
واجهة مستخدم صوتية بديلة لمساعدي الصوت
نشرت: 2022-03-10بالنسبة لمعظم الناس ، فإن أول ما يتبادر إلى الذهن عند التفكير في واجهات المستخدم الصوتية هو المساعد الصوتي ، مثل Siri أو Amazon Alexa أو Google Assistant. في الواقع ، المساعدون هم السياق الوحيد الذي استخدم فيه معظم الأشخاص الصوت للتفاعل مع نظام الكمبيوتر.
في حين أن المساعدين الصوتيين قد جلبوا واجهات المستخدم الصوتية إلى الاتجاه السائد ، فإن نموذج المساعد ليس هو الطريقة الوحيدة ، ولا حتى أفضل طريقة لاستخدام وتصميم وإنشاء واجهات المستخدم الصوتية.
في هذه المقالة ، سأتناول المشكلات التي يعاني منها المساعدون الصوتيون وأقدم طريقة جديدة لواجهات المستخدم الصوتي التي أسميها التفاعلات الصوتية المباشرة.
المساعدون الصوتيون هم روبوتات محادثة قائمة على الصوت
المساعد الصوتي هو جزء من برنامج يستخدم لغة طبيعية بدلاً من الرموز والقوائم كواجهة مستخدم. عادةً ما يجيب المساعدون على الأسئلة ويحاولون غالبًا بشكل استباقي مساعدة المستخدم.
بدلاً من المعاملات والأوامر المباشرة ، يقلد المساعدون محادثة بشرية ويستخدمون لغة طبيعية ثنائية الاتجاه كطريقة تفاعل ، مما يعني أنها تأخذ مدخلات من المستخدم وإجابات للمستخدم باستخدام لغة طبيعية.
كان المساعدون الأوائل هم أنظمة الإجابة على الأسئلة القائمة على الحوار. أحد الأمثلة المبكرة هو Microsoft Clippy الذي حاول بشكل سيء مساعدة مستخدمي Microsoft Office من خلال إعطائهم إرشادات بناءً على ما اعتقد أن المستخدم كان يحاول تحقيقه. في الوقت الحاضر ، حالة الاستخدام النموذجية للنموذج المساعد هي روبوتات المحادثة ، وغالبًا ما تُستخدم لدعم العملاء في مناقشة الدردشة.
من ناحية أخرى ، فإن المساعدين الصوتيين هم روبوتات محادثة تستخدم الصوت بدلاً من الكتابة والنص . مدخلات المستخدم ليست اختيارات أو نصًا بل كلامًا والاستجابة من النظام يتم نطقها بصوت عالٍ أيضًا. يمكن أن يكون هؤلاء المساعدون مساعدين عامين مثل Google Assistant أو Alexa الذين يمكنهم الإجابة على العديد من الأسئلة بطريقة معقولة أو مساعدين مخصصين تم تصميمهم لغرض خاص مثل طلب الوجبات السريعة.
على الرغم من أن مدخلات المستخدم غالبًا ما تكون مجرد كلمة أو كلمتين ويمكن تقديمها على أنها اختيارات بدلاً من نص حقيقي ، مع تطور التكنولوجيا ، ستكون المحادثات أكثر انفتاحًا وتعقيدًا . الميزة الأولى التي تحدد برامج الدردشة والمساعدين هي استخدام اللغة الطبيعية وأسلوب المحادثة بدلاً من الرموز والقوائم وأسلوب المعاملات الذي يحدد تطبيقًا نموذجيًا للجوال أو تجربة مستخدم موقع الويب.
يوصى بالقراءة : إنشاء روبوت محادثة AI بسيط باستخدام واجهة برمجة تطبيقات Web Speech و Node.js
السمة المميزة الثانية المستمدة من استجابات اللغة الطبيعية هي وهم الشخصية. تحدد النبرة والجودة واللغة التي يستخدمها النظام كلاً من تجربة المساعد ووهم التعاطف والقابلية للخدمة وشخصيتها. تشبه فكرة تجربة المساعد الجيدة الانخراط مع شخص حقيقي .
