
6 ميزات لتغيير اللعبة في Apache Spark في عام 2022 [كيف يجب أن تستخدم]
نشرت: 2021-01-07منذ أن استحوذت البيانات الضخمة على عالم التكنولوجيا والأعمال ، حدثت زيادة هائلة في أدوات ومنصات البيانات الضخمة ، لا سيما منصات Apache Hadoop و Apache Spark. اليوم ، سنركز فقط على Apache Spark ونناقش مطولاً حول فوائدها التجارية وتطبيقاتها.
ظهرت أباتشي سبارك في دائرة الضوء في عام 2009 ، ومنذ ذلك الحين ، تمكنت تدريجياً من نحت مكانة خاصة بها في هذه الصناعة. وفقًا لمؤسسة Apache ، فإن Spark هو "محرك تحليلات موحد سريع البرق" مصمم لمعالجة كميات هائلة من البيانات الضخمة. بفضل المجتمع النشط ، تعد Spark اليوم واحدة من أكبر منصات البيانات الضخمة مفتوحة المصدر في العالم.
جدول المحتويات
ما هو اباتشي سبارك؟
تم تطوير Spark في الأصل في مختبر AMPLab التابع لجامعة كاليفورنيا (بيركلي) ، وقد تم تصميمه كمحرك معالجة قوي لبيانات Hadoop ، مع التركيز بشكل خاص على السرعة وسهولة الاستخدام. إنه بديل مفتوح المصدر لبرنامج MapReduce Hadoop. بشكل أساسي ، يعد Spark إطارًا متوازيًا لمعالجة البيانات يمكنه التعاون مع Apache Hadoop لتسهيل التطوير السلس والسريع لتطبيقات البيانات الضخمة المعقدة على Hadoop.
يأتي Spark مليئًا بمجموعة واسعة من المكتبات لخوارزميات التعلم الآلي (ML) وخوارزميات الرسم البياني. ليس ذلك فحسب ، فهو يدعم أيضًا البث في الوقت الفعلي وتطبيقات SQL عبر Spark Streaming و Shark ، على التوالي. أفضل جزء في استخدام Spark هو أنه يمكنك كتابة تطبيقات Spark بلغة Java أو Scala أو حتى Python ، وستعمل هذه التطبيقات أسرع عشر مرات (على القرص) وأسرع 100 مرة (في الذاكرة) من تطبيقات MapReduce.
يعد Apache Spark متعدد الاستخدامات حيث يمكن نشره بعدة طرق ، كما أنه يوفر روابط أصلية للغات برمجة Java و Scala و Python و R. وهو يدعم SQL ومعالجة الرسوم البيانية وتدفق البيانات والتعلم الآلي. هذا هو السبب في استخدام Spark على نطاق واسع في مختلف قطاعات الصناعة ، بما في ذلك البنوك وشركات الاتصالات وشركات تطوير الألعاب والوكالات الحكومية وبالطبع في جميع الشركات الكبرى في عالم التكنولوجيا - Apple و Facebook و IBM و Microsoft.
6 أفضل ميزات Apache Spark
الميزات التي تجعل Spark واحدة من أكثر منصات البيانات الضخمة استخدامًا هي:

1. سرعة معالجة الإضاءة بسرعة
تتمحور معالجة البيانات الضخمة حول معالجة كميات كبيرة من البيانات المعقدة. ومن ثم ، عندما يتعلق الأمر بمعالجة البيانات الضخمة ، فإن المؤسسات والشركات تريد مثل هذه الأطر التي يمكنها معالجة كميات هائلة من البيانات بسرعة عالية. كما ذكرنا سابقًا ، يمكن أن تعمل تطبيقات Spark أسرع في الذاكرة بما يصل إلى 100x وأسرع 10 مرات على القرص في مجموعات Hadoop.
يعتمد على مجموعة البيانات الموزعة المرنة (RDD) التي تسمح لـ Spark بتخزين البيانات بشفافية على الذاكرة وقراءتها / كتابتها على القرص فقط إذا لزم الأمر. يساعد هذا في تقليل معظم وقت قراءة القرص وكتابته أثناء معالجة البيانات.
2. سهولة الاستخدام
يسمح لك Spark بكتابة تطبيقات قابلة للتطوير في Java و Scala و Python و R. لذا ، يحصل المطورون على نطاق لإنشاء تطبيقات Spark وتشغيلها بلغات البرمجة المفضلة لديهم. علاوة على ذلك ، تم تجهيز Spark بمجموعة مدمجة تضم أكثر من 80 مشغلًا رفيع المستوى. يمكنك استخدام Spark بشكل تفاعلي للاستعلام عن البيانات من قذائف Scala و Python و R و SQL.
