
دليل الانحدار الخطي باستخدام Scikit [مع أمثلة]
نشرت: 2021-06-18تتكون خوارزميات التعلم الخاضع للإشراف بشكل عام من نوعين: الانحدار والتصنيف مع التنبؤ بالمخرجات المستمرة والمنفصلة.
ستناقش المقالة التالية الانحدار الخطي وتنفيذه باستخدام واحدة من أكثر مكتبات التعلم الآلي شيوعًا في Python ، وهي مكتبة Scikit-Learn. تتوفر أدوات التعلم الآلي والنماذج الإحصائية في مكتبة Python من أجل التصنيف والانحدار والتكتل وتقليل الأبعاد. تمت كتابة المكتبة بلغة برمجة python ، وهي مبنية على مكتبات Python NumPy و SciPy و Matplotlib.
جدول المحتويات
الانحدارالخطي
يؤدي الانحدار الخطي مهمة الانحدار في ظل أسلوب التعلم الخاضع للإشراف. بناءً على المتغيرات المستقلة ، يتم توقع القيمة المستهدفة. تستخدم الطريقة في الغالب للتنبؤ وتحديد العلاقة بين المتغيرات.
في الجبر ، مصطلح الخطية يعني علاقة خطية بين المتغيرات. يتم استنتاج خط مستقيم بين المتغيرات في فضاء ثنائي الأبعاد.
إذا كان الخط عبارة عن رسم بياني بين المتغيرات المستقلة على المحور X والمتغيرات التابعة على المحور Y ، يتم تحقيق خط مستقيم من خلال الانحدار الخطي الذي يناسب نقاط البيانات بشكل أفضل.
تكون معادلة الخط المستقيم على هيئة

ص = م س + ب
أين ، ب = اعتراض
م = ميل الخط
لذلك ، من خلال الانحدار الخطي ،
- يتم تحديد القيم المثلى للاعتراض والمنحدر في بعدين.
- لا يوجد أي تغيير في متغيري x و y لأنهما يمثلان ميزات البيانات وبالتالي يظلان كما هو.
- يمكن التحكم فقط في قيم التقاطع والانحدار.
- قد توجد خطوط مستقيمة متعددة بناءً على قيم الانحدار والتقاطع ، ولكن من خلال خوارزمية الانحدار الخطي يتم تركيب خطوط متعددة على نقاط البيانات ويتم إرجاع الخط الذي يحتوي على أقل خطأ.
الانحدار الخطي مع بايثون
لتنفيذ الانحدار الخطي في Python ، يجب تطبيق الحزم المناسبة جنبًا إلى جنب مع وظائفها وفئاتها. تعد الحزمة NumPy في Python مفتوحة المصدر وتسمح بعدة عمليات على المصفوفات ، سواء المصفوفة الفردية أو متعددة الأبعاد.
مكتبة أخرى مستخدمة على نطاق واسع في Python هي Scikit-Learn والتي تستخدم لمشاكل التعلم الآلي.
سكيكيت ليرن
تقدم مكتبة Scikit-Learn للمطورين خوارزميات تعتمد على التعلم الخاضع للإشراف وغير الخاضع للإشراف. تم تصميم مكتبة Python مفتوحة المصدر لمهام التعلم الآلي.
يمكن لعلماء البيانات استيراد البيانات ومعالجتها مسبقًا ورسمها والتنبؤ بالبيانات من خلال استخدام scikit-Learn.
قام ديفيد كورنابو بتطوير برنامج scikit-Learn لأول مرة في عام 2007 ، وشهدت المكتبة نموًا منذ عقود.
الأدوات التي يوفرها scikit-Learn هي:
- الانحدار: ويشمل الانحدار اللوجستي والانحدار الخطي
- التصنيف: يشمل طريقة K- أقرب الجيران
- اختيار النموذج
- التجميع: يشمل كلاً من K-Means ++ و K-Means
- المعالجة
مزايا المكتبة هي:
- التعلم والتنفيذ للمكتبة سهل.
- إنها مكتبة مفتوحة المصدر وبالتالي فهي مجانية.
- يمكن التستر على جوانب التعلم الآلي بما في ذلك التعلم العميق.
- إنها حزمة قوية ومتعددة الاستخدامات.
- المكتبة لديها وثائق مفصلة.
- إحدى مجموعات الأدوات الأكثر استخدامًا للتعلم الآلي.
استيراد scikit-learn
يجب تثبيت برنامج scikit-Learn أولاً من خلال النقطة أو من خلال Conda.
- المتطلبات: إصدار 64 بت من python 3 مع مكتبات مثبتة NumPy و Scipy. أيضا لتصور مخطط البيانات ، مطلوب matplotlib.
