دليل المبتدئين للشبكة العصبية التلافيفية (CNN)
نشرت: 2021-07-05شهد العقد الماضي نموًا هائلاً في الذكاء الاصطناعي والآلات الأكثر ذكاءً. لقد أدى هذا المجال إلى ظهور العديد من التخصصات الفرعية المتخصصة في جوانب متميزة من الذكاء البشري. على سبيل المثال ، تحاول معالجة اللغة الطبيعية فهم الكلام البشري ونمذجه ، بينما تهدف رؤية الكمبيوتر إلى توفير رؤية شبيهة بالإنسان للآلات.
نظرًا لأننا سنتحدث عن الشبكات العصبية التلافيفية ، فإن تركيزنا سيكون في الغالب على رؤية الكمبيوتر. تهدف رؤية الكمبيوتر إلى تمكين الآلات من رؤية العالم كما نفعل وحل المشكلات المتعلقة بالتعرف على الصور وتصنيف الصور وغير ذلك الكثير. تُستخدم الشبكات العصبية التلافيفية لتحقيق مهام مختلفة للرؤية الحاسوبية. تُعرف أيضًا باسم CNN أو ConvNet ، وهي تتبع بنية تشبه أنماط ووصلات الخلايا العصبية في الدماغ البشري ، وهي مستوحاة من العمليات البيولوجية المختلفة التي تحدث في الدماغ لتحقيق التواصل.
جدول المحتويات
الأهمية البيولوجية للشبكة العصبية الملتوية
CNNs مستوحاة من القشرة البصرية لدينا. إنها منطقة القشرة الدماغية التي تشارك في المعالجة البصرية في دماغنا. تحتوي القشرة البصرية على مناطق خلوية صغيرة مختلفة حساسة للمنبهات البصرية.
تم توسيع هذه الفكرة في عام 1962 بواسطة Hubel and Wiesel في تجربة حيث وجد أن خلايا عصبية مختلفة مختلفة تستجيب (يتم إطلاقها) لوجود حواف مميزة لاتجاه معين. على سبيل المثال ، قد تطلق بعض الخلايا العصبية على اكتشاف الحواف الأفقية ، والبعض الآخر على اكتشاف الحواف القطرية ، والبعض الآخر يطلق النار عند اكتشاف الحواف الرأسية. من خلال هذه التجربة. اكتشف Hubel و Wiesel أن الخلايا العصبية منظمة بطريقة معيارية ، وأن جميع الوحدات معًا مطلوبة لإنتاج الإدراك البصري.
هذا النهج المعياري - فكرة أن المكونات المتخصصة داخل النظام لها مهام محددة - هي التي تشكل أساس شبكات CNN.
بعد تسوية ذلك ، دعنا ننتقل إلى كيفية تعلم شبكات CNN إدراك المدخلات المرئية.

التعلم الشبكي العصبي التلافيفي
تتكون الصور من وحدات بكسل فردية ، وهي تمثيل بين الأرقام 0 و 255. لذلك ، يمكن تحويل أي صورة تراها إلى تمثيل رقمي مناسب باستخدام هذه الأرقام - وهذه هي الطريقة التي تعمل بها أجهزة الكمبيوتر أيضًا مع الصور.
فيما يلي بعض العمليات الرئيسية التي تدخل في جعل شبكة CNN تتعلم اكتشاف الصور أو تصنيفها. سيعطيك هذا فكرة عن كيفية حدوث التعلم في شبكات CNN.
1. الالتواء
يمكن فهم الالتفاف رياضيًا على أنه تكامل مشترك لوظيفتين مختلفتين لمعرفة كيفية تأثير الوظيفة المختلفة أو تعديل بعضها البعض. إليك كيف يمكن تعريفها من الناحية الرياضية:
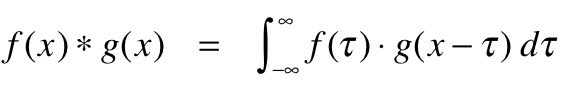
الغرض من الالتفاف هو اكتشاف الميزات المرئية المختلفة في الصور ، مثل الخطوط والحواف والألوان والظلال والمزيد. هذه خاصية مفيدة للغاية لأنه بمجرد أن تتعلم شبكة CNN الخاصة بك خصائص ميزة معينة في الصورة ، يمكنها فيما بعد التعرف على هذه الميزة في أي جزء آخر من الصورة.
تستخدم شبكات CNN النواة أو المرشحات لاكتشاف الميزات المختلفة الموجودة في أي صورة. النواة هي مجرد مصفوفة من القيم المميزة (المعروفة باسم الأوزان في عالم الشبكات العصبية الاصطناعية) المدربة على اكتشاف ميزات معينة. يتحرك المرشح فوق الصورة بأكملها للتحقق مما إذا تم اكتشاف وجود أي ميزة أم لا. ينفذ المرشح عملية الالتواء لتوفير قيمة نهائية تمثل مدى الثقة في وجود ميزة معينة.