3. يوفر دعمًا للتحليلات المعقدة
لا يدعم Spark عمليات "الخريطة" و "الحد" البسيطة فحسب ، ولكنه يدعم أيضًا استعلامات SQL وتدفق البيانات والتحليلات المتقدمة ، بما في ذلك خوارزميات تعلم الآلة والرسم البياني. يأتي مزودًا بمجموعة قوية من المكتبات مثل SQL & DataFrames و MLlib (لـ ML) و GraphX و Spark Streaming. الأمر المذهل هو أن Spark يتيح لك الجمع بين إمكانات جميع هذه المكتبات في سير عمل / تطبيق واحد.
4. معالجة الدفق في الوقت الحقيقي
تم تصميم Spark للتعامل مع تدفق البيانات في الوقت الفعلي. بينما تم تصميم MapReduce للتعامل مع البيانات المخزنة بالفعل في مجموعات Hadoop ومعالجتها ، يمكن لـ Spark القيام بالأمرين وكذلك معالجة البيانات في الوقت الفعلي عبر Spark Streaming.
على عكس حلول البث الأخرى ، يمكن لـ Spark Streaming استعادة العمل المفقود وتقديم الدلالات الدقيقة خارج الصندوق دون الحاجة إلى رمز أو تكوين إضافي. بالإضافة إلى ذلك ، يتيح لك أيضًا إعادة استخدام نفس الرمز لمعالجة الدُفعات والدفق وحتى لضم البيانات المتدفقة إلى البيانات التاريخية.
5. إنه مرن
يمكن تشغيل Spark بشكل مستقل في وضع المجموعة ، ويمكن أيضًا تشغيله على Hadoop YARN و Apache Mesos و Kubernetes وحتى في السحابة. علاوة على ذلك ، يمكنه الوصول إلى مصادر بيانات متنوعة. على سبيل المثال ، يمكن تشغيل Spark على مدير مجموعة YARN وقراءة أي بيانات Hadoop موجودة. يمكنه القراءة من أي مصادر بيانات Hadoop مثل HBase و HDFS و Hive و Cassandra. هذا الجانب من Spark يجعله أداة مثالية لترحيل تطبيقات Hadoop النقية ، بشرط أن تكون حالة استخدام التطبيقات صديقة للشرر.
6. المجتمع النشط والمتوسع
ساهم مطورو أكثر من 300 شركة في تصميم وبناء Apache Spark. منذ عام 2009 ، ساهم أكثر من 1200 مطور بنشاط في جعل Spark ما هو عليه اليوم! بطبيعة الحال ، فإن Spark مدعومة من قبل مجتمع نشط من المطورين الذين يعملون على تحسين ميزاتها وأدائها باستمرار. للوصول إلى مجتمع Spark ، يمكنك الاستفادة من القوائم البريدية لأي استفسارات ، ويمكنك أيضًا حضور مجموعات اجتماعات Spark ومؤتمراتها.
تشريح تطبيقات الشرارة
يتكون كل تطبيق من تطبيقات Spark من عمليتين أساسيتين - عملية محرك أساسية ومجموعة من عمليات المنفذ .

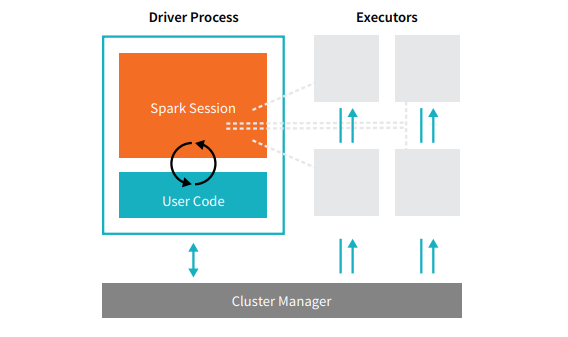
مصدر
عملية السائق التي تقع على عقدة في الكتلة هي المسؤولة عن تشغيل الدالة main (). كما أنه يتعامل مع ثلاث مهام أخرى - الحفاظ على المعلومات حول تطبيق Spark ، والاستجابة لرمز المستخدم أو إدخاله ، وتحليل وتوزيع وجدولة العمل عبر المنفذين. تشكل عملية السائق قلب تطبيق Spark - فهي تحتوي على جميع المعلومات الهامة التي تغطي عمر تطبيق Spark وتحافظ عليها.