أمر التثبيت: pip install -U scikit-learn
ثم تحقق مما إذا كان التثبيت قد اكتمل
تركيب Numpy و Scipy و matplotlib
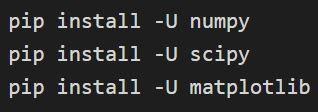
يمكن تأكيد التثبيت من خلال:
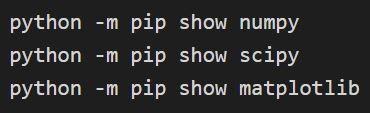
مصدر
الانحدار الخطي من خلال Scikit-Learn
تنفيذ الانحدار الخطي من خلال الحزمة scikit-Learn يتضمن الخطوات التالية.
- الحزم والفئات المطلوبة ليتم استيرادها.
- البيانات مطلوبة للعمل معها وكذلك لتنفيذ التحولات المناسبة.
- يجب إنشاء نموذج الانحدار وتزويده بالبيانات الموجودة.
- يجب التحقق من بيانات ملاءمة النموذج لتحليل ما إذا كان النموذج الذي تم إنشاؤه مرضيًا.
- يتم التنبؤ من خلال تطبيق النموذج.
سيتم استيراد الحزمة NumPy والفئة LinearRegression من sklearn.linear_model.

مصدر
جميع الوظائف المطلوبة للانحدار الخطي sklearn موجودة لتنفيذ الانحدار الخطي في النهاية. تُستخدم فئة sklearn.linear_model.LinearRegression لإجراء تحليل الانحدار (الخطي ومتعدد الحدود) وتنفيذ التنبؤات.
لأي خوارزميات التعلم الآلي و scikit Learn الانحدار الخطي ، يجب استيراد مجموعة البيانات أولاً. تتوفر ثلاثة خيارات في Scikit-Learn للحصول على البيانات:
- مجموعات البيانات مثل تصنيف قزحية العين أو مجموعة الانحدار لسعر الإسكان في بوسطن.
- يمكن تنزيل مجموعات بيانات العالم الحقيقي من الإنترنت مباشرة من خلال وظائف Scikit-Learn المحددة مسبقًا.
- يمكن إنشاء مجموعة بيانات بشكل عشوائي للمطابقة مع نمط معين من خلال منشئ بيانات Scikit-Learn.
مهما كان الخيار المحدد ، يجب استيراد مجموعات بيانات الوحدة النمطية.

استيراد مجموعات sklearn.datasets كمجموعات بيانات
1. مجموعة تصنيف القزحية
iris = datasets.load_iris ()
يتم تخزين قزحية مجموعة البيانات كحقل بيانات مصفوفة ثنائية الأبعاد لـ n_samples * n_features. يتم استيراده ككائن في القاموس. يحتوي على جميع البيانات الضرورية مع البيانات الوصفية.
يمكن استخدام وظائف DESCR والشكل والأسماء للحصول على أوصاف البيانات وتنسيقها. ستعرض طباعة نتائج الوظائف معلومات مجموعة البيانات التي قد تكون مطلوبة أثناء العمل على مجموعة بيانات قزحية العين.
سيُحمِّل الكود التالي معلومات مجموعة بيانات قزحية العين.
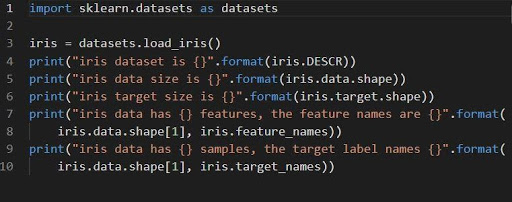
مصدر
2. توليد بيانات الانحدار
إذا لم تكن هناك حاجة للبيانات المضمنة ، فيمكن إنشاء البيانات من خلال التوزيع الذي يمكن اختياره.
توليد بيانات الانحدار بمجموعة من ميزة إعلامية واحدة وميزة واحدة.
X ، Y = مجموعات البيانات. جعل التسجيل (n_features = 1 ، n_informative = 1)
يتم حفظ البيانات التي تم إنشاؤها في مجموعة بيانات ثنائية الأبعاد مع الكائنين x و y. يمكن تغيير خصائص البيانات المولدة من خلال تغيير معلمات الوظيفة make_regression.
في هذا المثال ، تم تغيير معلمات الميزات والميزات المعلوماتية من القيمة الافتراضية من 10 إلى 1.
المعلمات الأخرى التي تم أخذها في الاعتبار هي العينات والأهداف حيث يتم التحكم في عدد متغيرات الهدف والعينة التي يتم تتبعها.
- يشار إلى الميزات التي توفر معلومات مفيدة لخوارزميات ML على أنها ميزات إعلامية بينما يشار إلى الميزات غير المفيدة على أنها ميزات إعلامية.