إذا كانت الميزة موجودة في الصورة ، فإن نتيجة عملية الالتفاف هي رقم موجب ذو قيمة عالية. إذا كانت الميزة غير موجودة ، ينتج عن عملية الالتفاف 0 أو رقم ذو قيمة منخفضة جدًا.
دعونا نفهم هذا بشكل أفضل باستخدام مثال. في الصورة أدناه ، تم تدريب مرشح لاكتشاف علامة الجمع. بعد ذلك ، يتم تمرير المرشح فوق الصورة الأصلية. نظرًا لأن جزءًا من الصورة الأصلية يحتوي على نفس الميزات التي تم تدريب المرشح عليها ، فإن القيم في كل خلية حيث توجد الميزة هي رقم موجب. وبالمثل ، فإن نتيجة عملية الالتواء ستؤدي أيضًا إلى عدد كبير.
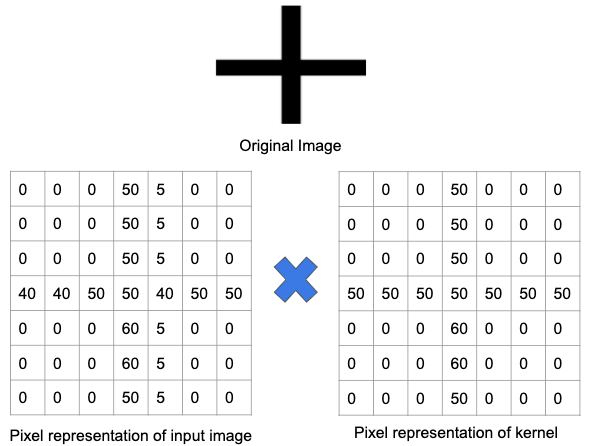
ومع ذلك ، عندما يتم تمرير نفس المرشح فوق صورة بمجموعة مختلفة من الميزات والحواف ، سيكون ناتج عملية الالتفاف أقل - مما يعني عدم وجود أي وجود قوي لأي علامة زائد في الصورة.
لذلك ، في حالة الصور المعقدة التي تحتوي على ميزات مختلفة مثل المنحنيات والحواف والألوان وما إلى ذلك ، سنحتاج إلى عدد N من أجهزة الكشف عن الميزات.
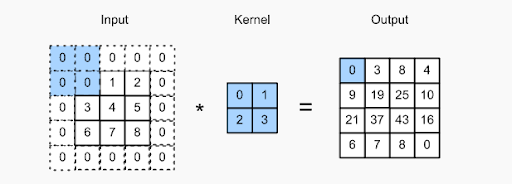
عندما يتم تمرير هذا المرشح عبر الصورة ، يتم إنشاء خريطة المعالم والتي تمثل أساسًا مصفوفة الإخراج التي تخزن التفافات هذا المرشح على أجزاء مختلفة من الصورة. في حالة وجود العديد من المرشحات ، سننتهي بإخراج ثلاثي الأبعاد. يجب أن يكون لهذا المرشح نفس عدد القنوات مثل صورة الإدخال حتى تحدث عملية الالتواء.
علاوة على ذلك ، يمكن تمرير مرشح فوق صورة الإدخال على فترات زمنية مختلفة ، باستخدام قيمة الخطوة. تبلغ قيمة الخطوة مقدار تحرك المرشح في كل خطوة.
لذلك يمكن تحديد عدد طبقات الإخراج لكتلة تلافيفية معينة باستخدام الصيغة التالية:

2. الحشو
إحدى المشكلات أثناء العمل مع الطبقات التلافيفية هي أن بعض وحدات البكسل تميل إلى الفقد في محيط الصورة الأصلية. نظرًا لأن المرشحات المستخدمة صغيرة بشكل عام ، فقد تكون وحدات البكسل المفقودة لكل مرشح قليلة ، ولكن هذا يضيف لأننا نطبق طبقات تلافيفية مختلفة ، مما يؤدي إلى فقد العديد من وحدات البكسل.
يدور مفهوم الحشو حول إضافة وحدات بكسل إضافية إلى الصورة أثناء قيام مرشح شبكة CNN بمعالجتها. هذا هو أحد الحلول لمساعدة المرشح في معالجة الصور - عن طريق حشو الصورة بالأصفار للسماح بمساحة أكبر للنواة لتغطية الصورة بأكملها. بإضافة أي حشوات إلى المرشحات ، تكون معالجة الصور بواسطة CNN أكثر دقة ودقة.

تحقق من الصورة أعلاه - تم عمل الحشو بإضافة أصفار إضافية عند حدود الصورة المدخلة. يتيح ذلك التقاط جميع الميزات المميزة دون فقد أي وحدات بكسل.