المنفذون أو عمليات المنفذ هي عناصر ثانوية يجب أن تنفذ المهمة المعينة لهم من قبل السائق. بشكل أساسي ، يؤدي كل منفذ وظيفتين أساسيتين - تشغيل الكود المعين له من قبل السائق والإبلاغ عن حالة الحساب (على ذلك المنفذ) إلى عقدة السائق. يمكن للمستخدمين تحديد وتكوين عدد المنفذين الذي يجب أن تمتلكه كل عقدة.
في تطبيق Spark ، يتحكم مدير الكتلة في جميع الأجهزة ويخصص الموارد للتطبيق. هنا ، يمكن أن يكون مدير المجموعة أيًا من مديري المجموعة الأساسية في Spark ، بما في ذلك YARN (مدير مجموعة Spark المستقل) أو Mesos. هذا يستلزم أن الكتلة يمكنها تشغيل تطبيقات Spark متعددة في وقت واحد.
تطبيقات أباتشي سبارك في العالم الحقيقي
Spark هي منصة Big Dara الأعلى تصنيفًا والمستخدمة على نطاق واسع في الصناعة الحديثة. بعض الأمثلة الواقعية الأكثر شهرة لتطبيقات Apache Spark هي:
شرارة لتعلم الآلة
تفتخر Apache Spark بمكتبة التعلم الآلي القابلة للتطوير - MLlib. تم تصميم هذه المكتبة بشكل صريح للبساطة وقابلية التوسع وتسهيل التكامل السلس مع الأدوات الأخرى. لا يمتلك MLlib قابلية التوسع والتوافق اللغوي وسرعة Spark فحسب ، بل يمكنه أيضًا إجراء مجموعة من مهام التحليلات المتقدمة مثل التصنيف والتجميع وتقليل الأبعاد. بفضل MLlib ، يمكن استخدام Spark للتحليل التنبئي وتحليل المشاعر وتجزئة العملاء والذكاء التنبئي.
ميزة أخرى رائعة من Apache Spark تكمن في مجال أمان الشبكة. يسمح Spark Streaming للمستخدمين بمراقبة حزم البيانات في الوقت الفعلي قبل دفعها إلى التخزين. خلال هذه العملية ، يمكنه التعرف بنجاح على أي أنشطة مشبوهة أو ضارة تنشأ من مصادر التهديد المعروفة. حتى بعد إرسال حزم البيانات إلى التخزين ، يستخدم Spark MLlib لتحليل البيانات بشكل أكبر وتحديد المخاطر المحتملة على الشبكة. يمكن أيضًا استخدام هذه الميزة للكشف عن الاحتيال والأحداث.
سبارك لحوسبة الضباب
Apache Spark هي أداة ممتازة لحوسبة الضباب ، خاصة عندما يتعلق الأمر بإنترنت الأشياء (IoT). تعتمد إنترنت الأشياء بشكل كبير على مفهوم المعالجة المتوازية واسعة النطاق. نظرًا لأن شبكة إنترنت الأشياء تتكون من آلاف وملايين الأجهزة المتصلة ، فإن البيانات التي يتم إنشاؤها بواسطة هذه الشبكة كل ثانية لا يمكن فهمها.
بطبيعة الحال ، لمعالجة مثل هذه الكميات الكبيرة من البيانات التي تنتجها أجهزة إنترنت الأشياء ، فإنك تحتاج إلى نظام أساسي قابل للتطوير يدعم المعالجة المتوازية. وما هو أفضل من بنية Spark القوية وقدرات حوسبة الضباب للتعامل مع مثل هذه الكميات الهائلة من البيانات!
تعمل حوسبة الضباب على إضفاء اللامركزية على البيانات والتخزين ، وبدلاً من استخدام المعالجة السحابية ، فإنها تؤدي وظيفة معالجة البيانات على حافة الشبكة (المضمنة بشكل أساسي في أجهزة إنترنت الأشياء).
للقيام بذلك ، تتطلب حوسبة الضباب ثلاث قدرات ، وهي الكمون المنخفض والمعالجة المتوازية لـ ML وخوارزميات تحليلات الرسم البياني المعقدة - كل منها موجود في Spark. علاوة على ذلك ، فإن وجود Spark Streaming و Shark (أداة استعلام تفاعلية يمكن أن تعمل في الوقت الفعلي) و MLlib و GraphX (محرك تحليلات الرسم البياني) يعزز قدرة Spark على الحوسبة الضبابية.
