشارات المرجعية". داخل قاعدة البيانات ، لدينا مجموعات ووثائق وفهارس.
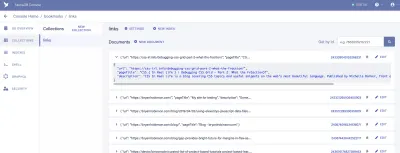
المجموعة هي مجموعة مصنفة من البيانات. تأخذ كل قطعة من البيانات شكل مستند. الوثيقة هي "سجل واحد قابل للتغيير داخل قاعدة بيانات FaunaDB" ، وفقًا لوثائق Fauna. يمكنك التفكير في المجموعات كجدول قاعدة بيانات تقليدي والمستند كصف.
بالنسبة لتطبيقنا ، نحتاج إلى مجموعة واحدة ، والتي سنسميها "الروابط". سيكون كل مستند ضمن مجموعة "الروابط" كائن JSON بسيطًا بثلاث خصائص. للبدء ، سنضيف مستندًا جديدًا سنستخدمه لبناء أول عملية جلب للبيانات.
{ "url": "https://css-irl.info/debugging-css-grid-part-2-what-the-fraction/", "pageTitle": "CSS { In Real Life } | Debugging CSS Grid – Part 2: What the Fr(action)?", "description": "CSS In Real Life is a blog covering CSS topics and useful snippets on the web's most beautiful language. Published by Michelle Barker, front end developer at Ordoo and CSS superfan." }يؤدي هذا إلى إنشاء الأساس للمعلومات التي سنحتاج إلى سحبها من إشاراتنا المرجعية بالإضافة إلى تزويدنا بمجموعتنا الأولى من البيانات لسحبها إلى نموذجنا.
إذا كنت مثلي ، فأنت تريد أن ترى ثمار عملك على الفور. دعنا نحصل على شيء على الصفحة!
تثبيت 11ty وسحب البيانات إلى قالب
نظرًا لأننا نريد عرض الإشارات المرجعية بتنسيق HTML وليس إحضارها بواسطة المتصفح ، فسنحتاج إلى شيء للقيام بالعرض. هناك العديد من الطرق الرائعة للقيام بذلك ، ولكن من أجل السهولة والقوة ، أحب استخدام مولد الموقع الثابت 11ty.
نظرًا لأن 11ty هو منشئ مواقع جافا سكريبت ثابت ، يمكننا تثبيته عبر NPM.
npm install --save @11ty/eleventy من هذا التثبيت ، يمكننا تشغيل eleventy أو eleventy --serve في مشروعنا للتشغيل.
غالبًا ما يكتشف Netlify Dev 11ty كمتطلب ويقوم بتشغيل الأمر لنا. لإنجاز هذا العمل - والتأكد من استعدادنا للنشر ، يمكننا أيضًا إنشاء أمرين "serve" و "build" في package.json لدينا.
"scripts": { "build": "npx eleventy", "serve": "npx eleventy --serve" }ملفات بيانات 11ty's
معظم مولدات المواقع الثابتة لديها فكرة عن "ملف بيانات" مدمج. عادةً ما تكون هذه الملفات عبارة عن ملفات JSON أو YAML تتيح لك إضافة معلومات إضافية إلى موقعك.
في عام 11 ، يمكنك استخدام ملفات بيانات JSON أو ملفات بيانات JavaScript. من خلال استخدام ملف JavaScript ، يمكننا بالفعل إجراء مكالمات API الخاصة بنا وإعادة البيانات مباشرة إلى قالب.
بشكل افتراضي ، يريد 11ty تخزين ملفات البيانات في دليل _data . يمكنك بعد ذلك الوصول إلى البيانات باستخدام اسم الملف كمتغير في القوالب الخاصة بك. في حالتنا ، سننشئ ملفًا في _data/bookmarks.js إليه عبر اسم المتغير {{ bookmarks }} .
إذا كنت ترغب في التعمق في تكوين ملف البيانات ، فيمكنك قراءة الأمثلة في الوثائق 11ty أو الاطلاع على هذا البرنامج التعليمي حول استخدام ملفات بيانات 11ty مع Meetup API.
سيكون الملف وحدة جافا سكريبت. لذلك من أجل الحصول على أي شيء ، نحتاج إلى تصدير بياناتنا أو وظيفة. في حالتنا ، سنقوم بتصدير دالة.
module.exports = async function() { const data = mapBookmarks(await getBookmarks()); return data.reverse() } دعونا نكسر ذلك. لدينا وظيفتان تقومان بعملنا الرئيسي هنا: mapBookmarks() و getBookmarks() .