3. خريطة التنشيط
تحتاج خرائط المعالم إلى أن يتم تمريرها من خلال وظيفة تعيين غير خطية بطبيعتها. يتم تضمين خرائط الميزات مع مصطلح التحيز ثم يتم تمريرها من خلال وظيفة التنشيط (ReLu) ، وهي وظيفة غير خطية. تهدف هذه الوظيفة إلى جلب قدر من اللاخطية إلى شبكة CNN نظرًا لأن الصور التي يتم اكتشافها وفحصها هي أيضًا غير خطية بطبيعتها ، وتتكون من كائنات مختلفة.
4. مرحلة التجميع
بمجرد انتهاء مرحلة التنشيط ، ننتقل إلى خطوة التجميع ، حيث تقوم CNN بتدوين عينات الميزات الملتفة ، مما يساعد على توفير وقت المعالجة. يساعد هذا أيضًا في تقليل الحجم الكلي للصورة ، والتركيب الزائد ، والمشكلات الأخرى التي قد تحدث إذا تم تغذية الشبكات العصبية الملتوية بالكثير من المعلومات - خاصةً إذا لم تكن هذه المعلومات ذات صلة كبيرة بتصنيف الصورة أو اكتشافها.
يتكون التجميع أساسًا من نوعين - الحد الأقصى للتجميع والتجميع الأدنى. في السابق ، يتم تمرير نافذة فوق الصورة وفقًا لقيمة خطوة محددة ، وفي كل خطوة ، يتم تجميع القيمة القصوى المدرجة في النافذة في مصفوفة الإخراج. في min pooling ، يتم تجميع القيم الدنيا في مصفوفة الإخراج.
تسمى المصفوفة الجديدة التي تشكلت كنتيجة للمخرجات بخريطة المعالم المجمعة.
من بين الحد الأدنى والحد الأقصى للتجميع ، تتمثل إحدى فوائد التجميع الأقصى في أنه يسمح لشبكة CNN بالتركيز على عدد قليل من الخلايا العصبية التي لها قيم عالية بدلاً من التركيز على جميع الخلايا العصبية. مثل هذا النهج يجعله أقل احتمالا لتلائم بيانات التدريب ويجعل التنبؤ العام والتعميم يسير على ما يرام.
5. التسطيح
بعد الانتهاء من التجميع ، تم الآن تحويل التمثيل ثلاثي الأبعاد للصورة إلى ناقل ميزة. ثم يتم تمرير هذا إلى مدرك متعدد الطبقات لإنتاج المخرجات. تحقق من الصورة أدناه لفهم عملية التسطيح بشكل أفضل:
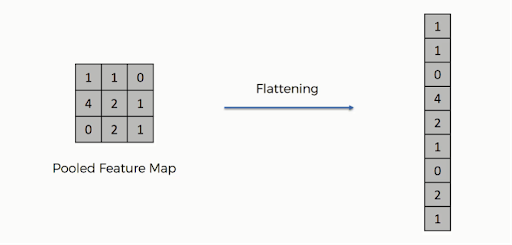
كما ترى ، فإن صفوف المصفوفة متسلسلة في متجه ميزة واحد. في حالة وجود طبقات إدخال متعددة ، يتم توصيل كل الصفوف لتشكيل متجه معالم مسطح أطول.
6. طبقة متصلة بالكامل (FCL)
في هذه الخطوة ، يتم تغذية الخريطة المسطحة إلى شبكة عصبية. يتضمن الاتصال الكامل للشبكة العصبية طبقة إدخال ، و FCL ، وطبقة إخراج نهائية. يمكن فهم الطبقة المتصلة بالكامل على أنها الطبقات المخفية في الشبكات العصبية الاصطناعية ، باستثناء ، على عكس الطبقات المخفية ، هذه الطبقات متصلة بالكامل. تمر المعلومات عبر الشبكة بالكامل ، ويتم حساب خطأ تنبؤ. ثم يتم إرسال هذا الخطأ كرد فعل (backpropagation) من خلال الأنظمة لضبط الأوزان وتحسين الناتج النهائي ، لجعله أكثر دقة.
الناتج النهائي الذي تم الحصول عليه من الطبقة أعلاه للشبكة العصبية لا يضيف بشكل عام ما يصل إلى واحد. يجب إنزال هذه المخرجات إلى أرقام في النطاق [0،1] - والتي ستمثل بعد ذلك احتمالات كل فئة. لهذا ، يتم استخدام وظيفة Softmax.
يتم تغذية الإخراج الناتج من الطبقة الكثيفة إلى وظيفة تنشيط Softmax. من خلال هذا ، يتم تعيين جميع المخرجات النهائية إلى متجه حيث يظهر مجموع كل العناصر ليكون واحدًا.