نظرًا لأن الصوت هو الطريقة الأكثر طبيعية بالنسبة لنا للتواصل ، فقد يبدو هذا رائعًا ، ولكن هناك مشكلتان رئيسيتان في استخدام الاستجابات اللغوية الطبيعية. قد يتم إصلاح إحدى هذه المشكلات ، المتعلقة بمدى قدرة أجهزة الكمبيوتر على تقليد البشر ، في المستقبل من خلال تطوير تقنيات الذكاء الاصطناعي للمحادثة ، لكن مشكلة كيفية تعامل العقول البشرية مع المعلومات هي مشكلة بشرية ، لا يمكن حلها في المستقبل المنظور. دعونا ننظر في هذه المشاكل بعد ذلك.
مشكلتان مع استجابات اللغة الطبيعية
واجهات المستخدم الصوتية هي بالطبع واجهات مستخدم تستخدم الصوت كطريقة. ولكن يمكن استخدام طريقة الصوت لكلا الاتجاهين: لإدخال المعلومات من المستخدم وإخراج المعلومات من النظام مرة أخرى إلى المستخدم. على سبيل المثال ، تستخدم بعض المصاعد تركيب الكلام لتأكيد اختيار المستخدم بعد أن يضغط المستخدم على الزر. سنناقش لاحقًا واجهات المستخدم الصوتية التي تستخدم الصوت فقط لإدخال المعلومات وتستخدم واجهات المستخدم الرسومية التقليدية لإظهار المعلومات مرة أخرى للمستخدم.
من ناحية أخرى ، يستخدم المساعدون الصوتيون الصوت لكل من الإدخال والإخراج . هذا النهج له مشكلتان رئيسيتان:
المشكلة رقم 1: تقليد فشل الإنسان
كبشر ، لدينا ميل فطري لعزو السمات الشبيهة بالبشر إلى الأشياء غير البشرية. نرى ملامح رجل في سحابة تنجرف بجانبه أو ننظر إلى شطيرة ويبدو أنه يبتسم لنا. وهذا ما يسمى التجسيم .

تنطبق هذه الظاهرة على المساعدين أيضًا ، ويتم تشغيلها من خلال استجاباتهم اللغوية الطبيعية. بينما يمكن إنشاء واجهة مستخدم رسومية محايدة إلى حد ما ، لا توجد طريقة يمكن للإنسان أن يبدأ في التفكير فيما إذا كان صوت شخص ما ينتمي إلى شخص صغير أو كبير السن أو ما إذا كان ذكرًا أم أنثى. لهذا السبب ، يبدأ المستخدم تقريبًا في التفكير في أن المساعد هو بالفعل إنسان.
ومع ذلك ، فنحن البشر جيدون جدًا في اكتشاف المنتجات المقلدة . والغريب أنه كلما اقترب شيء ما من تشابه الإنسان ، كلما بدأت الانحرافات الصغيرة في إزعاجنا. هناك شعور بالخوف تجاه شيء يحاول أن يكون شبيهًا بالإنسان ولكنه لا يرقى إلى مستوى ذلك تمامًا. يشار إلى هذا في علم الروبوتات والرسوم المتحركة بالكمبيوتر باسم "الوادي الخارق".

كلما حاولنا أن نجعل المساعد أفضل وأكثر تشابهًا مع البشر ، يمكن أن تكون تجربة المستخدم مخيبة للآمال ومخيبة للآمال عندما يحدث خطأ ما. من المحتمل أن يكون كل من جرب المساعدين قد عثر على مشكلة الاستجابة بشيء يشعر بالغباء أو حتى الوقح.
يطرح الوادي الخارق للمساعدين الصوتيين مشكلة جودة في تجربة المستخدم المساعد يصعب التغلب عليها. في الواقع ، يتم اجتياز اختبار تورينج (الذي سمي على اسم عالم الرياضيات الشهير آلان تورينج) عندما لا يستطيع المقيِّم البشري الذي يُظهر محادثة بين عاملين التمييز بين أي منهما آلة وأيها إنسان. حتى الآن ، لم يتم تمريره أبدًا.
هذا يعني أن النموذج المساعد يضع وعدًا بتجربة خدمة شبيهة بالبشر لا يمكن تحقيقها أبدًا وسيصاب المستخدم بخيبة أمل. التجارب الناجحة لا تؤدي إلا إلى خيبة الأمل النهائية ، حيث يبدأ المستخدم في الوثوق بمساعده الشبيه بالبشر.
المشكلة الثانية: التفاعلات المتسلسلة والبطيئة
المشكلة الثانية للمساعدين الصوتيين هي أن الطبيعة القائمة على الدوران لاستجابات اللغة الطبيعية تتسبب في تأخير التفاعل. هذا يرجع إلى كيفية معالجة أدمغتنا للمعلومات.