ستذهب وظيفة getBookmarks() لجلب بياناتنا من قاعدة بيانات FaunaDB الخاصة بنا وستأخذ mapBookmarks() مجموعة من الإشارات المرجعية وتعيد هيكلتها لتعمل بشكل أفضل مع نموذجنا.
دعنا نتعمق أكثر في getBookmarks() .
getBookmarks()
أولاً ، سنحتاج إلى تثبيت وتهيئة مثيل لبرنامج FaunaDB JavaScript.
npm install --save faunadbالآن بعد أن قمنا بتثبيته ، دعنا نضيفه إلى أعلى ملف البيانات الخاص بنا. هذا الرمز مباشرة من مستندات Fauna.
// Requires the Fauna module and sets up the query module, which we can use to create custom queries. const faunadb = require('faunadb'), q = faunadb.query; // Once required, we need a new instance with our secret var adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET }); بعد ذلك ، يمكننا إنشاء وظيفتنا. سنبدأ ببناء استعلامنا الأول باستخدام طرق مضمنة في برنامج التشغيل. سيعود هذا الجزء الأول من الكود إلى مراجع قاعدة البيانات التي يمكننا استخدامها للحصول على البيانات الكاملة لجميع الروابط المرجعية الخاصة بنا. نستخدم طريقة Paginate ، كمساعد لإدارة حالة المؤشر إذا قررنا ترقيم البيانات قبل تسليمها إلى 11ty. في حالتنا ، سنقوم فقط بإرجاع جميع المراجع.
في هذا المثال ، أفترض أنك قمت بتثبيت FaunaDB وتوصيله عبر Netlify Dev CLI. باستخدام هذه العملية ، تحصل على متغيرات البيئة المحلية لأسرار FaunaDB. إذا لم تقم بتثبيته بهذه الطريقة أو لا تقوم بتشغيل netlify dev في مشروعك ، فستحتاج إلى حزمة مثل dotenv لإنشاء متغيرات البيئة. ستحتاج أيضًا إلى إضافة متغيرات البيئة الخاصة بك إلى تكوين موقع Netlify الخاص بك لجعل عمليات النشر تعمل لاحقًا.
adminClient.query(q.Paginate( q.Match( // Match the reference below q.Ref("indexes/all_links") // Reference to match, in this case, our all_links index ) )) .then( response => { ... })سيعيد هذا الرمز مجموعة من جميع الروابط الخاصة بنا في نموذج مرجعي. يمكننا الآن إنشاء قائمة استعلام لإرسالها إلى قاعدة البيانات الخاصة بنا.
adminClient.query(...) .then((response) => { const linkRefs = response.data; // Get just the references for the links from the response const getAllLinksDataQuery = linkRefs.map((ref) => { return q.Get(ref) // Return a Get query based on the reference passed in }) return adminClient.query(getAllLinksDataQuery).then(ret => { return ret // Return an array of all the links with full data }) }).catch(...) من هنا ، نحتاج فقط إلى تنظيف البيانات التي تم إرجاعها. هذا هو المكان الذي يأتي فيه mapBookmarks() !
mapBookmarks()
في هذه الوظيفة ، نتعامل مع جانبين من البيانات.
أولاً ، نحصل على تاريخ مجاني في FaunaDB. لأي بيانات تم إنشاؤها ، هناك خاصية طابع زمني ( ts ). لم يتم تنسيقه بطريقة تجعل مرشح التاريخ الافتراضي لـ Liquid سعيدًا ، لذا دعنا نصلح ذلك.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); ... }) } بهذه الطريقة ، يمكننا بناء كائن جديد لبياناتنا. في هذه الحالة ، سيكون لها خاصية time ، وسنستخدم عامل السبريد لتدمير كائن data لدينا لجعلها جميعًا تعيش في مستوى واحد.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); return { time: dateTime, ...bookmark.data } }) }ها هي بياناتنا قبل وظيفتنا:
{ ref: Ref(Collection("links"), "244778237839802888"), ts: 1569697568650000, data: { url: 'https://sample.com', pageTitle: 'Sample title', description: 'An escaped description goes here' } }ها هي بياناتنا بعد وظيفتنا:
{ time: 1569697568650, url: 'https://sample.com', pageTitle: 'Sample title' description: 'An escaped description goes here' }الآن ، لدينا بيانات جيدة التنسيق جاهزة للقالب الخاص بنا!