3. رسم البيانات
يتم رسم البيانات باستخدام مكتبة matplotlib. أولاً ، يجب استيراد matplotlib.
استيراد matplotlib.pyplot كـ plt
يتم رسم الرسم البياني أعلاه من خلال matplotlib من خلال الكود
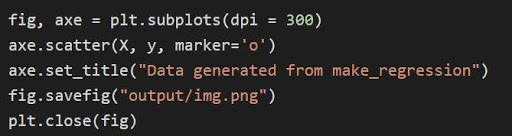
مصدر
في الكود أعلاه:
- يتم فك حزم متغيرات tuple وحفظها كمتغيرات منفصلة في السطر الأول من الكود. لذلك ، يمكن التلاعب بالسمات المنفصلة وحفظها.
- تُستخدم مجموعة البيانات x ، y لإنشاء مخطط مبعثر عبر السطر 2. مع توفر معلمة العلامة في matplotlib ، يتم تحسين المرئيات عن طريق تمييز نقاط البيانات بنقطة (o).
- يتم تعيين عنوان قطعة الأرض التي تم إنشاؤها من خلال السطر 3.
- يمكن حفظ الرقم كملف صورة بتنسيق .png ثم يتم إغلاق الشكل الحالي.
مخطط الانحدار الذي تم إنشاؤه من خلال الكود أعلاه هو
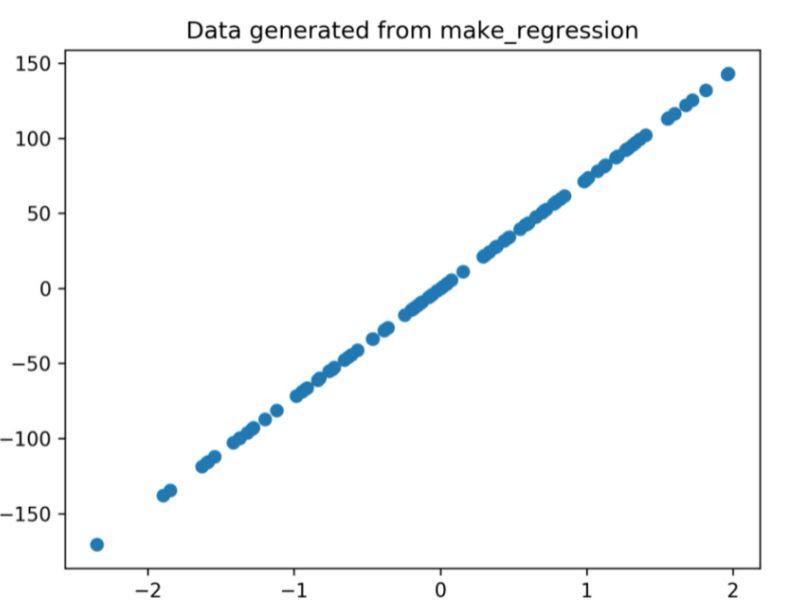
الشكل 1: مخطط الانحدار الناتج عن الكود أعلاه.
4. تطبيق خوارزمية الانحدار الخطي
باستخدام بيانات نموذجية لسعر سكن بوسطن ، يتم تنفيذ خوارزمية الانحدار الخطي Scikit-Learn في المثال التالي. مثل خوارزميات ML الأخرى ، يتم استيراد مجموعة البيانات ثم تدريبها باستخدام البيانات السابقة.
يتم استخدام طريقة الانحدار الخطي من قبل الشركات ، حيث إنها نموذج تنبؤي يتنبأ بالعلاقة بين الكمية العددية ومتغيراتها إلى قيمة المخرجات بمعنى وجود قيمة في الواقع.
عند وجود سجل للبيانات السابقة ، يمكن تطبيق النموذج بشكل أفضل لأنه يمكن أن يتنبأ بالنتائج المستقبلية لما سيحدث في المستقبل إذا كان هناك استمرار للنمط.
رياضياً ، يمكن تجهيز البيانات لتقليل مجموع جميع المخلفات الموجودة بين نقاط البيانات والقيمة المتوقعة.