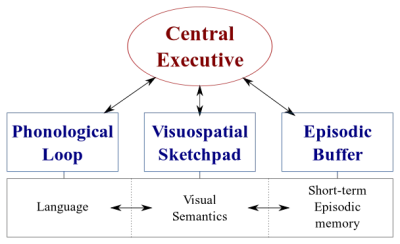
هناك نوعان من أنظمة معالجة البيانات في أدمغتنا:
- نظام لغوي يعالج الكلام ؛
- نظام بصري مكاني متخصص في معالجة المعلومات المرئية والمكانية.
يمكن أن يعمل هذان النظامان بالتوازي ، لكن كلا النظامين يعالجان شيئًا واحدًا فقط في كل مرة . هذا هو السبب في أنه يمكنك التحدث وقيادة السيارة في نفس الوقت ، ولكن لا يمكنك إرسال الرسائل النصية والقيادة لأن هذين النشاطين سيحدثان في نظام الرؤية المكانية.

وبالمثل ، عندما تتحدث إلى المساعد الصوتي ، يحتاج المساعد إلى التزام الهدوء والعكس صحيح. يؤدي هذا إلى إنشاء محادثة مبنية على أساس الدور ، حيث يكون الجزء الآخر دائمًا سلبيًا تمامًا.
مع ذلك ، ضع في اعتبارك موضوعًا صعبًا تريد مناقشته مع صديقك. ربما ستناقش وجهًا لوجه بدلاً من التحدث عبر الهاتف ، أليس كذلك؟ هذا لأنه في المحادثة وجهًا لوجه ، نستخدم التواصل غير اللفظي لتقديم ملاحظات مرئية في الوقت الفعلي لشريك المحادثة لدينا. يؤدي هذا إلى إنشاء حلقة تبادل معلومات ثنائية الاتجاه وتمكين كلا الطرفين من المشاركة بنشاط في المحادثة في وقت واحد.
لا يقدم المساعدون ملاحظات مرئية في الوقت الفعلي. إنهم يعتمدون على تقنية تسمى نقطة النهاية لتقرير متى يتوقف المستخدم عن الكلام ولا يرد إلا بعد ذلك. وعندما يردون ، لا يأخذون أي مدخلات من المستخدم في نفس الوقت. التجربة أحادية الاتجاه بالكامل وتقوم بدورها.
في محادثة ثنائية الاتجاه وفي الوقت الفعلي وجهاً لوجه ، يمكن للطرفين الرد على الفور على كل من الإشارات المرئية واللغوية. يستخدم هذا أنظمة معالجة المعلومات المختلفة للدماغ البشري وتصبح المحادثة أكثر سلاسة وكفاءة.
المساعدين الصوتيين عالقون في الوضع أحادي الاتجاه لأنهم يستخدمون لغة طبيعية كقنوات إدخال وإخراج. بينما يكون الصوت أسرع بأربع مرات من الكتابة للإدخال ، إلا أنه أبطأ كثيرًا في الهضم من القراءة. نظرًا لأن المعلومات تحتاج إلى المعالجة بالتسلسل ، فإن هذا الأسلوب يعمل جيدًا فقط مع الأوامر البسيطة مثل "إطفاء الأنوار" التي لا تتطلب الكثير من الإخراج من المساعد.

لقد وعدت سابقًا بمناقشة واجهات المستخدم الصوتية التي تستخدم الصوت فقط لإدخال البيانات من المستخدم. يستفيد هذا النوع من واجهات المستخدم الصوتية من أفضل أجزاء واجهات المستخدم الصوتية - الطبيعية والسرعة وسهولة الاستخدام - ولكن لا تعاني من الأجزاء السيئة - وادي غريب وتفاعلات متسلسلة
لنفكر في هذا البديل.
بديل أفضل لـ Voice Assistant
الحل للتغلب على هذه المشاكل في المساعدين الصوتيين هو التخلي عن الاستجابات اللغوية الطبيعية واستبدالها بملاحظات بصرية في الوقت الفعلي. إن تبديل التعليقات إلى المرئية سيمكن المستخدم من تقديم الملاحظات والحصول عليها في وقت واحد. سيمكن هذا التطبيق من التفاعل دون مقاطعة المستخدم وتمكين تدفق المعلومات ثنائي الاتجاه. نظرًا لأن تدفق المعلومات ثنائي الاتجاه ، يكون معدل نقله أكبر.