لنكتب نموذجًا بسيطًا. سنقوم بتكرار الإشارات المرجعية الخاصة بنا والتحقق من أن كل منها يحتوي على عنوان صفحة pageTitle url حتى لا نبدو سخيفًا.
<div class="bookmarks"> {% for link in bookmarks %} {% if link.url and link.pageTitle %} // confirms there's both title AND url for safety <div class="bookmark"> <h2><a href="{{ link.url }}">{{ link.pageTitle }}</a></h2> <p>Saved on {{ link.time | date: "%b %d, %Y" }}</p> {% if link.description != "" %} <p>{{ link.description }}</p> {% endif %} </div> {% endif %} {% endfor %} </div>نحن الآن نستوعب ونعرض البيانات من FaunaDB. دعنا نتوقف لحظة ونفكر في مدى روعة أن يؤدي هذا إلى عرض HTML خالص وليس هناك حاجة لجلب البيانات من جانب العميل!
لكن هذا لا يكفي حقًا لجعل هذا التطبيق مفيدًا لنا. دعنا نتوصل إلى طريقة أفضل من إضافة إشارة مرجعية في وحدة تحكم FaunaDB.
أدخل وظائف Netlify
تعد الوظيفة الإضافية لـ Netlify's Functions إحدى أسهل الطرق لنشر وظائف AWS lambda. نظرًا لعدم وجود خطوة تكوين ، فهي مثالية لمشاريع DIY حيث تريد فقط كتابة الكود.
ستعيش هذه الوظيفة على عنوان URL في مشروعك يبدو كالتالي: https://myproject.com/.netlify/functions/bookmarks بافتراض أن الملف الذي ننشئه في مجلد وظائفنا هو bookmarks.js .
التدفق الأساسي
- قم بتمرير عنوان URL كمعامل استعلام إلى عنوان URL الخاص بالوظيفة.
- استخدم الوظيفة لتحميل عنوان URL وكشط عنوان الصفحة ووصفها إذا كان ذلك متاحًا.
- قم بتنسيق تفاصيل FaunaDB.
- ادفع التفاصيل إلى مجموعة FaunaDB الخاصة بنا.
- إعادة بناء الموقع.
متطلبات
لدينا عدد قليل من الحزم التي سنحتاجها أثناء قيامنا ببناء هذا. سنستخدم سطر الأوامر netlify-lambda لبناء وظائفنا محليًا. request-promise هو الحزمة التي سنستخدمها لتقديم الطلبات. Cheerio.js هي الحزمة التي سنستخدمها لكشط عناصر محددة من صفحتنا المطلوبة (فكر في jQuery لـ Node). وأخيرًا ، سنحتاج إلى FaunaDb (والذي يجب تثبيته بالفعل.
npm install --save netlify-lambda request-promise cheerioبمجرد تثبيت ذلك ، فلنقم بتهيئة مشروعنا لبناء الوظائف وخدمةها محليًا.
سنقوم بتعديل سكربتَي "build" و "serve" في package.json لتبدو كما يلي:
"scripts": { "build": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy", "serve": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy --serve" } تحذير: حدث خطأ في برنامج تشغيل Fauna's NodeJS عند التحويل البرمجي باستخدام Webpack ، والذي تستخدمه وظائف Netlify للبناء. للتغلب على هذا ، نحتاج إلى تحديد ملف تكوين لـ Webpack. يمكنك حفظ التعليمات البرمجية التالية في ملف webpack.config.js جديد - أو موجود .
const webpack = require('webpack'); module.exports = { plugins: [ new webpack.DefinePlugin({ "global.GENTLY": false }) ] }; بمجرد وجود هذا الملف ، عندما نستخدم الأمر netlify-lambda ، سنحتاج إلى إخباره بالتشغيل من هذا التكوين. هذا هو السبب في أن سكربتنا "serve" و "build script" تستخدم قيمة --config لهذا الأمر.
وظيفة التدبير المنزلي
من أجل الحفاظ على ملف وظيفتنا الرئيسي نظيفًا قدر الإمكان ، سننشئ وظائفنا في دليل bookmarks منفصل ونقوم باستيرادها إلى ملف وظيفتنا الرئيسي.
import { getDetails, saveBookmark } from "./bookmarks/create"; getDetails(url)
ستأخذ وظيفة getDetails() عنوان URL ، يتم تمريره من معالجنا المُصدَّر. من هناك ، سنصل إلى الموقع على عنوان URL هذا ونحصل على الأجزاء ذات الصلة من الصفحة لتخزينها كبيانات للإشارة المرجعية الخاصة بنا.