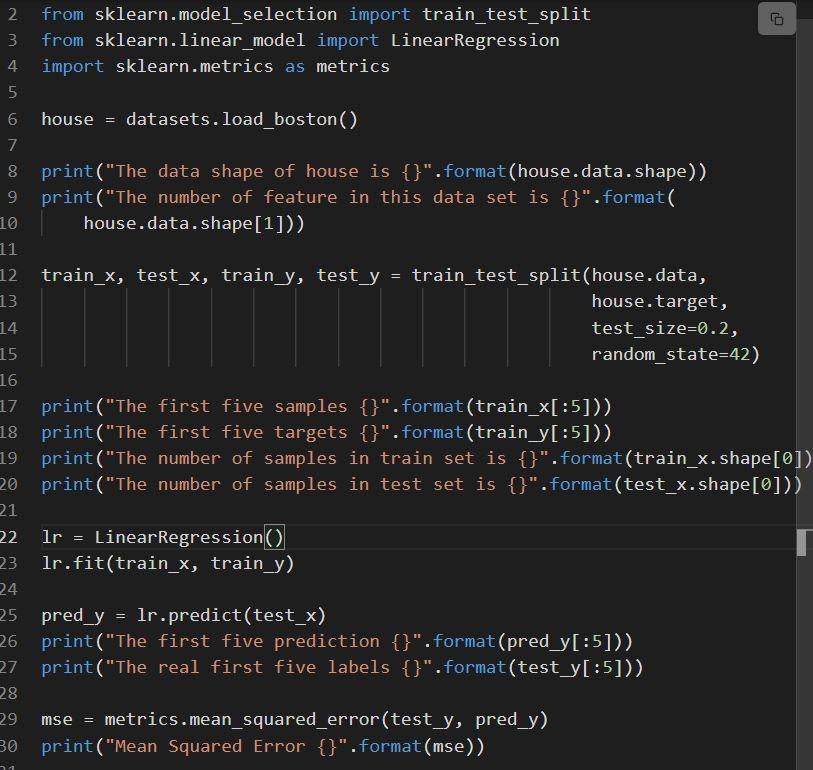
يوضح المقتطف التالي تنفيذ الانحدار الخطي sklearn.
مصدر
يتم شرح الكود على النحو التالي:
- يقوم السطر 6 بتحميل مجموعة البيانات المسماة load_boston.
- يتم تقسيم مجموعة البيانات في السطر 12 ، أي مجموعة التدريب مع 80٪ من البيانات ومجموعة الاختبار مع 20٪ من البيانات.
- إنشاء نموذج للانحدار الخطي عند السطر 23 ومن ثم تدريبه عند.
- يتم تقييم أداء النموذج في الكتان 29 من خلال استدعاء mean_squared_error.
يظهر مخطط الانحدار الخطي sklearn أدناه:
نموذج الانحدار الخطي لبيانات عينة أسعار المساكن في بوسطن
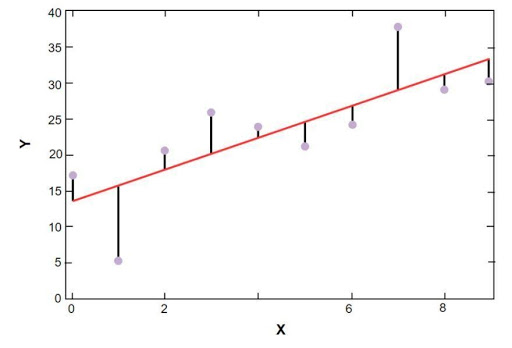
مصدر
في الشكل أعلاه ، يمثل الخط الأحمر النموذج الخطي الذي تم حله لبيانات عينة لسعر الإسكان في بوسطن. تمثل النقاط الزرقاء البيانات الأصلية وتمثل المسافة بين الخط الأحمر والنقاط الزرقاء مجموع المتبقي. الهدف من نموذج الانحدار الخطي scikit-Learn هو تقليل مجموع القيم المتبقية.
خاتمة
ناقش المقال الانحدار الخطي وتنفيذه من خلال استخدام حزمة بايثون مفتوحة المصدر تسمى scikit-Learn. الآن ، يمكنك الحصول على مفهوم كيفية تنفيذ الانحدار الخطي من خلال هذه الحزمة. يجدر تعلم كيفية استخدام المكتبة لتحليل البيانات الخاصة بك.
إذا كنت مهتمًا باستكشاف الموضوع بشكل أكبر ، مثل تنفيذ حزم Python في التعلم الآلي والمشكلات المتعلقة بالذكاء الاصطناعي ، فيمكنك التحقق من دورة ماجستير العلوم في التعلم الآلي والذكاء الاصطناعي التي تقدمها upGrad . تستهدف الدورة المهنيين المبتدئين من 21 إلى 45 عامًا ، وتهدف الدورة إلى تدريب الطلاب على التعلم الآلي من خلال التدريب عبر الإنترنت لمدة تزيد عن 650 ساعة ، وأكثر من 25 دراسة حالة ، ومهام. تقدم الدورة المعتمدة من جامعة جون مورس بليفربول ، التوجيه المثالي والمساعدة في التوظيف. إذا كان لديك أي أسئلة أو استفسارات ، فاترك لنا رسالة ، وسنكون سعداء بالتواصل معك.