حاليًا ، تتمثل أهم حالات الاستخدام للمساعدين الصوتيين في ضبط المنبهات وتشغيل الموسيقى والتحقق من الطقس وطرح أسئلة بسيطة. كل هذه مهام منخفضة المخاطر ولا تحبط المستخدم كثيرًا عند الفشل.
كما كتب ديفيد بيرس من صحيفة وول ستريت جورنال ذات مرة:
"لا يمكنني تخيل حجز رحلة طيران أو إدارة ميزانيتي من خلال مساعد صوتي ، أو تتبع نظامي الغذائي عن طريق الصراخ بالمكونات على مكبرات الصوت الخاصة بي."
- ديفيد بيرس من وول ستريت جورنال
هذه مهام مليئة بالمعلومات ويجب أن تسير بشكل صحيح.
ومع ذلك ، في النهاية ، ستفشل واجهة المستخدم الصوتية. المفتاح هو تغطية هذا بأسرع ما يمكن. تحدث الكثير من الأخطاء عند الكتابة على لوحة المفاتيح أو حتى في محادثة وجهًا لوجه. ومع ذلك ، هذا ليس محبطًا على الإطلاق حيث يمكن للمستخدم التعافي ببساطة عن طريق النقر فوق مسافة للخلف والمحاولة مرة أخرى أو طلب التوضيح.
يتيح هذا الاسترداد السريع من الأخطاء للمستخدم أن يكون أكثر كفاءة ولا يجبره على الدخول في محادثة غريبة مع أحد المساعدين.
تفاعلات صوتية مباشرة
في معظم التطبيقات ، يتم تنفيذ الإجراءات من خلال معالجة العناصر الرسومية على الشاشة ، من خلال النقر أو الضرب (على شاشات اللمس) ، والنقر بالماوس ، و / أو الضغط على الأزرار الموجودة على لوحة المفاتيح. يمكن إضافة الإدخال الصوتي كخيار أو طريقة إضافية لمعالجة هذه العناصر الرسومية. يمكن أن يسمى هذا النوع من التفاعل تفاعل صوتي مباشر .
يتمثل الاختلاف بين التفاعلات الصوتية المباشرة والمساعدين في أنه بدلاً من مطالبة أحد الأشخاص بأداء مهمة ، يقوم المستخدم بمعالجة واجهة المستخدم الرسومية مباشرةً بالصوت.
قد تسأل "أليس هذا دلالات؟" إذا كنت ستتحدث إلى الكمبيوتر ، فهل يهم حقًا إذا كنت تتحدث مباشرة إلى الكمبيوتر أو من خلال شخصية افتراضية؟ في كلتا الحالتين ، أنت تتحدث فقط إلى جهاز كمبيوتر!
نعم ، الفرق دقيق ، لكنه حاسم. عند النقر فوق زر أو عنصر قائمة في واجهة المستخدم الرسومية (واجهة المستخدم الرسومية ) ، فمن الواضح بشكل صارخ أننا نقوم بتشغيل جهاز. لا يوجد وهم لشخص. من خلال استبدال هذا النقر بأمر صوتي ، نقوم بتحسين التفاعل بين الإنسان والحاسوب. مع النموذج المساعد ، من ناحية أخرى ، فإننا نخلق نسخة متدهورة من التفاعل بين الإنسان والإنسان ، وبالتالي ، نسافر إلى الوادي الخارق.
يوفر مزج وظائف الصوت في واجهة المستخدم الرسومية أيضًا إمكانية تسخير قوة الأساليب المختلفة. بينما يمكن للمستخدم استخدام الصوت لتشغيل التطبيق ، إلا أن لديه القدرة على استخدام الواجهة الرسومية التقليدية أيضًا. يتيح ذلك للمستخدم التبديل بين اللمس والصوت بسلاسة واختيار الخيار الأفضل بناءً على السياق والمهمة.
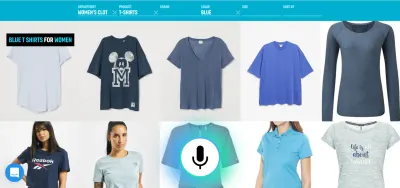
على سبيل المثال ، يعد الصوت طريقة فعالة للغاية لإدخال المعلومات الثرية. الاختيار من بين اثنين من البدائل الصالحة ، اللمس أو النقر هو الأفضل على الأرجح. يمكن للمستخدم بعد ذلك استبدال الكتابة والتصفح بقول شيء مثل ، "اعرض لي الرحلات الجوية من لندن إلى نيويورك المغادرة غدًا" ، وحدد الخيار الأفضل من القائمة باستخدام اللمس.