نبدأ بطلب حزم NPM التي نحتاجها:
const rp = require('request-promise'); const cheerio = require('cheerio'); بعد ذلك ، سنستخدم وحدة الوعد- request-promise لإرجاع سلسلة HTML للصفحة المطلوبة وتمريرها إلى cheerio jQuery-esque للغاية.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); ... }من هنا ، نحتاج إلى الحصول على عنوان الصفحة ووصف التعريف. للقيام بذلك ، سنستخدم المحددات كما تفعل في jQuery.
ملاحظة: في هذا الكود ، نستخدم 'head > title' كمحدد للحصول على عنوان الصفحة. إذا لم تحدد ذلك ، فقد ينتهي بك الأمر بالحصول على علامات <title> داخل جميع SVGs على الصفحة ، وهذا أقل من مثالي.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); const title = $('head > title').text(); // Get the text inside the tag const description = $('meta[name="description"]').attr('content'); // Get the text of the content attribute // Return out the data in the structure we expect return { pageTitle: title, description: description }; }); return data //return to our main function }مع وجود البيانات في متناول اليد ، فقد حان الوقت لإرسال الإشارة المرجعية إلى مجموعتنا في FaunaDB!
saveBookmark(details)
بالنسبة لوظيفة الحفظ الخاصة بنا ، سنرغب في تمرير التفاصيل التي حصلنا عليها من getDetails بالإضافة إلى عنوان URL ككائن واحد. عامل انتشار الضربات مرة أخرى!
const savedResponse = await saveBookmark({url, ...details}); في ملف create.js بنا ، نحتاج أيضًا إلى طلب وإعداد برنامج تشغيل FaunaDB الخاص بنا. يجب أن يبدو هذا مألوفًا جدًا من ملف البيانات 11ty الخاص بنا.
const faunadb = require('faunadb'), q = faunadb.query; const adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET });بمجرد أن نحصل على ذلك بعيدًا ، يمكننا البرمجة.
أولاً ، نحتاج إلى تنسيق التفاصيل الخاصة بنا في بنية بيانات تتوقعها Fauna لاستعلامنا. تتوقع Fauna كائنًا بخاصية بيانات تحتوي على البيانات التي نرغب في تخزينها.
const saveBookmark = async function(details) { const data = { data: details }; ... }ثم سنفتح استعلامًا جديدًا لإضافته إلى مجموعتنا. في هذه الحالة ، سنستخدم مساعد الاستعلام الخاص بنا ونستخدم طريقة الإنشاء. يأخذ إنشاء () وسيطتين. الأول هو المجموعة التي نريد تخزين بياناتنا فيها والثاني هو البيانات نفسها.
بعد أن نحفظ ، نعيد إما النجاح أو الفشل إلى معالجنا.
const saveBookmark = async function(details) { const data = { data: details }; return adminClient.query(q.Create(q.Collection("links"), data)) .then((response) => { /* Success! return the response with statusCode 200 */ return { statusCode: 200, body: JSON.stringify(response) } }).catch((error) => { /* Error! return the error with statusCode 400 */ return { statusCode: 400, body: JSON.stringify(error) } }) }دعنا نلقي نظرة على ملف الوظيفة الكامل.
import { getDetails, saveBookmark } from "./bookmarks/create"; import { rebuildSite } from "./utilities/rebuild"; // For rebuilding the site (more on that in a minute) exports.handler = async function(event, context) { try { const url = event.queryStringParameters.url; // Grab the URL const details = await getDetails(url); // Get the details of the page const savedResponse = await saveBookmark({url, ...details}); //Save the URL and the details to Fauna if (savedResponse.statusCode === 200) { // If successful, return success and trigger a Netlify build await rebuildSite(); return { statusCode: 200, body: savedResponse.body } } else { return savedResponse //or else return the error } } catch (err) { return { statusCode: 500, body: `Error: ${err}` }; } }; rebuildSite()
ستلاحظ العين الفطنة أن لدينا وظيفة أخرى تم استيرادها إلى معالجنا: rebuildSite() . ستستخدم هذه الوظيفة وظيفة Deploy Hook في Netlify لإعادة بناء موقعنا من البيانات الجديدة في كل مرة نقوم فيها بإرسال حفظ إشارة مرجعية جديد - ناجح.
في إعدادات موقعك في Netlify ، يمكنك الوصول إلى إعدادات البناء والنشر وإنشاء "خطاف بناء" جديد. الخطافات لها اسم يظهر في قسم النشر وخيار لفرع غير رئيسي للنشر إذا كنت ترغب في ذلك. في حالتنا ، سنسميها "new_link" ونشر فرعنا الرئيسي.