تعمل الطبقة المتصلة بالكامل من خلال النظر إلى إخراج الطبقة السابقة ثم تحديد الميزة الأكثر ارتباطًا بفئة معينة. وبالتالي ، إذا توقع البرنامج ما إذا كانت الصورة تحتوي على قطة أم لا ، فسيكون لها قيم عالية في خرائط التنشيط التي تمثل ميزات مثل أربعة أرجل ، وكفوف ، وذيل ، وما إلى ذلك. وبالمثل ، إذا كان البرنامج يتنبأ بشيء آخر ، فسيكون لديه أنواع مختلفة من خرائط التنشيط. تعتني الطبقة المتصلة تمامًا بالميزات المختلفة التي ترتبط ارتباطًا وثيقًا بفئات وأوزان معينة بحيث يكون الحساب بين الأوزان والطبقة السابقة دقيقًا ، وتحصل على احتمالات صحيحة لفئات مختلفة من المخرجات.
ملخص سريع لعمل السي إن إن
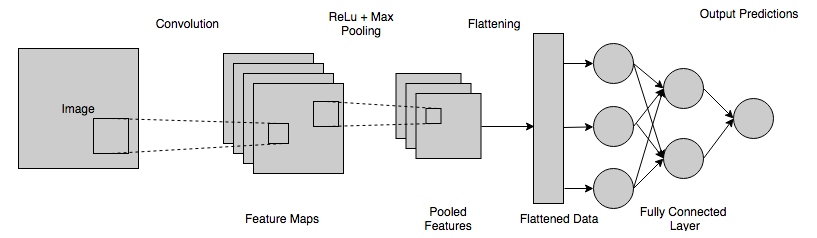
فيما يلي ملخص سريع للعملية الكاملة لكيفية عمل CNN وتساعد في رؤية الكمبيوتر:
- يتم تغذية وحدات البكسل المختلفة من الصورة إلى الطبقة التلافيفية ، حيث يتم إجراء عملية التفاف.
- ينتج عن الخطوة السابقة خريطة ملتفة.
- يتم تمرير هذه الخريطة من خلال وظيفة المعدل لتكوين خريطة مصححة.
- تتم معالجة الصورة باستخدام تلافيفات ووظائف تنشيط مختلفة لتحديد مواقع الميزات المختلفة واكتشافها.
- تُستخدم طبقات التجميع لتحديد أجزاء محددة ومميزة من الصورة.
- يتم تسطيح الطبقة المجمعة واستخدامها كمدخل للطبقة المتصلة بالكامل.
- تحسب الطبقة المتصلة بالكامل الاحتمالات وتعطي ناتجًا في نطاق [0،1].
ختاما
إن الأداء الداخلي لـ CNN مثير للغاية ويفتح الكثير من الاحتمالات للابتكار والإبداع. وبالمثل ، فإن التقنيات الأخرى تحت مظلة الذكاء الاصطناعي رائعة وتحاول العمل بين القدرات البشرية والذكاء الآلي. وبالتالي ، فإن الأشخاص من جميع أنحاء العالم ، الذين ينتمون إلى مجالات مختلفة ، يدركون اهتمامهم بهذا المجال ويتخذون الخطوات الأولى.
لحسن الحظ ، فإن صناعة الذكاء الاصطناعي ترحب بشكل استثنائي ولا تميز بناءً على خلفيتك الأكاديمية. كل ما تحتاجه هو معرفة عملية بالتقنيات جنبًا إلى جنب مع المؤهلات الأساسية ، وأنت جاهز تمامًا!
إذا كنت ترغب في إتقان التفاصيل الجوهرية لـ ML و AI ، فإن المسار المثالي للعمل هو التسجيل في برنامج AI / ML احترافي. على سبيل المثال ، يعد برنامجنا التنفيذي في التعلم الآلي والذكاء الاصطناعي الدورة التدريبية المثالية لطامبي علوم البيانات. يغطي البرنامج مواضيع مثل الإحصاءات وتحليلات البيانات الاستكشافية والتعلم الآلي ومعالجة اللغة الطبيعية. يتضمن أيضًا أكثر من 13 مشروعًا صناعيًا و 25+ جلسة مباشرة و 6 مشاريع تتويجا. أفضل جزء في هذه الدورة هو أنك تتفاعل مع أقرانك من جميع أنحاء العالم. يسهل تبادل الأفكار ويساعد المتعلمين على بناء علاقات دائمة مع أشخاص من خلفيات متنوعة. إن مساعدتنا المهنية بزاوية 360 درجة هي فقط ما تحتاجه للتميز في رحلتك في تعلم الآلة والذكاء الاصطناعي!
قيادة الثورة التكنولوجية التي يقودها الذكاء الاصطناعي