الآن قد تسأل "حسنًا ، هذا يبدو رائعًا ، فلماذا لم نر أمثلة على واجهات المستخدم الصوتية من قبل؟ لماذا لا تنشئ شركات التكنولوجيا الكبرى أدوات لشيء كهذا؟ " حسنًا ، ربما توجد أسباب كثيرة لذلك. أحد الأسباب هو أن نموذج المساعد الصوتي الحالي ربما يكون أفضل طريقة لهم للاستفادة من البيانات التي يحصلون عليها من المستخدمين النهائيين. سبب آخر يتعلق بالطريقة التي يتم بها بناء تقنية الصوت الخاصة بهم.
تتطلب واجهة المستخدم الصوتية التي تعمل بشكل جيد جزأين متميزين:
- التعرف على الكلام الذي يحول الكلام إلى نص ؛
- مكونات فهم اللغة الطبيعية التي تستخلص المعنى من هذا النص.
الجزء الثاني هو السحر الذي يحول الأقوال "إطفاء أضواء غرفة المعيشة" و "الرجاء إطفاء الأنوار في غرفة المعيشة" إلى نفس الإجراء.
يوصى بالقراءة : كيفية بناء الإجراء الخاص بك لـ Google Home باستخدام API.AI
إذا سبق لك استخدام مساعد بشاشة (مثل Siri أو مساعد Google) ، فمن المحتمل أنك لاحظت أنك تحصل على النص في الوقت الفعلي تقريبًا ، ولكن بعد أن توقفت عن التحدث يستغرق الأمر بضع ثوانٍ قبل النظام يقوم بالفعل بالإجراء الذي طلبته. ويرجع ذلك إلى حدوث كل من التعرف على الكلام وفهم اللغة الطبيعية بشكل متسلسل.
دعونا نرى كيف يمكن تغيير هذا.
فهم اللغة المنطوقة في الوقت الحقيقي: الصلصة السرية لأوامر صوتية أكثر كفاءة
مدى سرعة استجابة التطبيق لإدخال المستخدم هو عامل رئيسي في تجربة المستخدم الكلية للتطبيق. كان أهم ابتكار في جهاز iPhone الأصلي هو شاشة اللمس شديدة الاستجابة والتفاعل. إن قدرة واجهة المستخدم الصوتية على الاستجابة للإدخال الصوتي على الفور هي نفس القدر من الأهمية.
من أجل إنشاء حلقة تبادل معلومات ثنائية الاتجاه سريعة بين المستخدم وواجهة المستخدم ، يجب أن تكون واجهة المستخدم الرسومية الممكّنة بالصوت قادرة على الاستجابة على الفور - حتى في منتصف الجملة - عندما يقول المستخدم شيئًا قابلاً للتنفيذ. هذا يتطلب تقنية تسمى دفق فهم اللغة المنطوقة .
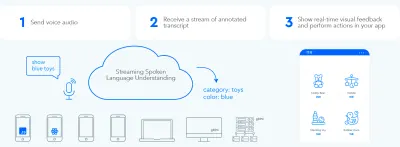
على عكس أنظمة المساعدة الصوتية التقليدية القائمة على الدوران والتي تنتظر حتى يتوقف المستخدم عن التحدث قبل معالجة طلب المستخدم ، تحاول الأنظمة التي تستخدم تدفق فهم اللغة المنطوقة فهم نية المستخدم منذ اللحظة التي يبدأ فيها المستخدم التحدث. بمجرد أن يقول المستخدم شيئًا قابلاً للتنفيذ ، تتفاعل واجهة المستخدم معه على الفور.
تؤكد الاستجابة الفورية على الفور أن النظام يفهم المستخدم وتشجعه على الاستمرار. إنه مشابه للإيماءة أو "الهكتار" القصيرة في التواصل بين البشر. يؤدي هذا إلى دعم أقوال أطول وأكثر تعقيدًا. على التوالي ، إذا لم يفهم النظام المستخدم أو أخطأ المستخدم ، فإن التغذية الراجعة الفورية تتيح الاسترداد السريع . يمكن للمستخدم أن يصحح ويواصل على الفور ، أو حتى أن يصحح نفسه شفهيًا: "أريد هذا ، لا أعني ، أريد ذلك." يمكنك تجربة هذا النوع من التطبيقات بنفسك في عرض البحث الصوتي الخاص بنا.