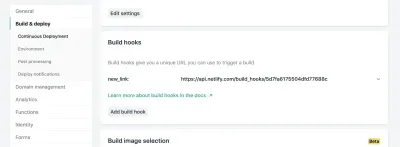
من هناك ، نحتاج فقط إلى إرسال طلب POST إلى عنوان URL المقدم.
نحتاج إلى طريقة لتقديم الطلبات ، وبما أننا قمنا بالفعل بتثبيت request-promise ، فسوف نستمر في استخدام هذه الحزمة من خلال طلبها في أعلى ملفنا.
const rp = require('request-promise'); const rebuildSite = async function() { var options = { method: 'POST', uri: 'https://api.netlify.com/build_hooks/5d7fa6175504dfd43377688c', body: {}, json: true }; const returned = await rp(options).then(function(res) { console.log('Successfully hit webhook', res); }).catch(function(err) { console.log('Error:', err); }); return returned } إعداد اختصار iOS
لذلك ، لدينا قاعدة بيانات ، وطريقة لعرض البيانات ووظيفة لإضافة البيانات ، لكننا ما زلنا غير سهل الاستخدام.
يوفر Netlify عناوين URL لوظائف Lambda الخاصة بنا ، ولكن ليس من الممتع الكتابة في جهاز محمول. سيتعين علينا أيضًا تمرير عنوان URL كمعامل استعلام إليه. هذا جهد كبير. كيف يمكننا أن نبذل هذا بأقل جهد ممكن؟
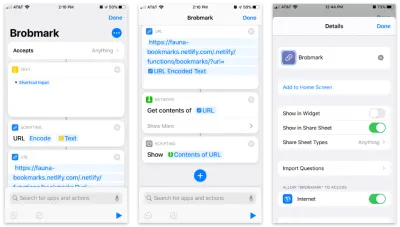
يسمح تطبيق اختصارات Apple ببناء عناصر مخصصة لتنتقل إلى ورقة المشاركة الخاصة بك. داخل هذه الاختصارات ، يمكننا إرسال أنواع مختلفة من طلبات البيانات التي تم جمعها في عملية المشاركة.
إليك الاختصار خطوة بخطوة:
- اقبل أي عناصر وقم بتخزين هذا العنصر في كتلة "نصية".
- قم بتمرير هذا النص إلى كتلة "البرمجة النصية" لتشفير عنوان URL (فقط في حالة).
- قم بتمرير هذه السلسلة إلى كتلة عنوان URL باستخدام عنوان URL الخاص بوظيفة Netlify ومعلمة الاستعلام الخاصة بعنوان
url. - من "الشبكة" ، استخدم كتلة "الحصول على المحتويات" إلى POST إلى JSON إلى عنوان URL الخاص بنا.
- اختياري: من "برمجة" "إظهار" محتويات الخطوة الأخيرة (لتأكيد البيانات التي نرسلها).
للوصول إلى هذا من قائمة المشاركة ، نفتح إعدادات هذا الاختصار وتبديل الخيار "إظهار في ورقة المشاركة".
اعتبارًا من iOS13 ، يمكن تفضيل "الإجراءات" المشتركة هذه ونقلها إلى موضع عالٍ في مربع الحوار.
لدينا الآن "تطبيق" فعال لمشاركة الإشارات المرجعية عبر منصات متعددة!
اذهب إلى الميل الإضافي!
إذا كنت مصدر إلهام لتجربة هذا بنفسك ، فهناك الكثير من الاحتمالات الأخرى لإضافة وظائف. إن متعة شبكة الويب DIY هي أنه يمكنك جعل هذه الأنواع من التطبيقات تعمل من أجلك. إليك بعض الأفكار:
- استخدم "مفتاح API" زائفًا للمصادقة السريعة ، حتى لا يقوم المستخدمون الآخرون بالنشر على موقعك (يستخدم لي مفتاح واجهة برمجة التطبيقات ، لذا لا تحاول النشر عليه!).
- إضافة وظيفة العلامات لتنظيم الإشارات.
- أضف موجز RSS لموقعك حتى يتمكن الآخرون من الاشتراك فيه.
- أرسل تقريرًا أسبوعيًا عبر البريد الإلكتروني برمجيًا للروابط التي أضفتها.
حقًا ، السماء هي الحد الأقصى ، لذا ابدأ بالتجربة!