سبارك للتحليل التفاعلي
على عكس MapReduce ، أو Hive ، أو Pig ، التي تتميز بسرعة معالجة منخفضة نسبيًا ، يمكن لـ Spark التباهي بالتحليلات التفاعلية عالية السرعة. إنه قادر على التعامل مع الاستفسارات الاستكشافية دون الحاجة إلى أخذ عينات من البيانات. أيضًا ، Spark متوافق مع جميع لغات التطوير الشائعة تقريبًا ، بما في ذلك R و Python و SQL و Java و Scala.
يتميز أحدث إصدار من Spark - Spark 2.0 - بوظيفة جديدة تُعرف باسم التدفق المهيكل. باستخدام هذه الميزة ، يمكن للمستخدمين تشغيل استعلامات منظمة وتفاعلية ضد تدفق البيانات في الوقت الفعلي.
مستخدمي Spark
الآن بعد أن أصبحت على دراية جيدة بميزات وقدرات Spark ، دعنا نتحدث عن المستخدمين الأربعة البارزين لـ Spark!
1. ياهو
تستخدم Yahoo Spark في اثنين من مشاريعها ، أحدهما لتخصيص صفحات الأخبار للزوار والآخر لتشغيل التحليلات للإعلان. لتخصيص صفحات الأخبار ، تستخدم Yahoo خوارزميات ML المتقدمة التي تعمل على Spark لفهم اهتمامات وتفضيلات واحتياجات المستخدمين الفرديين وتصنيف القصص وفقًا لذلك.
بالنسبة لحالة الاستخدام الثانية ، تستفيد Yahoo من Hive على القدرة التفاعلية لـ Spark (للتكامل مع أي أداة يتم توصيلها بـ Hive) لعرض البيانات التحليلية الإعلانية الخاصة بـ Yahoo التي تم جمعها على Hadoop والاستعلام عنها.
2. أوبر
تستخدم أوبر Spark Streaming بالاشتراك مع Kafka و HDFS إلى ETL (استخراج وتحويل وتحميل) كميات هائلة من البيانات في الوقت الفعلي للأحداث المنفصلة إلى بيانات منظمة وقابلة للاستخدام لمزيد من التحليل. تساعد هذه البيانات أوبر على ابتكار حلول محسّنة للعملاء.

3. Conviva
كشركة دفق فيديو ، تحصل Conviva في المتوسط على أكثر من 4 ملايين تغذية فيديو كل شهر ، مما يؤدي إلى ضغوط هائلة من العملاء. وقد تفاقم هذا التحدي بسبب مشكلة إدارة حركة مرور الفيديو المباشر. لمكافحة هذه التحديات بشكل فعال ، تستخدم Conviva Spark Streaming لمعرفة ظروف الشبكة في الوقت الفعلي ولتحسين حركة مرور الفيديو الخاصة بها وفقًا لذلك. يتيح ذلك لـ Conviva توفير تجربة مشاهدة متسقة وعالية الجودة للمستخدمين.
4. بينتيريست
على موقع Pinterest ، يمكن للمستخدمين تثبيت موضوعاتهم المفضلة متى أرادوا ذلك أثناء تصفح الويب والوسائط الاجتماعية. لتقديم تجربة عملاء مخصصة ومحسّنة ، تستخدم Pinterest إمكانات Spark's ETL لتحديد الاحتياجات والاهتمامات الفريدة للمستخدمين الفرديين وتقديم التوصيات ذات الصلة لهم على Pinterest.
خاتمة
في الختام ، تعد Spark عبارة عن منصة بيانات كبيرة متعددة الاستخدامات للغاية مع ميزات تم تصميمها لإثارة إعجابك. نظرًا لأنه إطار مفتوح المصدر ، فإنه يتحسن ويتطور باستمرار ، مع إضافة ميزات ووظائف جديدة إليه. نظرًا لأن تطبيقات البيانات الضخمة أصبحت أكثر تنوعًا واتساعًا ، فستزداد أيضًا حالات استخدام Apache Spark.
إذا كنت مهتمًا بمعرفة المزيد عن البيانات الضخمة ، فراجع دبلومة PG في تخصص تطوير البرمجيات في برنامج البيانات الضخمة المصمم للمهنيين العاملين ويوفر أكثر من 7 دراسات حالة ومشاريع ، ويغطي 14 لغة وأدوات برمجة ، وتدريب عملي عملي ورش العمل ، أكثر من 400 ساعة من التعلم الصارم والمساعدة في التوظيف مع الشركات الكبرى.
تحقق من دورات هندسة البرمجيات الأخرى لدينا في upGrad.