كما ترى في العرض التوضيحي ، فإن التعليقات المرئية في الوقت الفعلي تمكن المستخدم من تصحيح نفسه بشكل طبيعي وتشجعه على الاستمرار في تجربة الصوت. نظرًا لعدم ارتباكهم من قبل شخصية افتراضية ، فيمكنهم الارتباط بالأخطاء المحتملة بطريقة مشابهة للأخطاء المطبعية - وليس كإهانات شخصية. تكون التجربة أسرع وأكثر طبيعية لأن المعلومات التي يتم تغذيتها للمستخدم لا تقتصر على معدل الكلام المعتاد البالغ حوالي 150 كلمة في الدقيقة.
يوصى بقراءة : تصميم تجارب صوتية بواسطة ليندون سيريجو
الاستنتاجات
في حين أن المساعدين الصوتيين كانوا إلى حد بعيد الاستخدام الأكثر شيوعًا لواجهات المستخدم الصوتية حتى الآن ، فإن استخدام الاستجابات اللغوية الطبيعية يجعلها غير فعالة وغير طبيعية. يعد الصوت طريقة رائعة لإدخال المعلومات ، لكن الاستماع إلى حديث الآلة ليس ملهمًا للغاية. هذه هي القضية الكبيرة للمساعدين الصوتيين.
لذلك لا ينبغي أن يكون مستقبل الصوت في المحادثات مع الكمبيوتر ولكن في استبدال مهام المستخدم الشاقة بأكثر الطرق الطبيعية للتواصل: الكلام . يمكن استخدام التفاعلات الصوتية المباشرة لتحسين تجربة ملء النموذج في تطبيقات الويب أو الأجهزة المحمولة ، لإنشاء تجارب بحث أفضل ، ولتمكين طريقة أكثر فاعلية للتحكم في أحد التطبيقات أو التنقل فيه.
يبحث المصممون ومطورو التطبيقات باستمرار عن طرق لتقليل الاحتكاك في تطبيقاتهم أو مواقعهم الإلكترونية. إن تحسين واجهة المستخدم الرسومية الحالية باستخدام طريقة صوتية من شأنه أن يتيح تفاعلات أسرع عدة مرات للمستخدم خاصة في مواقف معينة مثل عندما يكون المستخدم النهائي على الهاتف المحمول وأثناء التنقل وتكون الكتابة صعبة. في الواقع ، يمكن أن يكون البحث الصوتي أسرع بخمس مرات من واجهة مستخدم تصفية البحث التقليدية ، حتى عند استخدام كمبيوتر سطح المكتب.
في المرة القادمة ، عندما تفكر في كيفية جعل مهمة مستخدم معينة في تطبيقك أسهل في الاستخدام ، أو أكثر متعة في الاستخدام ، أو كنت مهتمًا بزيادة التحويلات ، ففكر في إمكانية وصف مهمة المستخدم هذه بدقة بلغة طبيعية. إذا كانت الإجابة بنعم ، فاستكمل واجهة المستخدم الخاصة بك بطريقة صوتية ولكن لا تجبر المستخدمين لديك على التحدث مع جهاز كمبيوتر.
موارد
- "الصوت أولاً مقابل واجهات المستخدم متعددة الوسائط في المستقبل ،" جوان بالميتر باجوريك ، UXmatters
- "مبادئ توجيهية لإنشاء تطبيقات منتجة تدعم الصوت" ، هانس هيكينهايمو ، سبيكلي
- "6 أسباب تجعل تطبيقات الشاشة التي تعمل باللمس تتمتع بقدرات صوتية ،" Ottomatias Peura ، UXmatters
- المزج الملموس وغير الملموس: تصميم واجهات متعددة الوسائط باستخدام Adobe XD، Nick Babich، Smashing Magazine
( يمكن أن يكون Adobe XD لتصميم نموذج أولي لشيء مشابه ) - "الكفاءة بسرعة الصوت: الوعد بالعمليات التي تدعم الصوت" ، إريك توركينغتون ، راين
- عرض توضيحي يعرض الملاحظات المرئية في الوقت الفعلي في تصفية البحث الصوتي للتجارة الإلكترونية (إصدار الفيديو)
- يوفر Speechly أدوات مطور لهذا النوع من واجهات المستخدم
- بديل مفتوح المصدر: voice2json